
7 MySQL
source: categories/study/nodejs/nodejs7.md
7.1 MySQL 설치하기
지금까지 실습은 데이터를 서버 메모리상에 저장했었기 때문에 서버를 종료하면 데이터들이 다 유실되었습니다.
실제 서비스에서는 데이터들이 유지가 되어야하는데 그럼 데이터를 어디에 저장해야될지를 생각을 해봐야되잖아요?
그래서 기본적으로 몇가지 가능성이 있는데
- 클라이언트 파일에 데이터 저장하기
브라우저로 따지면 로컬 스토리지, 세션 스토리지..
브라우저에서도 스토리지들을 제공하기 때문에 이런곳에 저장할 수 있는데, 이런 곳에 저장하는 데이터는 한가지 위험성이 있습니다.
클라이언트의 데이터를 저장하면 클라이언트가 그 데이터를 위조하는 순간 서버가 그 데이터가 진짜인지 위조된 것인지 판단을 할 수가 없습니다.
그래서 보통 보안에 제약이 없는, 보안에 위협되지 않는 데이터들을 보통 클라이언트에 두는 경우가 많고
보안 체크를 해야되는 데이터들은 서버에 두는 경우가 많습니다.
서버에 파일로 둬도 되고 데이터베이스 매니지먼트 시스템이라는 데이터베이스 관리하는 시스템에 두기도 합니다.
7.1.1 데이터베이스
데이터베이스란
-
지금까지는 데이터를 서버 메모리에 저장했음
- 서버를 재시작하면 데이터도 사라져버림, -> 영구적으로 저장할 공간 필요
-
MySQL 관계형 데이터베이스 사용
- 데이터베이스: 관련성을 가지며 중복이 없는 데이터들의 집합
- DBMS: 데이터베이스를 관리하는 시스템
- RDBMS: 관계형 데이터베이스를 관리하는 시스템
- 서버의 하드디스크나 SSD 등의 저장 매체에 데이터를 저장
- 서버 종료 여부와 상관 없이 데이터를 계속 사용할 수 있음
-
여러 사람이 동시에 접근할 수 있고, 권한을 따로 줄 수 있음

그 중에서 MySQL을 배워보도록 하겠습니다.
클라이언트 스토리지에 데이터를 두는 이유
서버에 모든 데이터를 두면 서버가 무거워짐.
그래서 서버 비용이 많이 나가기 때문에 클라이언트에 둬도되는 데이터들은 최대한 클라이언트로 보내는게 비용상으로도 효율적임.
데이터베이스 구분 SQL, NoSQL
크게 SQL과 NoSQL로 구분할 수 있다.
-
SQL은 보통 관계형 데이터베이스라고 함.
데이터베이스에 들어있는 데이터들간 관계가 있는 거임.
예를들어 사용자, 게시글, 댓글이 있으면 사용자가 게시글을 쓴다, 댓글을 쓴다, 게시글에 댓글이 달려있다, 이런 관계들이 있죠?
그런 관계들을 많이 띄고 있는 데이터들은 이런 관계형 데이터베이스에 많이 저장을 합니다. -
비관계형, NoSQL
이런 것들은 언제쓰냐. 로그 같은 것들이 있습니다.
물론 단순히 로그 말고도 다양한 활용방법들이 있는데 보통 데이터를 구조적으로 정리하기 쉽지않은?
엑셀 같은 경우는 관계형 데이터베이스에 넣기 좋음. 이런게 정형 데이터.
이러한 정형 데이터들은 다른 것과 관계를 갖기 쉬운데
예를 들어 인공지능이 수집하는 인공지능 학습시킬 때 사용하는 채팅 데이터나 아니면 검색 결과 이런 것들은 어떤 규칙이 있는게 아니라 그때그때 데이터들이 어떻게 들어올지 모르잖아요?
그런것들은 오히려 정해진 틀을 만들어놓으면 그 틀에 데이터들이 안 맞아서 문제가 생김.
그래서 어떤 형식의 데이터가 들어오던지 다 받아들이는게NoSQL. - 데이터간 관계가 있다 -> SQL
- 데이터간 관계 파악도 어렵고 일단은 수집하는데 목적이 있다 -> NoSQL
MySQL
저희는 SQL 중에 MySQL을 공부.
SQL 중에 유명한게 오라클, MsSQL, MySQL 등이 있음.
7.1.2 MySQL, 워크벤치 설치하기
-
- 용량작은거나 큰거나 큰 차이는 없음, 작은거 받아도 어차피 추가적으로 더 받음.
다운로드 및 설치
음? 난 비밀번호 설정 화면 안나왔는데.. 뭐지..
아래 화면 안 나왔는데..
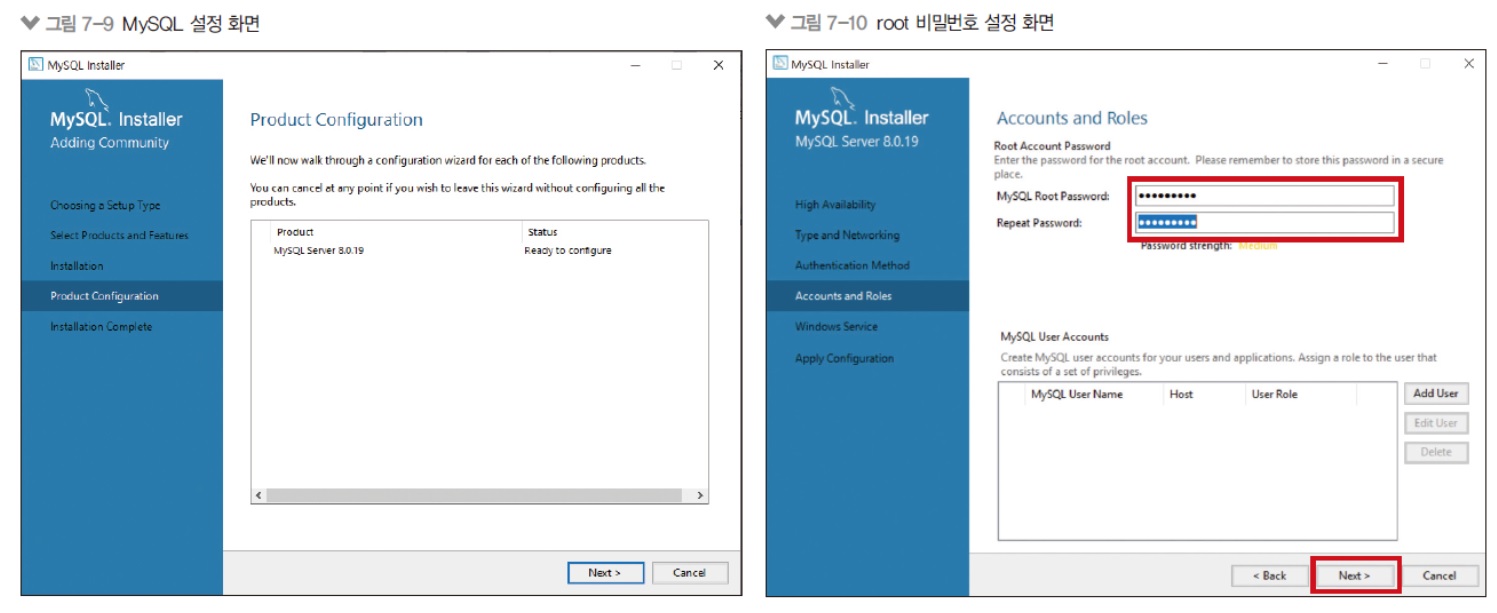
위 화면도 안나옴.. 음…?
설치할 때 경로에 한글이 있었나..? 없는데..
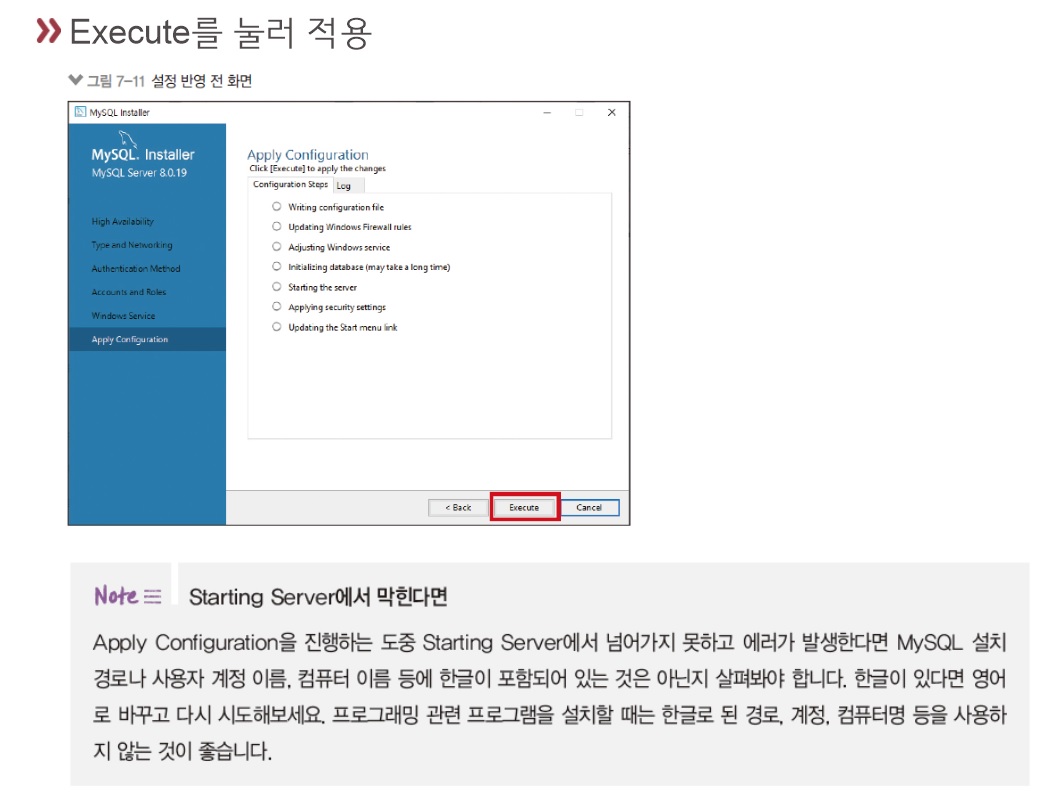
설정 해결
-
인스톨러 다시 실행해서 재설정 누른 후
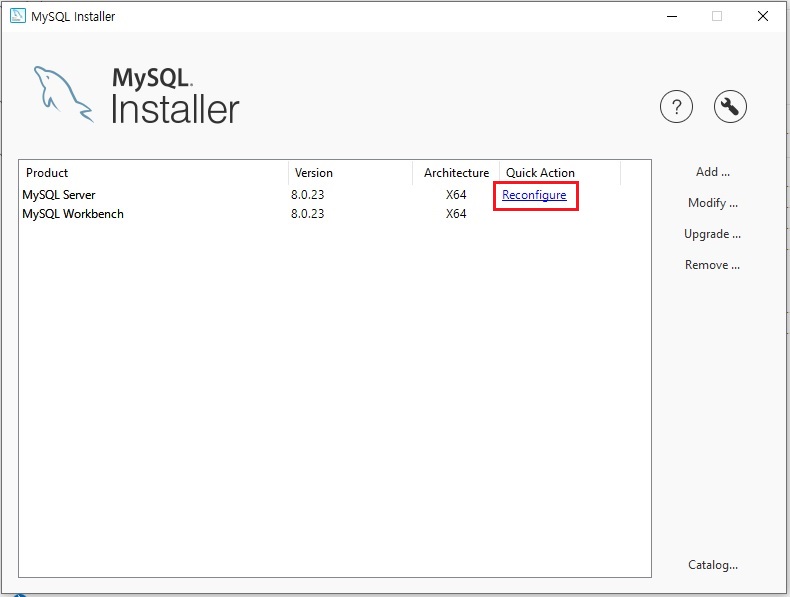
-
비밀번호 설정
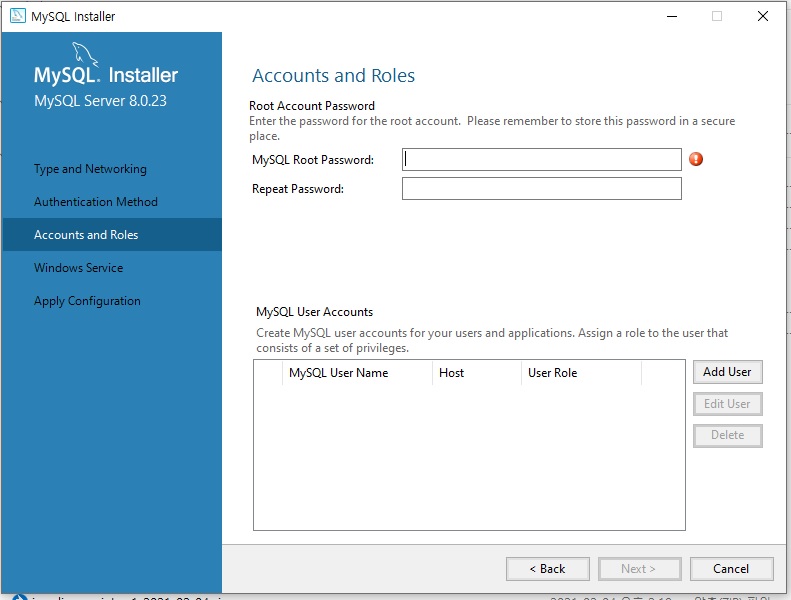
이렇게 다시 설정을 완료하면 된다.
설치가 완료됐다면
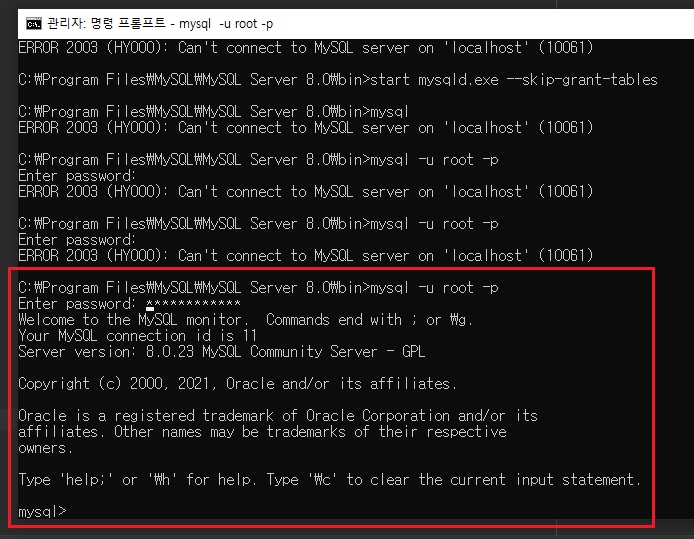
위와 같이 mysql이 실행된다.
-
콘솔(CMD)에서 MySQL이 설치된 경로로 이동
- 기본 경로는
C:\Program Files\MySQL\MySQL Server 8.0\bin -
-h는 호스트,-u는 사용자-p는 비밀번호 의미mysql -h localhost -u root -p-h localhost는 생략 가능. 기본값이라서.
위 명령어 입력 후 위에서 설정한 비밀번호 입력하면 됨. - 프롬프트가
mysql>로 바뀐다면 성공 - 프롬프트를 종료하려면
exit입력 (비밀번호 까먹었는데.. 어떻게해야되지..? 인터넷에 찾은 방법으로하니깐 안되는데.. 이건 따로 알아봐야겠네)
- 기본 경로는
-
mysql 실행
c:\>이 경로에서
mysql이 실행되게하려면 환경변수로mysql이 설치된 경로를 등록해두셔야되고 그렇지 않은 경우엔 mysql이 설치된 경로로 들어가셔서 실행하셔야됩니다. -
여튼 위와 같이 mysql을 실행하면 이를 mysql 프롬프트라고 부릅니다.
macOS
-
홈브루(homebrew)를 통해 설치하는게 편함
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" -
brew 설치 후 MySQL 설치
brew install mysql brew services start mysql mysql_secure_installation -
root 비밀번호 설정 후, validate_password 플러그인을 설치하겠냐고 물으면 모두 n을 입력하고 엔터를 눌러 건너 뜀
- 실서버 운영시에는 설정해주는 것이 좋음
- 윈도와 같은 방법으로 MySQL에 접속
macOS 워크밴치 설치
-
Homebrew로 다운로드
brew cask install mysqlworkbench
윈도에선 mysql 설치시 워크벤치 같이 설치했음.
macOS에선 따로 설치해줘야됨.
리눅스(우분투)에 MySQL 설치
-
GUI를 사용하지 않으므로 콘솔에 다음 명령어를 순서대로 입력
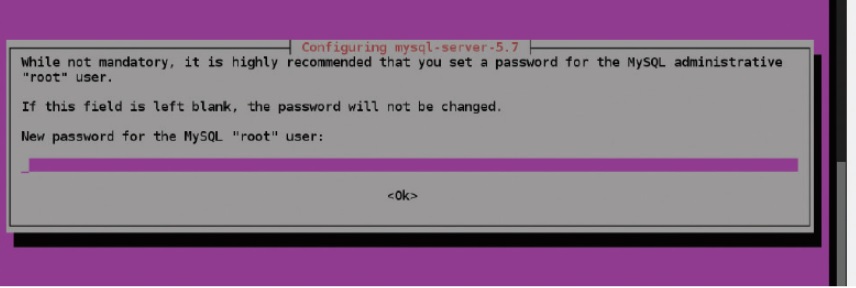
sudo apt-get update sudo apt-get install -y mysql-server mysql_secure_installation -
root 비밀번호 설정
- 윈도와 같은 방법으로 mysql에 접속
- 우분투의 경우는 워크벤치 대신 콘솔에서 작업
7.1.3 윈도, 맥 워크벤치에서 커넥션 생성
- 워크벤치 프로그램 실행
-
MySQL Connections 옆에 + 모양 클릭
저희가 MySQL에 저장되어있는 데이터들을 콘솔창에서 불러올 수 있거든요? 위와 같이.
이렇게 직접 입력해서 찾을 수도 있는데 초보분들은 SQL 언어로 작성하시는게 부담스러울 수도 있어서 워크벤치 사용.
MySQL 서버 주소 입력
-
Connection Name에 localhost 적고 비밀번호도 설정할 수 있습니다.
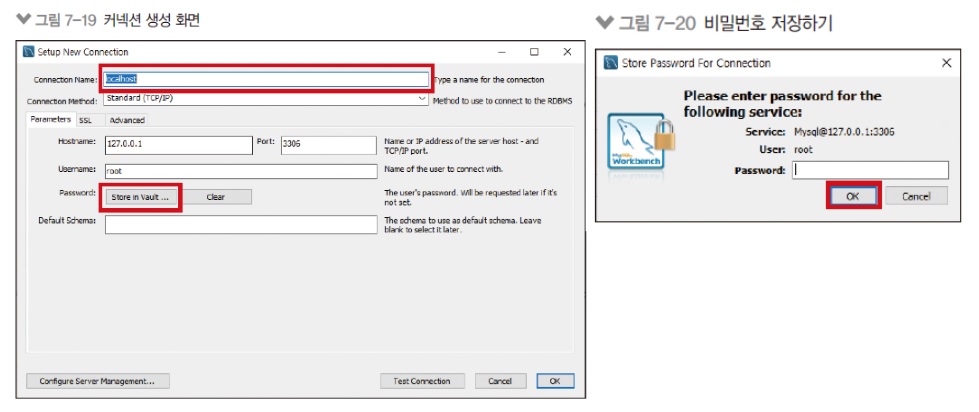
위와 같이 비밀번호까지 설정하고 싶으면 하시면 되는데, 저는 보안상 매번 입력합니다.
(아 이거 설치 때 입력했던 비밀번호 입력하는건가 보네.. 음.. 똑같은 비밀번호 입력했는데 생성이 안되네.. 아직 잘 모르겠다 MySQL에 대해..) -
여튼 워크벤치 실행
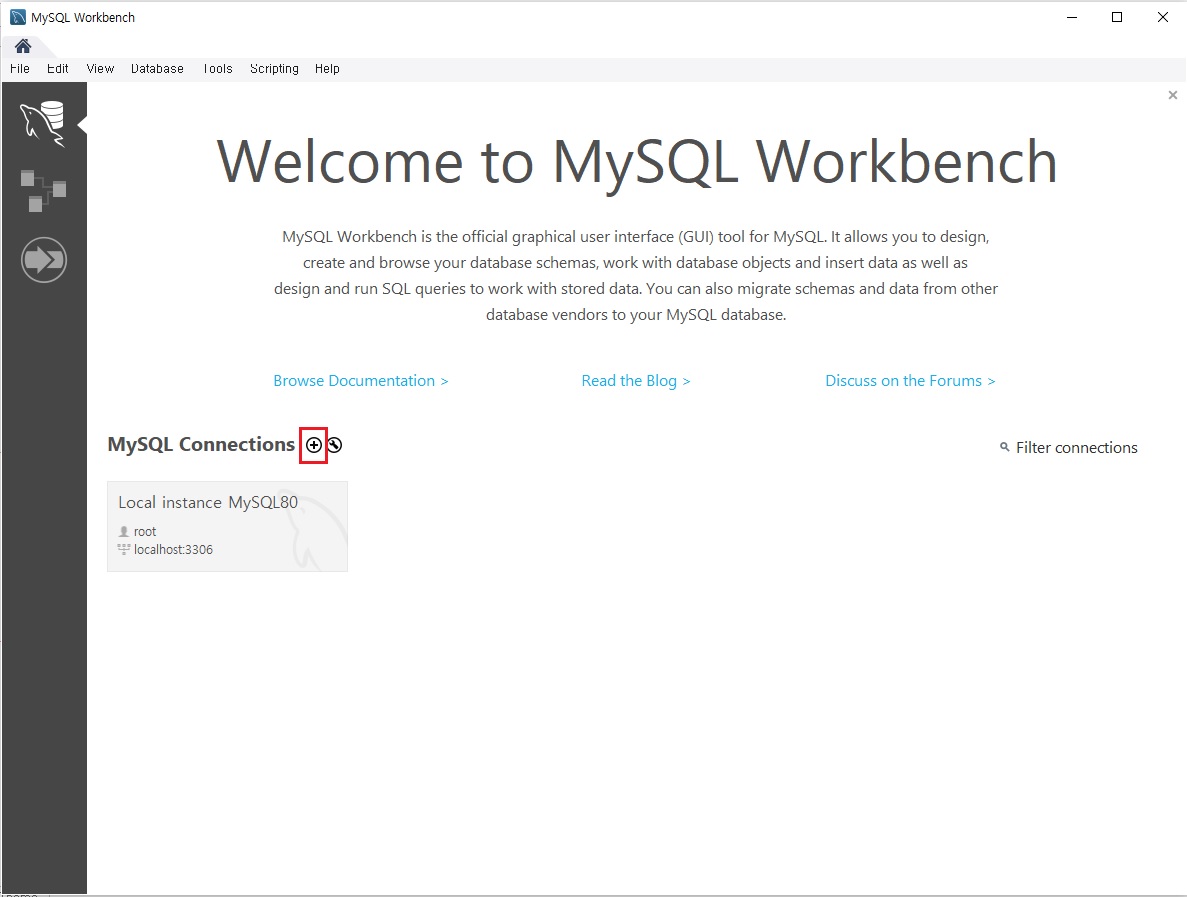
이렇게 워크벤치를 통해 하시는게 편합니다.
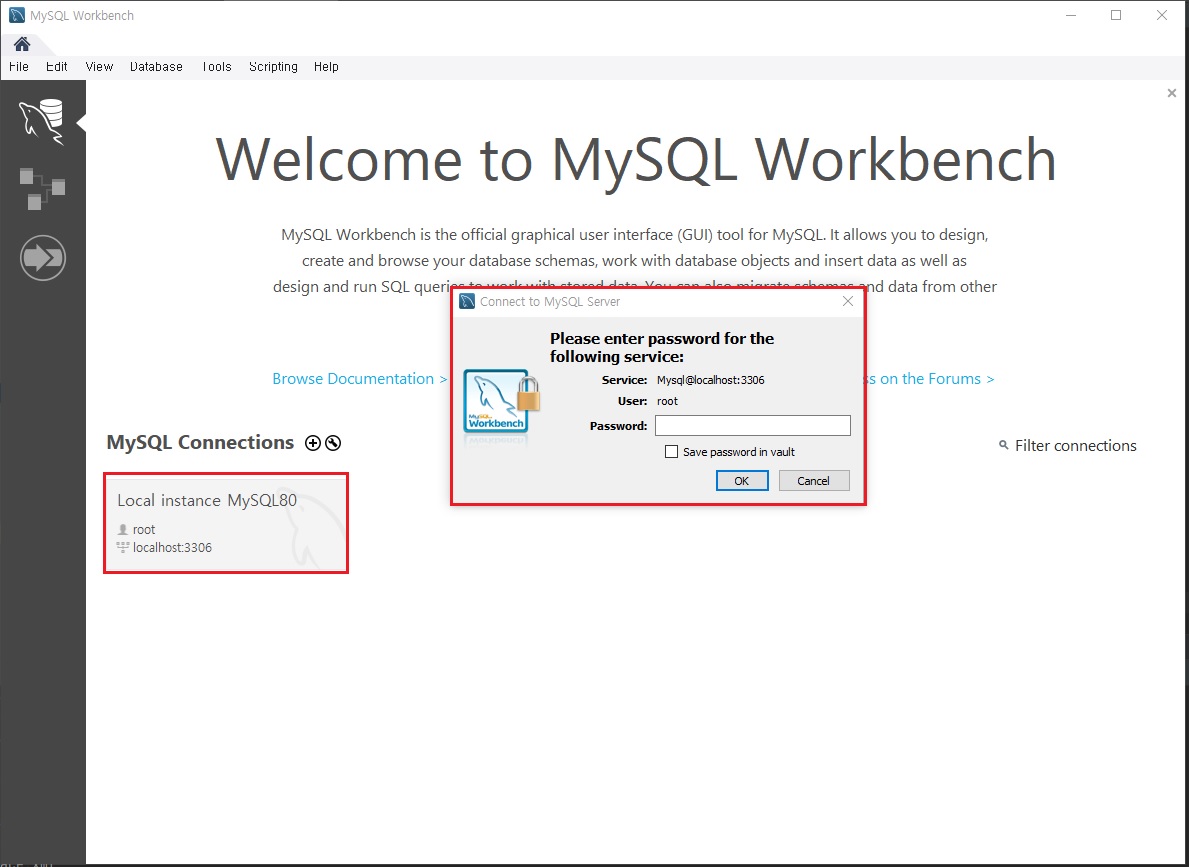
MySQL은 기본적으로 3306 포트번호에서 돌아갑니다.
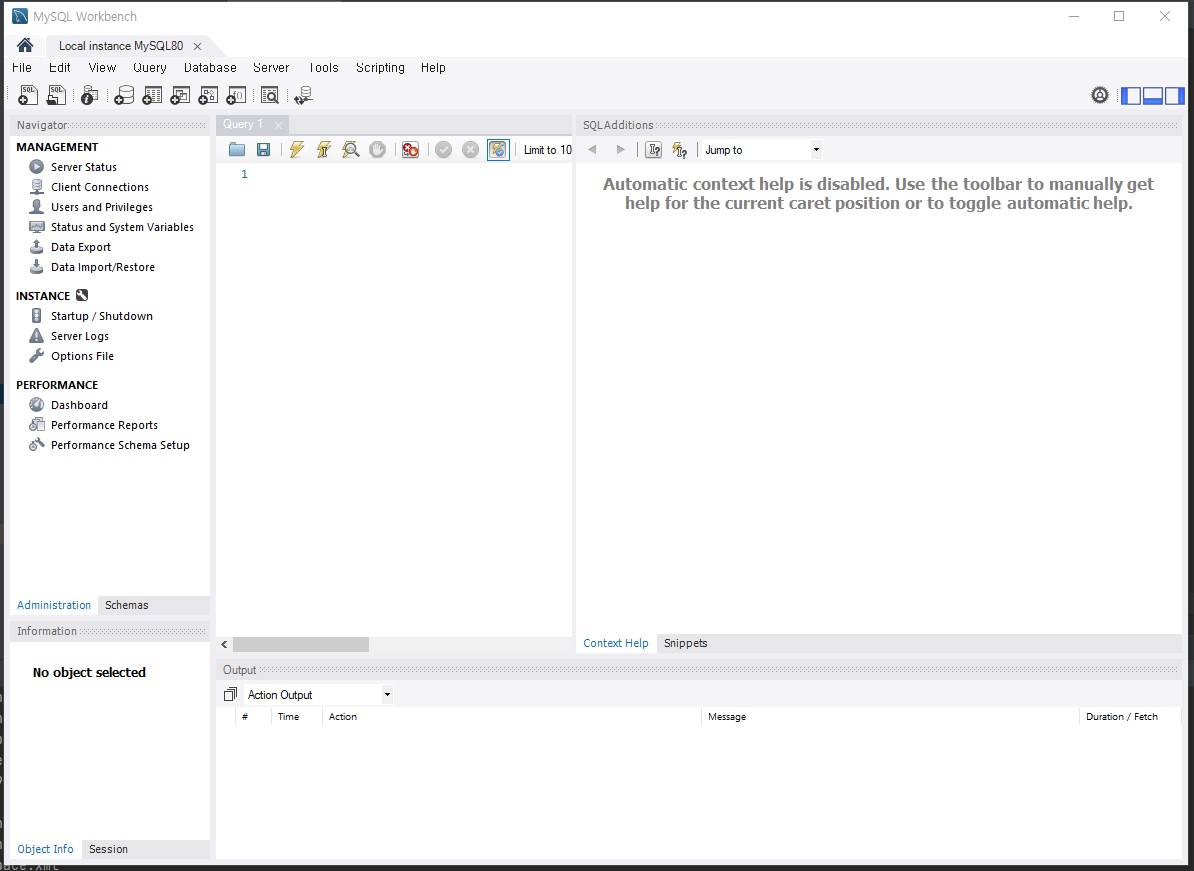
위에서 설치할 때 설정한 비밀번호를 입력하고 접속하시면 위와 같이 시각적으로 데이터들을 보실 수 있게됩니다.
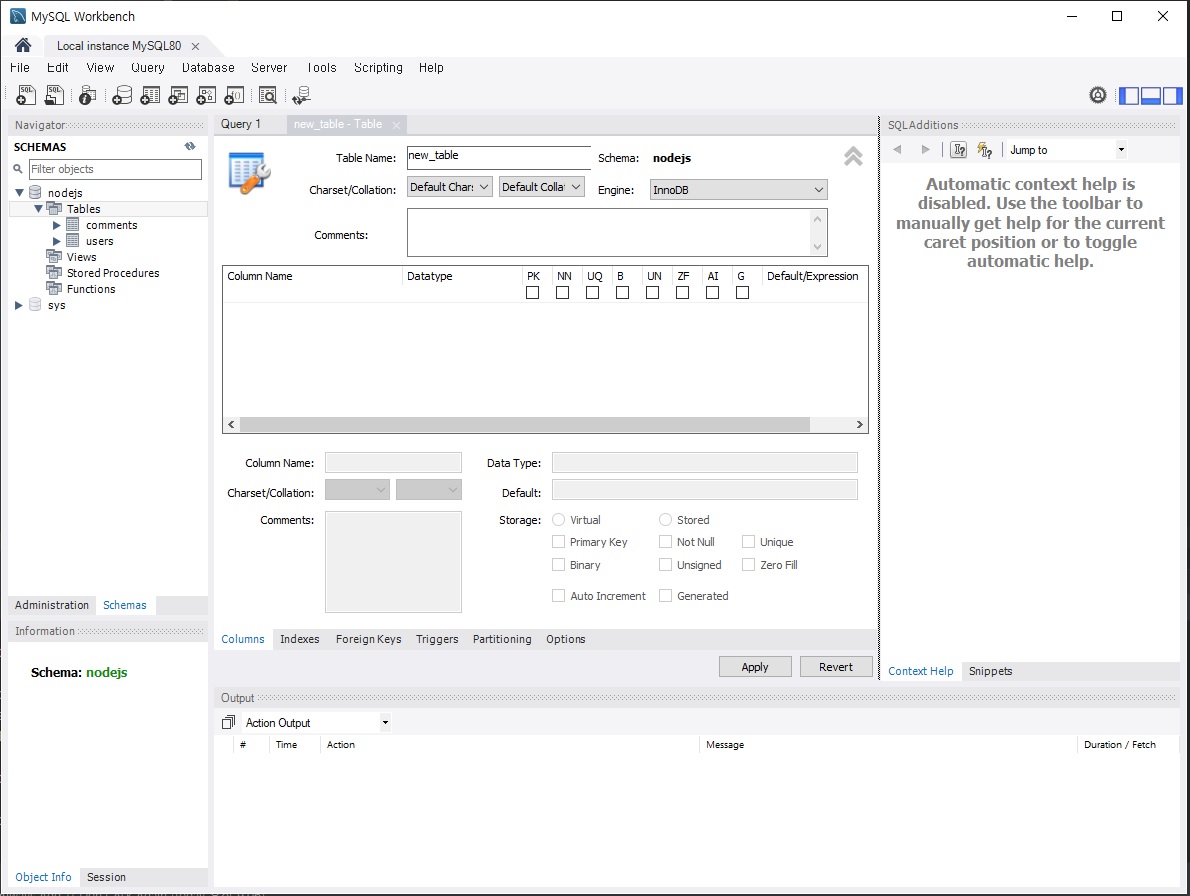
7.2 테이블 만들기
7.2.1 데이터베이스 생성하기
-
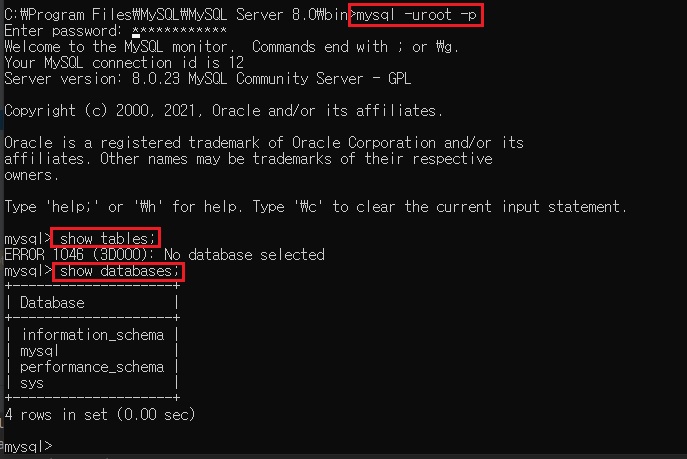
콘솔에서 MySQL 프롬프트에 접속
-
CREATE SCHEMA nodejs;로 nodejs 데이터베이스 생성
CREATE SCHEMA nodejs;이런 것들이 SQL임.
SQL도 Query Language이기 때문에 다른 언어, 문법이라고 생각하시면 됨.
그래서 SQL 언어를 배우셔야함. -
use nodejs;로 생성한 데이터베이스 선택mysql> CREATE SCHEMA `nodejs` DEFAULT CHARACTER SET utf8; mysql> use nodejs;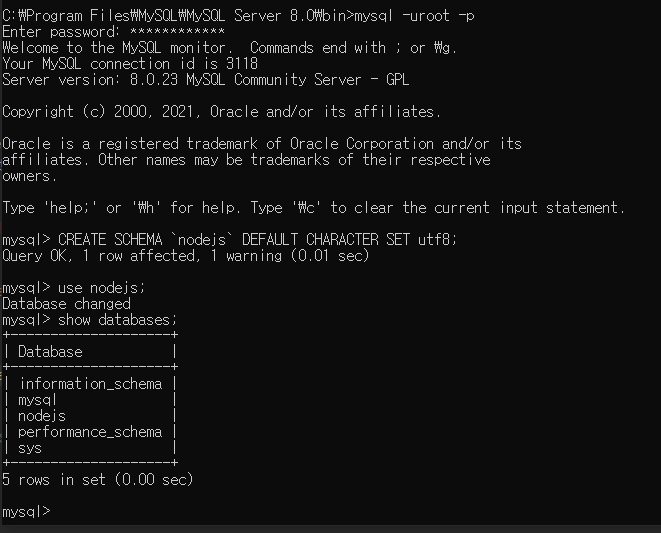
이렇게 입력하시면 됩니다.
그럼show databases;명령어를 치면nodejs가 보이실 거고, 그러면use nodejs;명령어를 입력하시면 됩니다.
위 명령어를 입력하시면nodejs SCHEMA(스키마)가 생기는데 스키마와 데이터베이스는 SQL에서 같은 뜻이라고 생각하시면 됩니다.여튼 위와 같이 하시면 데이터베이스가 만들어지고 이거는 하나의 서비스라고 보시면 됩니다.
여러분들이 어떤 서비스를 만들 때, 데이터베이스도 하나의 스키마, 하나의 데이터베이스를 만든다고 생각하시면되고 데이터베이스를 만든 다음엔 테이블을 생성합니다.
-
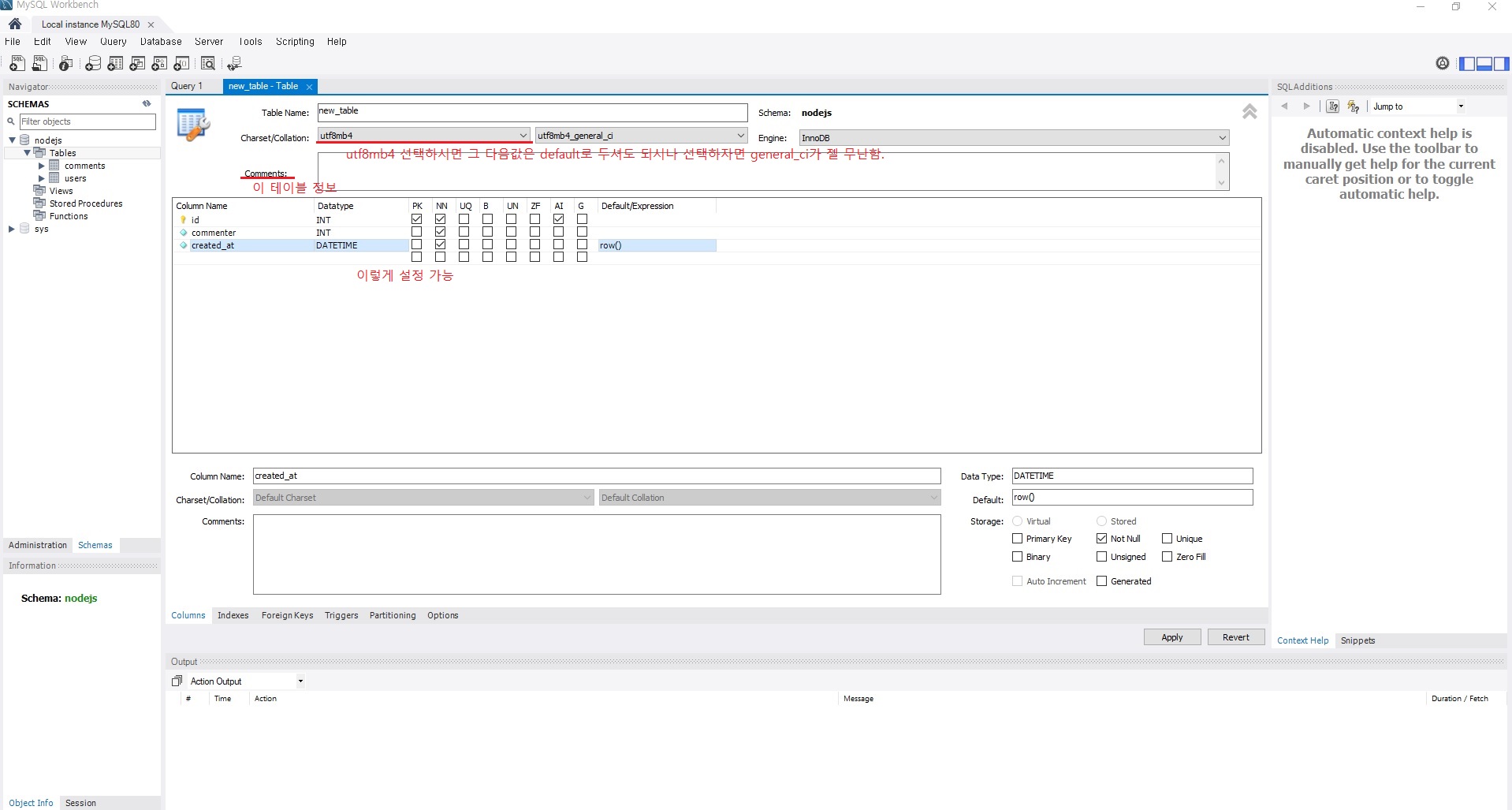
7.2.2 테이블 생성하기
-
MySQL 프롬프트에서 테이블 생성
CREATE TABLE [데이터베이스명.테이블명]으로 테이블 생성-
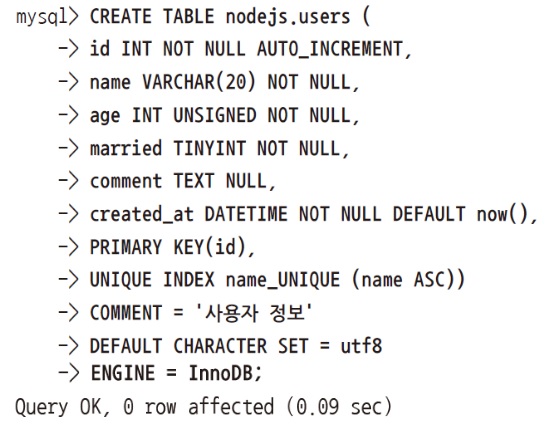
사용자 정보를 저장하는 테이블
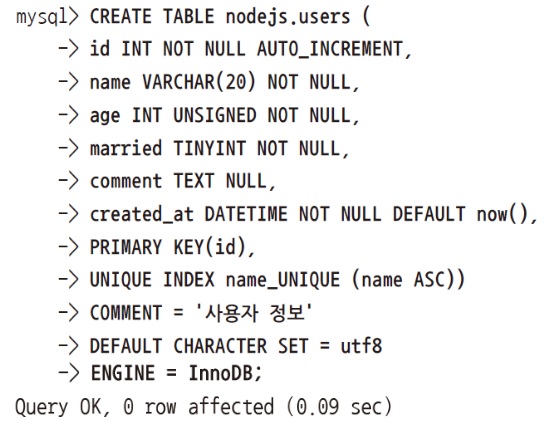
테이블이 뭐냐면 데이터베이스 안에 ‘사용자 정보', ‘게시글정보', ‘댓글정보', ‘좋아요정보' 등등 이런 것들이 있죠?
그런 정보 하나하나를 테이블로 만듭니다.
그래서 테이블은 위와 같은 식으로 만들거든요?
문법 하나라도 틀리면 안됩니다.
위와 같이 작성해야됩니다.
SQL 언어가 좀 빡셉니다.
위 SQL 언어 해석을 해드리겠습니다.
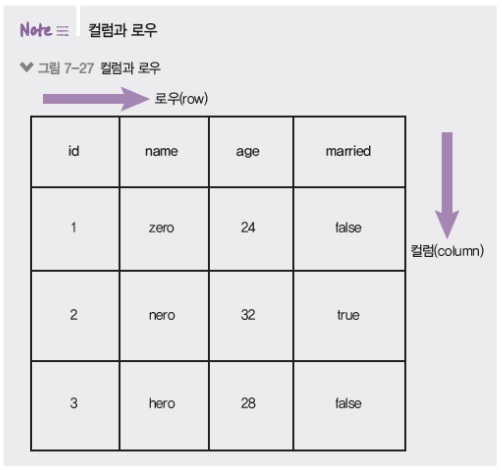
7.2.3 컬럼과 로우
- 나이, 결혼 여부, 성별같은 정보가 컬럼
- 실제로 들어가는 데이터는 로우
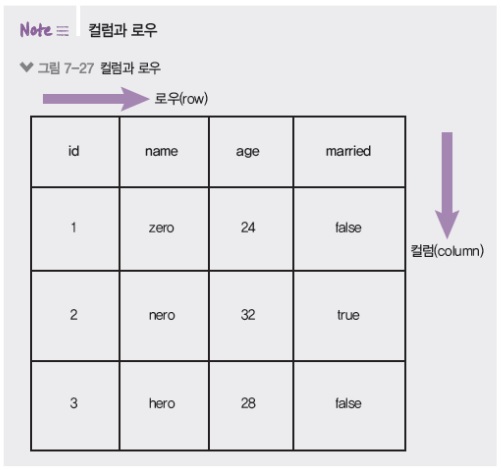
아까 제가 엑셀을 비유로 드렸는데 데이터베이스는 기본적으로 위와 같은 식으로 되어있습니다.
첫줄은 id, name, age, married 이런식으로.. 정형 데이터에 대한 컬럼이 들어가있습니다.
그 다음줄부턴 실제 데이터들이 입력되어있습니다.
id, name, age, married 이 컬럼들을 미리 만들어주셔야합니다.
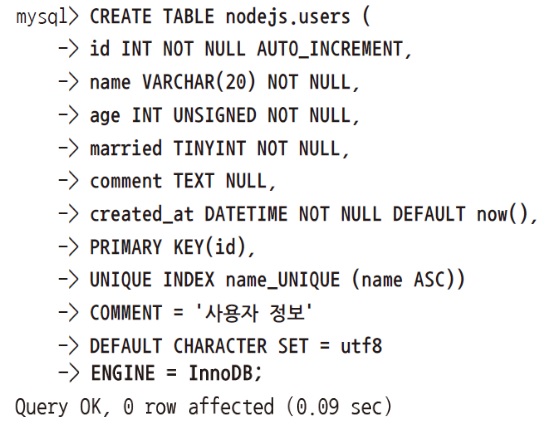
위에서는 id, commenter, comment, created_at 이렇게 4개의 컬럼을 만들어놨네요.
댓글 테이블이라 위와 같은 컬럼으로 나눠놨습니다.
-
id: 고유한 숫자. 1, 2, 3, 4 이런식으로 순서대로 가도 돼고..
이렇게 순서대로 갈 시에는AUTO_INCREMENT를 붙여주고..
INT이렇게 숫자라는 것도 알려줍니다.
그리고NOT NULL이란 것은 필수여야된다 라는 뜻입니다. -
commenter: 댓글 단 사람의 아이디를 저장하는 곳.
그 사람의 ID는INT, 그리고NOT NULL필수. -
comment:
VARCHAR(100)댓글은 100글자 이하.
NOT NULL필수. -
created_at: 언제 댓글 작성했는지 저장하는 곳.
DATETIME-DATE가 있고DATETIME이 있는데,DATE면 날짜까지 기록하는 거고DATETIME은 날짜에 시간까지 기록함.
NOT NULL필수.
DEFAULT now()기본값으로 현재 시간을 넣어주겠다는 뜻.
기본값이라는 것은 사용자가 값을 안 넣어주면 데이터베이스에서 기본적으로 넣어주는 값을 의미함.
7.2.4 컬럼 옵션들
-
id INT NOT NULL AUTO_INCREMENT- 컬럼명 옆의 것들은 컬럼에 대한 옵션들
INT: 정수 자료형(FLOAT,DOUBLE은 실수)VARCHAR: 문자열 자료형, 가변 길이(CHAR은 고정 길이)TEXT: 긴 문자열은TEXT로 별도 저장. 몇글자인지 제한 없음.DATETIME: 날짜 자료형 저장TINYINT: -128에서 127까지 저장하지만,, 저는 여기서는 1 또는 0만 저장해 불린 값 표현
저는TINYINT를 불린 값 표현할 때 사용하는 편.
컬럼들에는 이러한
INT,VARCHAR등등.. 자료형을 하나씩 붙여줘야돼고..
위 자료형말고도 더 있습니다.JSON등 더 있습니다.NOT NULL: 빈 값은 받지 않는다는 뜻(NULL은 빈 값 허용)AUTO_INCREMENT: 숫자 자료형인 경우 다음 로우가 저장될 때 자동으로 1 증가UNSIGNED: 0과 양수만 허용ZEROFILL: 숫자의 자리수가 고정된 경우 빈 자리에 0을 넣음
INT(10)이라고 쓸 때도 있는데 이 경우는 숫자의 자릿수가 아니라 표시 자릿수입니다.
표시 자릿수가 10자리인데 만약에ZEROFILL이 설정되어있다면, 1을 넣으면0000000001이렇게 앞에0이 자동으로 붙습니다.
그런데 저는 사실ZEROFILL을 써본 경험은 없습니다.DEFAULT now(): 날짜 컬럼의 기본값을 현재 시간으로.
now()는 보통DATETIME에서 씀. 현재 시간을 넣어주는 용도로.
숫자라면 기본값으로DEFAULT 1이렇게 설정해줄 수도 있고TINYINT인 경우엔DEFAULT 0이렇게 false 값을 기본값으로 설정해줄 수도 있음.
자료형 다음에는 위의 옵션들을 붙여줄 수 있습니다.
위에서TINYINT가 -128 ~ 127이라고 했잖아요?
TINYINT UNSIGNED를 하면 0 ~ 255가 됩니다.
INT도 사실 숫자의 범위가 정해져있습니다. 정수에 특정 범위가 정해져있고
FLOAT,DOUBLE은 소수까지 표현할 수 있거든요?
소수를 사용하고 싶으시면FLOAT, 소수가 좀 커지거나 복잡해진다 하면DOUBLE데이터베이스 자료형에 대해선 따로 검색을 해보시는 게 좋습니다.
데이터베이스마다 다를 수도 있고 자료형 범위가 잘 안외워지기 때문에 (INT) 이런거는 그때그때 찾아보시는 게 좋습니다.
여튼 위와 같이 테이블에 대한 자료형 및 옵션을 미리 만들어줘야합니다.
그리고 여기에서 설정해놓은걸 벗어나면 에러가 발생합니다.
MySQL은 정형 데이터라고 말씀드렸죠?
저희가 틀을 미리 만들어놨으면 그 틀에서 벗어나시면 안됩니다.
7.3 컬럼의 옵션들
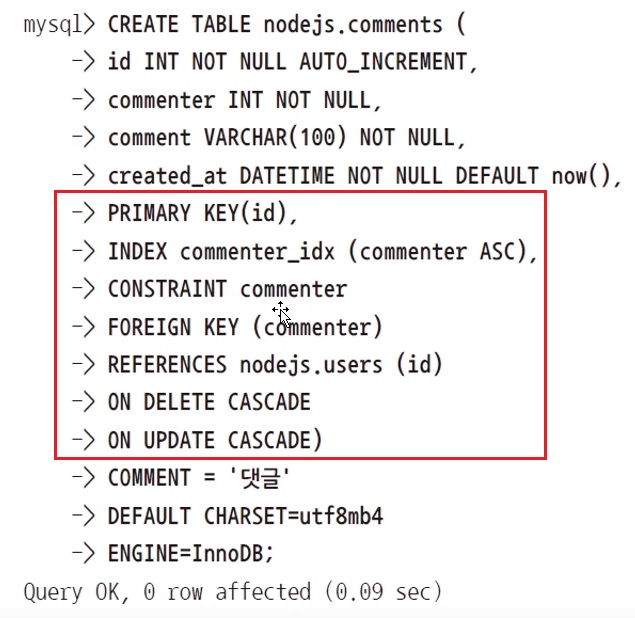
위 부분은 컬럼들의 추가 옵션들입니다.
-
PRIMARY KEY(id), UNIQUE INDEX name_UNIQUE (name ASC))-
PRIMARY KEY(id)- id가 테이블에서 로우를 특정할 수 있게 해주는 고유한 값임을 의미
- 학번, 주민등록번호같은 것들.. 고유한 값들임
- Primary key는 1개 이상도 설정 가능합니다.
어떤 고유값을 정해주는 건데, 보통id를 고유값으로 정해줍니다.
id자체가 고유하다는 뜻도 가지고 있기 때문에, 보통 primary key로 정해주고name을 primary key로 정해줘도 됩니다.
그런데 보통 사람 이름은 겹칠 수도 있잖아요?
그래서 겹칠 가능성이 없는걸로id같은 걸로 정해줍니다.
-
INDEX commenter_idx (commenter ASC),- 테이블에서 자주 검색할만한 것들은
INDEX를 걸어주시면 검색 성능이 빨라집니다.
예를 들어, 댓글 검색할 때 주로 작성자를 검색합니다.(commenter)
그래서 commenter에다가INDEX를 걸어줍니다.
commenter_idx이 인덱스명은 겹치지 않게 아무거나 지어주시면 됩니다.
(commenter ASC)commenter 컬럼을 오름차순으로 인덱싱하겠다 라는 뜻입니다.
- 테이블에서 자주 검색할만한 것들은
-
CONSTRAINT commenter
FOREIGN KEY (commenter)
REFERENCES nodejs.users (id)
ON DELETE CASCADE
ON UPDATE CASCADE)-
commenter에다가 어떤 제약을 두겠다.
지금 현재 nodejs.comments 테이블만 보고있는데 실제로는 users 테이블도 있거든요?
현재 이 부분은 테이블이 2개 이상 있을 때, 그 테이블들 간의 관계를 나타내기 위해 사용한겁니다.현재 commenter에는 제 아이디나 다른 사람들의 아이디가 들어있습니다.
예를 들어 제 아이디가 1번이라고 하면, 그리고 nero의 아이디가 2번이라고 하면, 그리고 3번 부터는 아직 없는데 어떤 프로그램이 "3번 사용자가 댓글을 달았습니다."라고 하면 이건 말이 안되는 상황이죠?
사용자가 1번이랑 2번, 두명밖에 없는데 갑자기 3번 사용자가 댓글을 달면 말이 안되잖아요?
그런거를 검사해주는 거라고 보시면 됩니다. 여튼 users 테이블이 있다고 치면, commenter 컬럼에다가FOREIGN KEY (commenter)하나 달아주시고REFERENCES nodejs.users (id)users 테이블의 id를 참조하도록..
즉, users 테이블의 id에 1, 2가 있다면 comments 테이블의 commenter에도 1이나 2 둘 중에 하나가 있어야되는겁니다.예를 들어, 사용자가 나중에 더 늘어나서 1, 2, 3, 4, 5가 있는데 1번 사용자가 탈퇴했어요.
그러면 2, 3, 4, 5번 사용자가 있겠죠?
그런데 프로그램이 1번 사용자가 댓글을 작성하였습니다 라고 한다면 말이 안되죠? 탈퇴한 사용자가 댓글을 쓸 리가 없잖아요.
그럴 때 에러를 발생시켜줍니다.
FOREIGN KEY (commenter)이를 외래키라고 하는데, 어떤 컬럼이 다른 테이블의 컬럼을 참조해서 그 컬럼에 진짜 값이 있어야만 등록할 수 있게 해주는 역할. -
ON DELETE CASCADE,ON UPDATE CASCADE)
사용자 1번이 만약 탈퇴를 했습니다.
탈퇴를 할 때 그 사람이 쓴 댓글까지ON DELETE CASCADE같이 지울거냐.CASCADE하면 같이 지울겁니다 라는 겁니다.
SET NULL은 댓글은 남겨두고 commenter만 null로 한다는 뜻입니다.
NO ACTION아무일도 안할게요 도 있습니다.
사용자가 탈퇴하던말던 해당 사용자가 댓글 남겼다는거 계속 유지할거야, 그게NO ACTION입니다.
CASCADE,SET NULL,NO ACTIONON UPDATE CASCADE)는 1번 사용자가 수정되었을 때 이 댓글도 같이 수정할건지.
CASCADE,SET NULL,NO ACTION보통SET NULL,CASCADE을 많이 쓰고NO ACTION은 잘 안했던거 같은데 이게 다 필요할 때가 있거든요.여러분들이 데이터를 만약 삭제할 때, 회원정보를 삭제한다고 그 서비스에서 바로 데이터가 삭제되진 않습니다.
대부분은 처음에 회원가입할 때 몇년동안 개인정보 유지할지 동의를 받아서.. 3년이라고 한다면 내가 지금 탈퇴해도 3년간은 데이터가 남아있거든요?
어떤 사람이 탈퇴한다고해서 무턱대고 그 사람 사용자 정보랑 댓글들, 그 사람의 게시글들 싹 지워버리면, 갑자기 그 사람이 3년 안에 마음이 바뀌어서 나 다시 회원 복구해줘 하면 "어? 고객님 제가 다 지워버렸는데요?" 이럴 순 없잖아요?
그래서 대부분의 경우는 어떤 사람이 회원 탈퇴를 해도 그대로 놔두는 경우가 많아서CASCADE,SET NULL,NO ACTION이런 것들을 잘 설정을 해주셔야됩니다. 정책에 따라서.
-
-
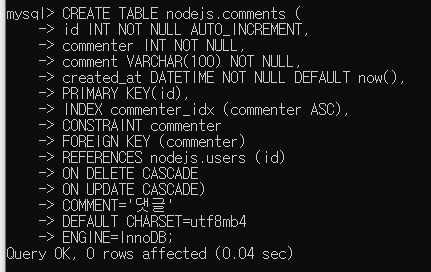
COMMENT = '댓글'
DEFAULT CHARSET=utf8mb4
ENGINE=InnoDB;- mb4를 붙이면 이모티콘 같은 것도 넣을 수 있다는 뜻.
id 이런데 이모티콘 못쓰게 하고싶다면 utf8만 넣으면 됩니다.
COMMENT = '댓글'는 comments 테이블에 대한 설명.
ENGINE=InnoDB;엔진은 InnoDB와 MyISAM이 있는데 이거는 데이터베이스 수업 때 공부하세요.
이거는 여기서 가르치기엔 범위 초과입니다.
- mb4를 붙이면 이모티콘 같은 것도 넣을 수 있다는 뜻.
-
UNIQUE INDEX name_UNIQUE (name ASC)- 해당 컬럼(name)이 고유해야 함을 나타내는 옵션
- name_UNIQUE는 이 옵션의 이름(아무거나 다른 걸로 지어도 됨)
- ASC는 인덱스를 오름차순으로 저장함의 의미(내림차순은 DESC)
-
-
테이블 옵션
COMMENT: 테이블에 대한 보충 설명(필수 아님)DEFAULT CHARSET: utf8로 설정해야 한글이 입력됨(utf8mb4 하면 이모티콘 가능)ENGINE: InnoDB 사용(이외에 MyISAM이 있음, 엔진별로 기능 차이 존재)
- 관계 잡을 때 꿀팁? -
테이블간 관계 잡을 때 꿀팁은 "중복이 없어야되거든요."
이거는 정규화를 검색해보세요.
정규화라는 데이터베이스 수업을 공부하셔야됩니다.
정규화 수업을 들으실 필요는 없고 관련 책을 읽어보시면 관계잡을 때 팁, 원칙을 알려줍니다.
- 대댓글? -
MySQL에서 댓글에 댓글다는거, 보통 대댓글이라고하죠?
대댓글은 방식이 진짜 여러가지가 있습니다.
저는 어떻게하냐면 대댓글 테이블 없이 댓글에 다 넣어놓고 대댓글인 경우엔 부모 댓글의 id만 넣어놓습니다.
일반 댓글처럼 다 저장한다음에 대댓글인 경우에만 부모 id를 넣어놓고 프론트에서 부모 아이디를 보고 조립을 합니다.
부모 아이디가 없는 애들은 가장 높은 단계에 있는 애들이니까 그냥 바로바로 배치를 하고 혹시나 부모 아이디가 있는 댓글들은 그 부모 아래로 넣어줍니다.
저는 이렇게 프론트에서 보통 조립을 해주는 편입니다.
- users 테이블 -
아까 실수로 comments 테이블부터 분석을 해봤는데
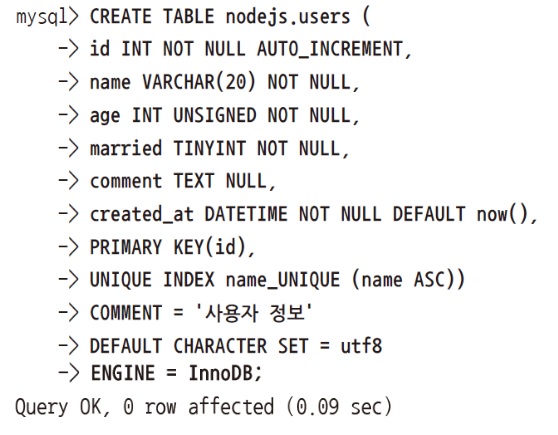
사용자 테이블에도 id, name, age, married, comment, created_at 이렇게 있습니다.
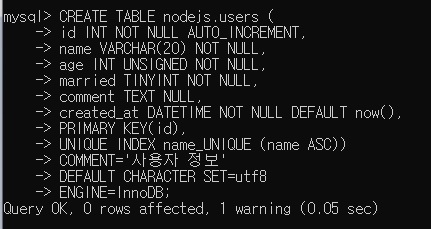
id INT NOT NULL AUTO_INCREMENT,: id는 숫자고 필수고 자동으로 증가하고.name VARCHAR(20) NOT NULL,: 이름은 최대 20글자까지. 필수.age INT UNSIGNED NOT NULL,: 나이는 숫자고 양수고 필수고.married TINYINT NOT NULL,: 결혼여부 TINYINT는 -128 ~ 127이지만 여기선 0, 1 불린값용도로 저장함. 필수.comment TEXT NULL,: comment는 댓글이아니라 자기소개 부분임. 컬럼명도 헷갈리지 않게 짓는 것이 좋음. 길이 무제한에 적어도되고 안적어도되고.created_at DATETIME NOT NULL DEFAULT now(),: 생성일시간, 필수, 기본값은 현재시간PRIMARY KEY(id): 고유값은 id로UNIQUE INDEX name_UNIQUE (name ASC)): UNIQUE INDEX, INDEX는 아까 검색 속도를 빠르게한다고 그랬죠?
누구의 댓글 가져와 할 때 ‘누구'가 검색이 많이 되기 때문에 그 ‘누구'를 INDEX로 만들어놓으면 빠르게 검색한다고 했는데,
UNIQUE INDEX를 붙이면 ‘누구'가 고유값이 됩니다.
id도 고유값이지만 UNIQUE INDEX를 붙이면 name도 고유값이 됩니다.
그러면 name에다 UNIQUE만 붙이면되지 왜 INDEX까지 같이 붙이냐면, UNIQUE를 하면 INDEX를 붙일 수밖에 없습니다. 왜?
UNIQUE를 하면 INDEX를 붙일 수밖에 없는게, 만약 어떤 사람을 새로 입력을 하면 "이형주"라는 사람을 입력을 하면 기존 데이터베이스에 "이형주"가 있는지 없는지 검사를 해봐야되죠?
그래야 그 값이 고유한지 아닌지를 알 수 있잖아요?
그래서 UNIQUE면 검색을 자주하기 때문에 INDEX를 자동으로 붙일 수밖에 없습니다.COMMENT = '사용자 정보': users 테이블에 대한 정보DEFAULT CHARACTER SET = utf8ENGINE = InnoDB;
7.3.1 사용자 테이블 저장하기
7.3.2 댓글 테이블 저장하기
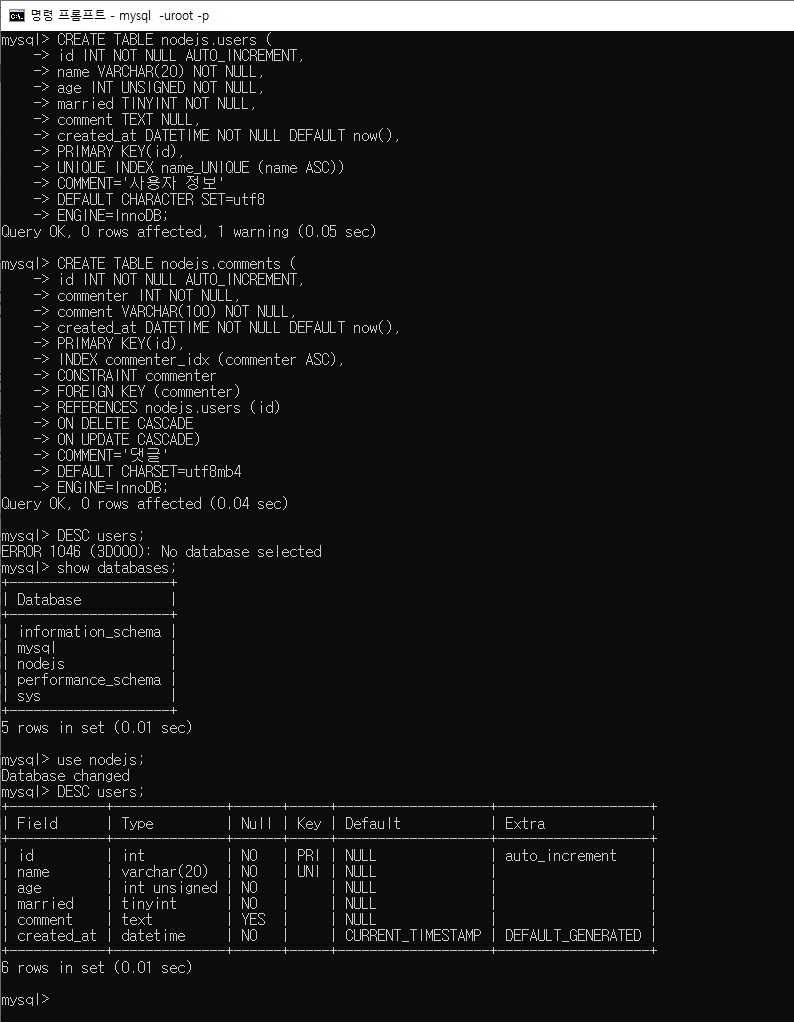
7.3.3 테이블 생성되었나 확인하기
-
DESC 테이블명mysql> DESC users; -
테이블 삭제하기:
DROP TABLE 테이블명mysql> DROP TABLE users;
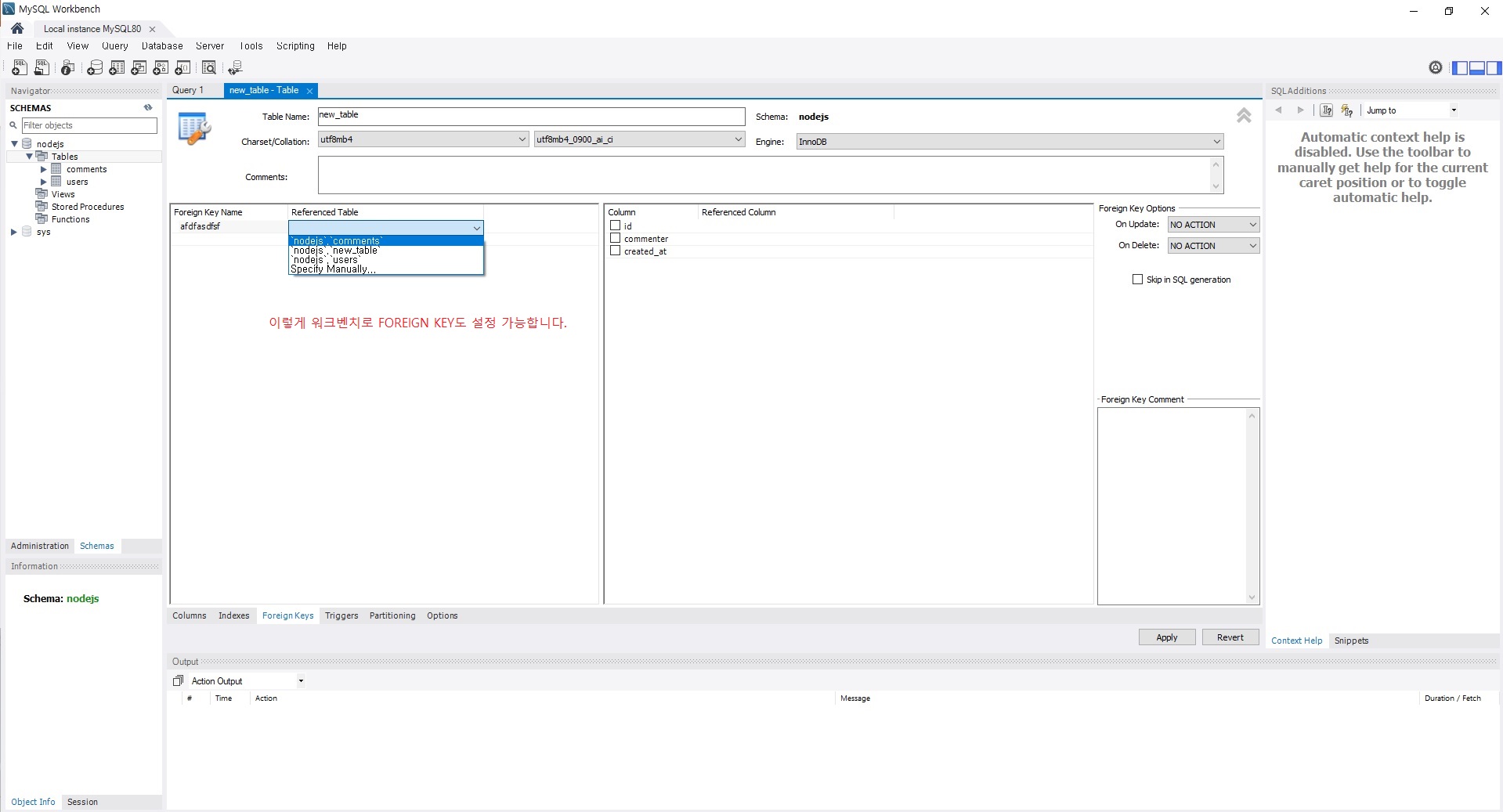
7.3.4 외래키(foreign key)
-
댓글 테이블은 사용자 테이블과 관계가 있음(사용자가 댓글을 달기 때문)
사용자 테이블의 id로 comments 테이블의 commenter에 제약을 두는거.
사용자 테이블의 id 중에서만 commenter가 나올 수 있게.- 외래키를 두어 두 테이블이 관계가 있다는 것을 표시
- FOREIGN KEY (컬럼명) REFERENCES 데이터베이스.테이블명 (컬럼)
- FOREIGN KEY (commenter) REFERENCES nodejs.users (id)
- 댓글 테이블에는 commenter 컬럼이 생기고 사용자 테이블의 id값이 저장됨
- ON DELETE CASCADE, ON UPDATE CASCADE
- 사용자 테이블의 로우가 지워지고 수정될 때 댓글 테이블의 연관된 로우들도 같이 지워지고 수정됨
- 데이터를 일치시키기 위해 사용하는 옵션(CASCADE 대신 SET NULL과 NO ACTION도 있음)
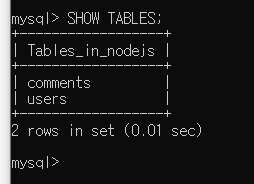
7.3.5 테이블 목록 보기
-
SHOW TABLES;
- 오타 -
그런데 cmd 창에 직접 입력할 때 오타가 많이 날 수 있거든요?
그럼 직접 워크벤치에서 테이블을 생성하셔도 됩니다.
어차피 나중에 JS로 테이블 만드니 걱정하지 마세요.
7.4 CRUD 작업하기
데이터베이스에서 가장 많이하는 작업 4가지입니다.
7.4.1 CRUD
-
Ceate, Read, Update, Delete의 두문자어
-
데이터베이스에서 많이 하는 작업 4가지
-
7.4.2 Create
-
INSERT INTO 테이블 (컬럼명들) VALUES (값들)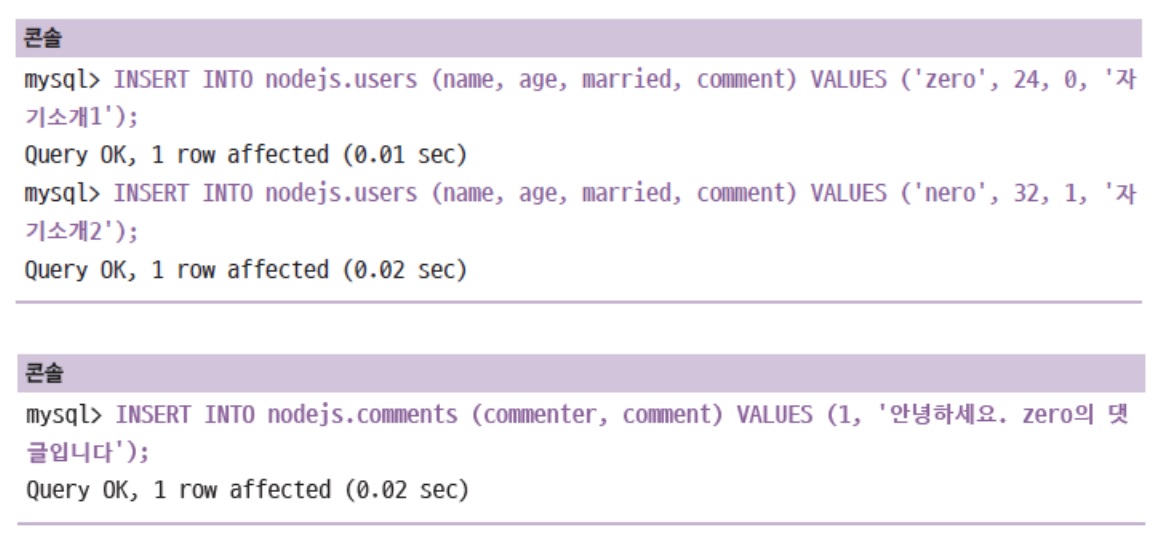
사용자 테이블에 이름, 나이, 결혼여부, 자기소개를 넣는데,
id는 왜 안 넣을까요?
id는 아까 데이터베이스가 자동으로 1, 2, 3, 4… 순서대로 넣는 것으로 설정했죠?
그리고created_at도 없습니다.
created_at도 자기가 안 넣으면DEFAULT now()를 해놨기 때문에 현재시간이 자동으로 들어가서 입력을 안했습니다. 위와 같이 내가 넣고싶은 컬럼들만 ()소괄호 안에 넣어서 넣을 수 있습니다.댓글 또한
id와created_at은 알아서 넣어지니깐 일부로 넣진 않았습니다. 댓글 commenter는 사용자 테이블의 id와 매칭됩니다.
7.4.3 조회 - Read (조회)
-
SELECT 컬럼 FROM 테이블명-
SELECT *은 모든 컬럼을 선택한다는 의미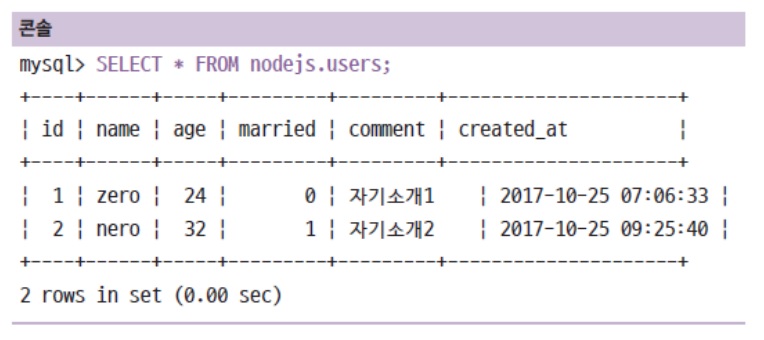
-
컬럼만 따로 추리는 것도 가능
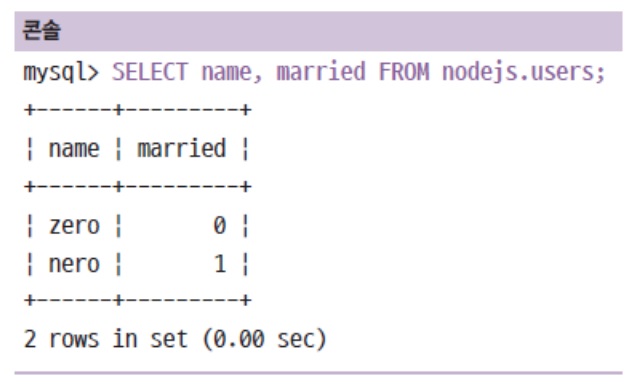
-
7.4.4 조회 - Read 옵션들 (row 추려서 읽기)
-
WHERE로 조건을 주어 선택 가능-
AND로 여러가지 조건을 동시에 만족하는 것을 찾음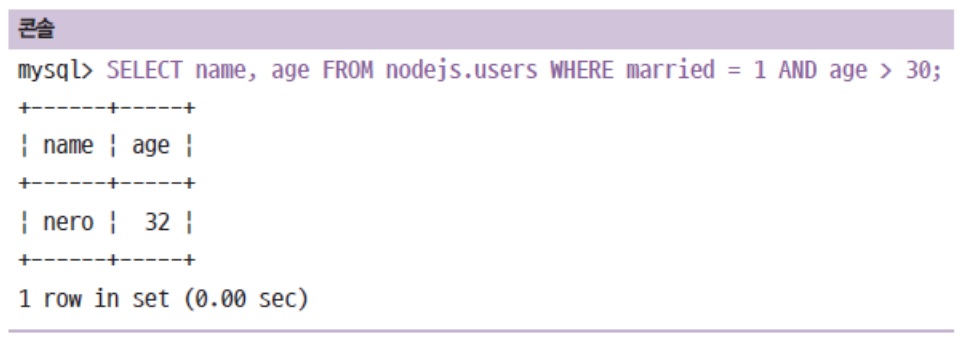
married 부분 TINYINT로 저장해뒀기 때문에 true가 아닌
married = 1이렇게 설정.
위에 사진 보시면 married 컬럼은 안 보입니다.
그건 SELECT 다음에 married 컬럼을 설정 안했기 때문. -
OR로 여러가지 조건 중 하나 이상을 만족하는 것을 찾음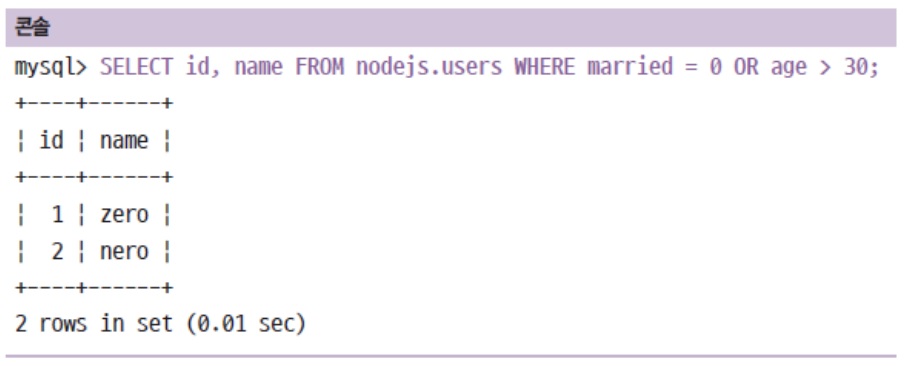
-
7.4.5 조회 - 정렬해서 찾기
-
ORDER BY로 특정 컬럼 값 순서대로 정렬 가능-
DESC는 내침차순, ASC는 오름차순
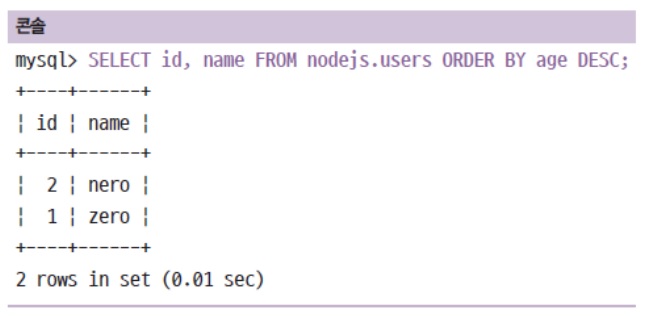
항상 1,2,3,4 이렇게 보여줄 필요는 없고 정렬을 제가 원하는대로 할 수가 있는데 여기선 나이순으로 정렬해봤습니다.
SELECT id, name FROM nodejs.users ORDER BY age DESC;
-
7.4.6 조회 - LIMIT, OFFSET
-
LIMIT으로 조회할 개수 제한

-
OFFSET으로 앞의 로우들 스킵 가능(OFFSET 2면 세 번째 것부터 찾음)

위와 같이 쿼리문을 작성하면
age DESC나이 내림차순으로 정렬되는데,OFFSET 1제일 처음 정렬되는거 빼고 그 다음 것부터 찾아라.
LIMIT 1그리고 1개만 찾아라.
서브 쿼리도 있는데 이는 따로 공부하셔야됩니다.
이거는 노드 강의이기 때문에 데이터베이스에 관련해선 가장 기본적인 것들만 알려드리고 있습니다.
7.4.7 Update
-
데이터베이스에 있는 데이터를 수정하는 작업
-
UPDATE 테이블명 SET 컬럼=새값 WHERE 조건
사용자 테이블에서 어떤 사람의 자기소개를 바꾸는데, id가 2인 사람의 자기소개를 바꾸는 쿼리문입니다.
주의 : 업데이트할 때WHERE(조건)을 빼먹으면 모든 사람의 데이터가 바뀝니다.
업데이트할 땐WHERE(조건)을 빼먹지않게 조심하셔야됩니다.
MySQL에서WHERE빼먹으면 경고를 띄우는 옵션도 있긴한데 여튼 업데이트할 때WHERE빼먹으면 모든 데이터들이 업데이트되는 대참사가 일어날 수도 있습니다.
-
7.4.8 Delete
-
데이터베이스에 있는 데이터를 삭제하는 작업
-
DELETE FROM 테이블명 WHERE 조건
여기도
WHERE, 어떤거 삭제할지.
-
7.5 시퀄라이즈 사용하기
원래는 프로그래밍 서비스 하실 때 SQL 언어까지 아셔야됩니다.
사실상 데이터베이스 없는 서비스는 거의없기 때문에 SQL, 특히 MongoDB 쓰시면 SQL 안 배우시고 MongoDB 배우시면 되지만, 대부분의 서비스들이 SQL이거든요?
그래서 SQL을 배우셔야합니다.
실제로 제 책에서도 SQL을 작성하는게 나오는데 솔직히 SQL 모르시는 분들도 많잖아요?
지금 이 강의 들으시는 분들 중에 난 자바스크립트만 알고 서버 만들러 왔는데 갑자기 SQL까지 배우라니 이게 무슨 날벼락이야 하실 수가 있습니다.
그런데 데이터베이스는 써야겠고 그래서 제가 타협점을 찾은게 시퀄라이즈입니다.
7.5.1 시퀄라이즈 ORM
-
SQL작업을 쉽게 할 수 있도록 도와주는 라이브러리
어떻게 도와주냐.
여러분은 자바스크립트 코드만 쓰시면 됩니다.
자바스크립트 코드를 쓰시면 시퀄라이즈가 알아서 여러분들이 쓴 자바스크립트 코드를SQL로 바꿔서 실행을 해줍니다.- ORM: Object Relational Mapping: 객체와 데이터를 매핑(1대1 짝지음)
- MySQL 외에도 다른 RDB(Maria, Postgre, SQLite, MSSQL)와도 호환됨
시퀄라이즈는 MySQL뿐만 아니라 다른 DB와도 연결이 됩니다.
자바스크립트 문법으로 다양한 데이터베이스와 상호작용이 가능합니다. - 자바스크립트 문법으로 데이터베이스 조작 가능
어 그러면 시퀄라이저 알면SQL안 배워도 되나요? 이렇게 생각하실 수도 있는데 시퀄라이즈로는 간단한 초기 규모의 프로젝트만 하실 수 있고 결국SQL배우셔야합니다.
서버 또는 서비스 개발자가 되실거라면SQL은 어떠한 경로로든 꼭 배우셔야됩니다.
-
시퀄라이즈 예제는 https://github.com/hyungju-lee/node-study/tree/master/ch7/7.6/learn-sequelize
-
프로젝트 세팅 후, 콘솔을 통해 경로로 이동한 후 package.json 작성
{ "name": "learn-sequelize", "version": "0.0.1", "description": "시퀄라이즈를 배우자", "main": "app.js", "scripts": { "start": "nodemon app" }, "author": "hyungju-lee", "license": "MIT" }
-
7.5.2 시퀄라이즈 CLI 사용하기
-
시퀄라이즈 명령어 사용하기 위해
sequelize-cli설치-
mysql2는MySQL DB가 아닌 드라이버(Node.js와MySQL을 이어주는 역할)
여러분들이 마우스를 본체에 꼽으면 마우스 드라이버가 PC와 연결이 되잖아요?
그런 것처럼mysql2은 노드와 MySQL을 연결해주는 드라이버입니다.npm i express morgan nunjucks sequelize sequelize-cli mysql2 npm i -D nodemon
-
-
npx sequelize init으로 시퀄라이즈 구조 생성
sequelize-cli로 인해 sequelize 명령어를 사용할 수 있음.npx sequelize init이를 실행하시면
package.json밖에 없었던 폴더에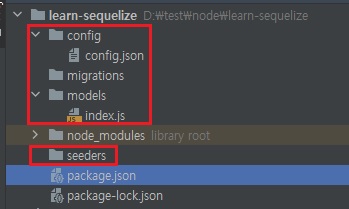
이렇게 폴더와 파일들이 생성됩니다.
7.5.3 models/index.js 수정
models/index.js 파일에 뭐라고 적혀있을건데 아래와 같이 수정하십시오.
-
다음과 같이 수정
- require(../config/config) 설정 로딩
-
new Sequelize(옵션들…)로 DB와 연결 가능

const Sequelize = require('sequelize'); const env = process.env.NODE_ENV || 'development'; const config = require('../config/config.json')[env]; const db = {}; const sequelize = new Sequelize(config.database, config.username, config.password, config); db.sequelize = sequelize; module.exports = db;이렇게 바꾸면 아까
mysql2드라이버를 사용해서 MySQL이랑 시퀄라이즈랑 노드랑 연결해주는 그런 코드라고 보시면됩니다.
- config/config.json 수정 -
password, database 이 두개 부분을 수정해주시면 됩니다.
database 이름은 생성 이름을 적으면 됩니다.
{
"development": {
"username": "root",
"password": "",
"database": "nodejs",
"host": "127.0.0.1",
"dialect": "mysql"
},
"test": {
"username": "root",
"password": null,
"database": "database_test",
"host": "127.0.0.1",
"dialect": "mysql"
},
"production": {
"username": "root",
"password": null,
"database": "database_production",
"host": "127.0.0.1",
"dialect": "mysql"
}
}
참고로 워크벤치에서 데이터베이스(스키마)를 만드는 방법은 아래와 같습니다.
character set은 utf8 또는 utf8mb4로 하면 됩니다.
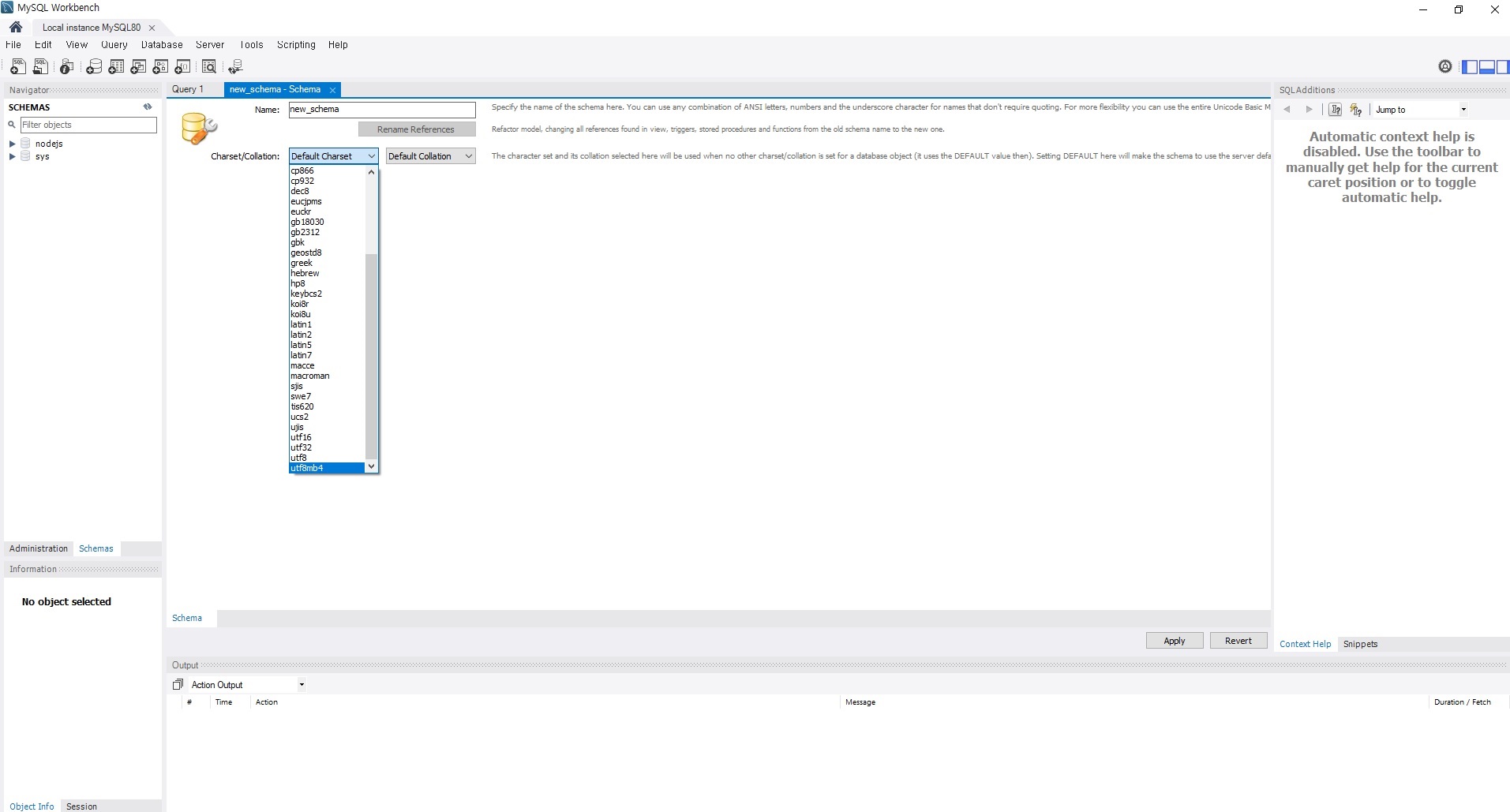
7.5.4 MySQL 연결하기
-
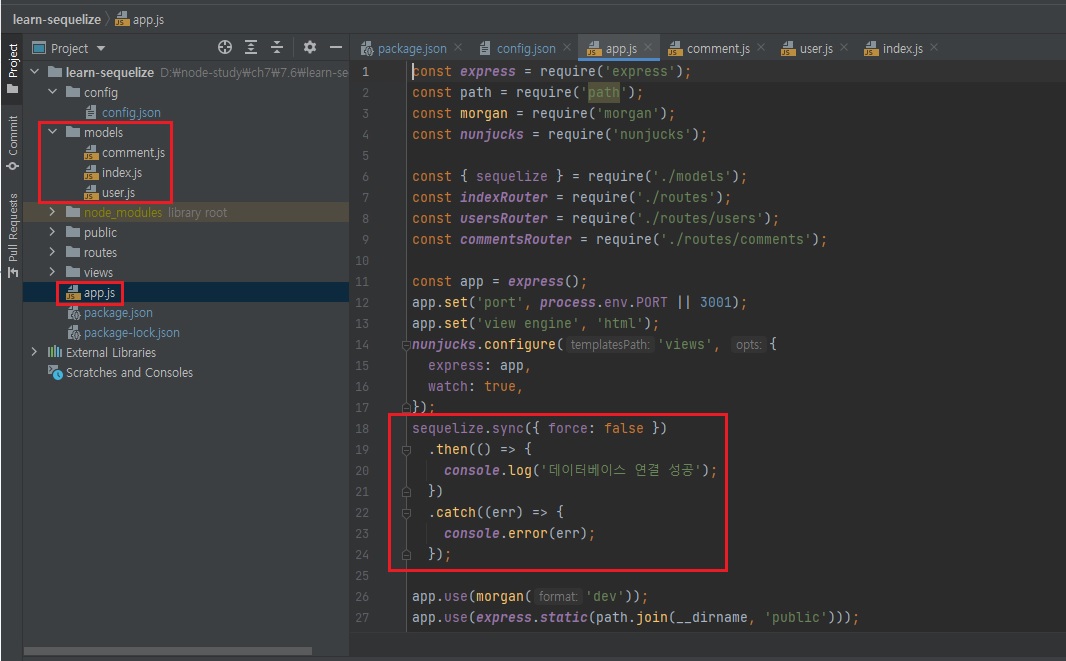
app.js 작성
-
sequelize.sync로 연결
그럼 데이터베이스에 연결이 됩니다.
노드 - MySQL이 연결이 됩니다. 시퀄라이즈를 통해서.sequelize.sync({force: false}) .then(() => { console.log('데이터베이스 연결 성공'); }) .catch((err) => { console.error(err); });이 코드를 아래 코드 안에 반드시 작성을 해줘야 연결이 된다는 것.
위 코드 빼먹으면 연결이 안됩니다.// app.js const express = require('express'); const path = require('path'); const morgan = require('morgan'); const nunjucks = require('nunjucks'); const {sequelize} = require('./models'); const indexRouter = require('./routes'); const usersRouter = require('./routes/users'); const commentsRouter = require('./routes/comments'); const app = express(); app.set('port', process.env.PORT || 3001); app.set('view engine', 'html'); nunjucks.configure('views', { express: app, watch: true, }); sequelize.sync({force: false}) .then(() => { console.log('데이터베이스 연결 성공'); }) .catch((err) => { console.error(err); }); app.use(morgan('dev')); app.use(express.static(path.join(__dirname, 'public'))); app.use(express.json()); app.use(express.urlencoded({extended: false})); app.use('/', indexRouter); app.use('/users', usersRouter); app.use('/comments', commentsRouter); app.use((req, res, next) => { const error = new Error(`${req.method} ${req.url} 라우터가 없습니다.`); error.status = 404; next(error); }); app.use((err, req, res, next) => { res.locals.message = err.message; res.locals.error = process.env.NODE_ENV !== 'production' ? err : {}; res.status(err.status || 500); res.render('error'); }); app.listen(app.get('port'), () => { console.log(app.get('port'), '번 포트에서 대기 중'); });
-
7.5.5 연결 테스트하기
-
npm start로 실행해서SELECT 1+1 AS RESULT가 나오면 연결 성공
SELECT 1+1 AS RESULT-SQL하나를 MySQL에 실행시켜서 연결 잘 되어있는지 검사하는 거.
그래서SELECT 1+1 AS RESULT이게 잘 실행됐다면 "데이터베이스 연결 성공"이 뜰거임.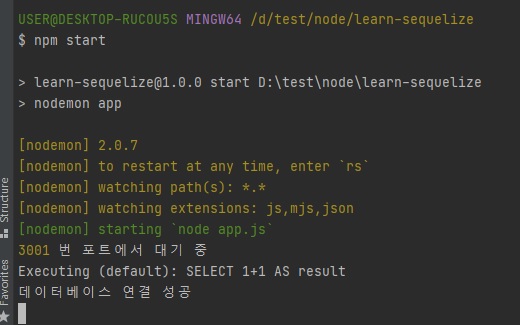
- 코드 분석!! -
## package.json
### 명령어
"start": "nodemon app" - 명령어
### dependencies 모듈
"express": "^4.17.1",
"morgan": "^1.10.0",
"mysql2": "^2.2.5",
"nunjucks": "^3.2.2",
"sequelize": "^6.3.4",
"sequelize-cli": "^6.2.0"
### devDependencies 모듈
"nodemon": "^2.0.4"
## 위와 같이 설치하고
## npx sequelize init 명령어 실행
## 아래와 같이 생성됨
## 이를 기반으로 현재 예시파일 설정
|- config 폴더
|- migrations 폴더
|- models 폴더
|- seeders 폴더
|- package.json
// app.js
const express = require('express'); // express 모듈 불러와서 express 변수에 저장
const path = require('path'); // node의 기본 모듈인 path 모듈 불러와서 path 변수에 저장
const morgan = require('morgan'); // 자주 쓰는 미들웨어 중 하나
// 내부에서 알아서 next를 호출해 다음 미들웨어로 넘김
// morgan: 서버로 들어온 요청과 응답을 기록해주는 미들웨어이다.
// 로그의 자세한 정도도 선택 가능하다. (dev, tiny, short, common, combined)
// 예시) GET / 200 51.267ms - 1539
// 순서대로 HTTP 요청, 요청주소, 상태코드, 응답속도 - 응답바이트
// 개발 환경에서는 dev, 배포환경에서는 combined를 애용한다.
const nunjucks = require('nunjucks'); // 넌적스 템플릿 엔진
const { sequelize } = require('./models');
const indexRouter = require('./routes');
const usersRouter = require('./routes/users');
const commentsRouter = require('./routes/comments');
const app = express();
app.set('port', process.env.PORT || 3001); // 서버가 실행될 포트를 지정해준다.
// app.get("주소", 라우터) // GET 요청이 들어올 때 어떤 동작을 해야될지 지정해준다.
// app.listen(app.get("port"), 콜백) // 몇 번 포트에서 서버를 실행할지 지정한다.
app.set('view engine', 'html'); // 보통 확장자를 njk라고 할 수도 있는데, nunjucks는 html로도 많이 사용한다.
nunjucks.configure('views', { // 이렇게하면 views 폴더가 넌적스 파일들의 위치가 된다.
express: app,
watch: true,
});
sequelize.sync({ force: false }) // sequelize.sync로 연결, 그럼 데이터베이스에 연결이 된다. 노드 - MySQL이 연결이 된다. 시퀄라이즈를 통해서.
.then(() => {
console.log('데이터베이스 연결 성공');
})
.catch((err) => {
console.error(err);
});
// express는 미들웨어로 구성된다.
// app.use(미들웨어)로 장착한다.
// 위에서 아래로 순서대로 실행된다.
// 미들웨어는 req, res, next가 매개변수이다.
// req: 요청, res: 응답 조작 가능
// next()로 다음 미들웨어로 넘어간다.
// app.use(미들웨어) : 모든 요청에서 미들웨어 실행
// app.use('/abc', 미들웨어) : abc로 시작하는 요청에서 미들웨어 실행
// app.post('/abc', 미들웨어) : abc로 시작하는 POST 요청에서 미들웨어 실행
app.use(morgan('dev')); // morgan 모듈을 사용할 땐 이 코드를 추가해준다.
// 다시말하지만 morgan은 요청과 응답을 기록하는 라우터이다.
app.use(express.static(path.join(__dirname, 'public'))); // express에서 제공하는 미들웨어이다.
// app.use(요청경로, express.static(실제경로));
// 정적인 파일들을 제공하는 미들웨어이다.
// 인자로 정적 파일의 경로를 제공한다.
// 파일이 있을 때 fs.readFile로 직접 읽을 필요가 없다.
// 요청하는 파일이 없으면 알아서 next를 호출해 다음 미들웨어로 넘어간다.
// 파일을 발견했다면 다음 미들웨어는 실행되지 않는다.
// express.static 미들웨어 장점:
// 사용자가 보낸 요청주소 - localhost:3000/stylesheets/style.css
// 실제 컨텐츠가 있는 경로 - /public/stylesheets/style.css
// 서버의 구조를 파악하기 어려워져서 보안에 도움이된다.
app.use(express.json()); // body-parser 모듈 - 미들웨어를 사용하면 조금 옛날 사람이라고 그랬다.
// 왜냐하면 예전엔 body-parser를 설치해서 사용했었는데, 요즘엔 body-parser의 기능이 express로 들어갔다. (3~4년 전)
app.use(express.urlencoded({ extended: false }));
// 보통 위의 두 코드를 많이 사용한다. express.join(), express.urlencoded()
// 위 두 코드의 장점은, express를 사용 '안'했을 시에 아래와 같이 작성하던 코드를
// // 요청의 body를 stream 형식으로 받음
// req.on('data', (data) => { // <- POST와 PUT 메소드는 클라이언트로부터 데이터를 받으므로 특별한 처리가 필요하다.
// body += data; // req.on('data', 콜백)과 req.on('end', 콜백) 부분인데, 3강에서 배웠던 readStream 이다.
// }) // readStream 으로 요청과 같이 들어오는 본문을 받을 수 있다.
// 단, 문자열이므로 JSON으로 만드는 JSON.parse 과정이 한 번 필요하다.
// // 요청의 body를 다 받은 후 실행됨
// return req.on('end', () => {
// console.log('POST 본문(Body):', body);
// const {name} = JSON.parse(body);
// const id = Date.now();
// users[id] = name;
// res.wrtieHead(201, {'Content-Type': 'text/plain; charset=utf-8'});
// res.end('ok');
// })
// 위와 같이 작성할 필요 없이 express.join(), express.urlencoded() 이 두 코드를 넣으면 알아서 데이터가 파싱된다는 점이다.
// 라우터 분리하기
// app.get, app.post 처럼 메소드와 url이 있는 것들을 라우터라고 부르는데, 아래와 같이 라우터들을 분리해줄 수 있다.
app.use('/', indexRouter); // 아래 라우터가 실행된다.
// const express = require('express');
// const User = require('../models/user');
//
// const router = express.Router();
//
// router.get('/', async (req, res, next) => { // <- '/' 경로로 GET 요청이 들어오면
// try {
// const users = await User.findAll(); // findAll() 메소드는 Promise 객체를 반환한다. SELECT * FROM nodejs.users; 와 매칭된다.
// res.render('sequelize', { users });
// } catch (err) {
// console.error(err);
// next(err);
// }
// });
//
// module.exports = router;
app.use('/users', usersRouter); // 아래 라우터가 실행된다.
// const express = require('express');
// const User = require('../models/user');
// const Comment = require('../models/comment');
//
// const router = express.Router();
//
// router.route('/')
// .get(async (req, res, next) => {
// try {
// const users = await User.findAll();
// res.json(users);
// } catch (err) {
// console.error(err);
// next(err);
// }
// })
// .post(async (req, res, next) => {
// try {
// const user = await User.create({
// name: req.body.name,
// age: req.body.age,
// married: req.body.married,
// });
// console.log(user);
// res.status(201).json(user);
// } catch (err) {
// console.error(err);
// next(err);
// }
// });
//
// router.get('/:id/comments', async (req, res, next) => {
// try {
// const comments = await Comment.findAll({
// include: {
// model: User,
// where: { id: req.params.id },
// },
// });
// console.log(comments);
// res.json(comments);
// } catch (err) {
// console.error(err);
// next(err);
// }
// });
//
// module.exports = router;
app.use('/comments', commentsRouter); // 아래 라우터가 실행된다.
// const express = require('express');
// const { Comment } = require('../models');
//
// const router = express.Router();
//
// router.post('/', async (req, res, next) => {
// try {
// const comment = await Comment.create({
// commenter: req.body.id,
// comment: req.body.comment,
// });
// console.log(comment);
// res.status(201).json(comment);
// } catch (err) {
// console.error(err);
// next(err);
// }
// });
//
// router.route('/:id')
// .patch(async (req, res, next) => {
// try {
// const result = await Comment.update({
// comment: req.body.comment,
// }, {
// where: { id: req.params.id },
// });
// res.json(result);
// } catch (err) {
// console.error(err);
// next(err);
// }
// })
// .delete(async (req, res, next) => {
// try {
// const result = await Comment.destroy({ where: { id: req.params.id } });
// res.json(result);
// } catch (err) {
// console.error(err);
// next(err);
// }
// });
//
// module.exports = router;
// 404도 사실상 에러니까 아래처럼.. error.status = 404
// 이런식으로하면 404에 대한 메시지가 완성이되고
app.use((req, res, next) => {
const error = new Error(`${req.method} ${req.url} 라우터가 없습니다.`);
error.status = 404;
// next(error)를 하면 바로 아래 에러처리 미들웨어로 보내진다.
// 404 에러도 에러처리 미들웨어에서 같이 처리하자는 것이다.
next(error);
});
// 아래는 에러처리 미들웨어이다.
// 에러 발생 시 템플릿 엔진과 상관없이 템플릿 엔진 변수를 설정하고 error 템플릿을 랜더링한다.
// res.locals.변수명으로도 템플릿 엔진 변수 생성 가능하다.
// process.env.NODE_ENV는 개발환경인지 배포환경인지 구분해주는 속성이다.
app.use((err, req, res, next) => {
// res.locals.message와 res.locals.error는 템플릿 엔진의 변수이다.
// 거기에다가 메시지들을 넣는 것이다.
res.locals.message = err.message; // 에러 메시지를 넣는다.
res.locals.error = process.env.NODE_ENV !== 'production' ? err : {}; // 에러 자체도 넣고
// 개발용일땐 땐 err을 넣어주고, 배포용이면 에러를 빈객체로 넣어준다.
// 즉, 실제 서비스되는 페이지면 404와 에러 메시지들이 안 뜬다. 빈 객체이니까.
// 그렇게 하는 이유가 이 두개의 부분이 노출되면 보안에 위협이 될 수도 있다고 그랬지?
// 에러 메시지도 너무 자세히 나오면 보안에 위협이 될 수 있다.
// 그래서 배포시에는 빈객체, 개발시에는 디버깅 편하게 해야되니까 다 보여주는 식으로한다.
res.status(err.status || 500); // 404 에러인지 500 에러인지 구분해준다.
res.render('error'); // 마지막에 에러 랜더링을 한다. 넌적스면 error.확장자(html로 설정했으면 html, njx로 설정했으면 njx, pug사용했으면 pug)
// 즉, error.html or error.njx or error.pug 페이지 찾아 랜더링
});
// 몇 번 포트에서 서버를 실행할지 지정한다.
app.listen(app.get('port'), () => {
console.log(app.get('port'), '번 포트에서 대기 중');
});
- 코드 질문 -
const Sequelize = require('sequelize');
const env = process.env.NODE_ENV || 'development';
const config = require('../config/config.json')[env];
const db = {};
// 하나의 노드에서 여러개의 MySQL에 연결 가능. 따로따로. 아래와 같이.
// 실제로 이렇게 데이터베이스를 여러개 갖고가는 경우도 많음.
const sequelize = new Sequelize(config.database, config.username, config.password, config);
const sequelize2 = new Sequelize(config.database, config.username, config.password, config);
db.sequelize = sequelize;
module.exports = db;
7.6 시퀄라이즈 모델 만들기
7.6.1 모델 생성하기
저희가 명령 프롬프트(cmd) 창에서 CREATE TABLE ~~ 엄청 길게 작성했던 명령어 있잖아요?
이게 방법이 3가지가 있습니다.
- 명령 프롬프트 창에서 만드는거.
- 워크벤치로 만드는거.
- 모델이란걸 통해서 만드는거.
아래는 공식문서에서 하라는 그대로 적용한 코드입니다.
- 사용자 모델 -
- 테이블에 대응되는 시퀄라이즈 모델 생성
저는 노드로 시퀄라이저를 사용해서 할 때는 이 모델이란걸 만들어서 코딩을 합니다.
// models/user.js
const Sequelize = require('sequelize');
// User: 모델이름 적어주시고.
// 시퀄라이즈에서 모델이 MySQL에선 테이블입니다. 용어만 조금 구분을 해주시면됩니다.
module.exports = class User extends Sequelize.Model {
// static init이란걸 class 안에 하나 만들어줍니다.
static init(sequelize) {
// return super.init도 만들어줍니다.
// 기본 형태가 이렇다고 보시면 됩니다.
// super.init의 첫번째 인자는 컬럼을 정의합니다.
// 두번째 인자는 모델에 대한 설정을 정의합니다.
return super.init({
// super.init에다 컬럼들을 정의할 수 있습니다.
// name, age, married, comment, created_at 컬럼 이름들입니다.
// 시퀄라이즈도 MySQL처럼 자료형, 옵션들을 다 제공하긴 하지만 한가지 조금씩 다른점이 있습니다.
// 예를 들어 id가 다릅니다.
id: {
// MySQL에선 INT였는데 시퀄라이즈에선 INTEGER라고 적어줍니다.
type: Sequelize.INTEGER,
primaryKey: true,
autoIncrement: true,
},
// 이렇게 원래 id를 넣어줘야하는데 시퀄라이즈는 id를 자동으로 넣어주기 때문에 id는 생략 가능합니다.
// 위 코드가 없어도 id가 자동으로 생성됩니다.
name: {
// 그리고 MySQL에선 VARCHAR였는데 시퀄라이즈에선 STRING
type: Sequelize.STRING(20),
// allownull: false는 NOT NULL을 뜻함
allowNull: false,
// unique: true는 UNIQUE INDEX를 뜻함
unique: true,
},
age: {
// type: Sequelize.TINYINT.UNSIGNED, 이렇게 설정해도 됨.
type: Sequelize.INTEGER.UNSIGNED,
allowNull: false,
},
married: {
// 시퀄라이즈에선 BOOLEAN이고 MySQL에선 TINYINT였죠?
// 그래서 코딩할 때 true, false로 작성합니다.
type: Sequelize.BOOLEAN,
allowNull: false,
},
comment: {
type: Sequelize.TEXT,
allowNull: true,
},
created_at: {
// MySQL에선 DATETIME이었는데 시퀄라이즈에선 DATE
// MySQL에서 DATE라면 시퀄라이즈에선 DATEONLY
type: Sequelize.DATE,
allowNull: false,
// MySQL에선 DEFAULT now(); 시퀄라이즈에선 아래와 같이
defaultValue: Sequelize.NOW,
},
// 두번째 인자는 모델에 대한 설정
}, {
// 시퀄라이즈에선 두개를 기본적으로 더 넣어줍니다.
sequelize,
timestamps: false, // timestamps 기본값은 true. true면 createdAt이랑 updatedAt 두개를 넣어줍니다.
// createdAt과 updatedAt의 좋은점은 저희가 생성할 때 createdAt이 자동으로 생성이 되고 (now())
// updatedAt도 또한 자동으로 수정한 시간으로 바뀝니다.
// 시퀄라이즈에서 timestamps를 true로 하면 제공하는 기능이거든요?
// 그런데 이번 예제에서는 그 기능을 잠깐 끄고 createdAt을 직접 구현해본겁니다.
// 다음 예제부턴 이 기능을 true로 해서 사용해볼겁니다.
underscored: false, // underscored는 시퀄라이즈의 글자들을 created_at 이렇게할지 아니면 createdAt 이렇게 할지.
// 어 지금 underscored: false인데 위에 created_at 이렇게해도되요? 라고 하실 수 있는데
// 위의 created_at은 저희가 직접 만들어줘서 가능합니다.
// 자동으로 만들어주는 애들(createdAt, updatedAt 등등)..
// 만약 underscored: true에 timestamps:true라면 created_at, updated_at 이렇게 컬럼을 만들어줍니다.
// 나중에 foreign key도 snake_case로 만들어줍니다.
// 이것은 취향 차이라고 보시면 됩니다.
// 시퀄라이즈에선 관습상 modelName을 아래와 같이 단수, 첫글자 대문자로 작성하고
// 모델이름은 자바스크립트상에서 사용할 이름
// 자바스크립트에선 모델이름만 씀.
modelName: 'User',
// tableName은 modalName과 똑같이. 그리고 복수형으로. 그리고 소문자로 작성합니다.
// 테이블이름은 실제 SQL상에서 사용할 이름
tableName: 'users',
paranoid: false, // paranoid: true이면 deletedAt을 만들어줍니다.
// deletedAt은 제거한 날짜. 어? 제거한 row는 그냥 지워버리면되지 왜 제거한 날짜를 기록하죠? 라고 생각하실 수도 있는데 제가 위에서 말씀드렸죠?
// 회원 정보 같은 경우는 3년, 5년... 이렇게 저장하는 경우가 있는데,
// 중간에 회원들이 내 정보 복구해달라고하면, DB에서 한번 지워버리면 그거 복구하는 거 정말 골치아프거든요?
// 그래서 삭제할 때 제거하는게 아니라 deletedAt: true로 만들어놓습니다.
// 그럼 얘는 그냥 삭제된거다 라고 치는거에요.
// 이를 soft delete 라고 합니다.
// 반대로 row 자체를 실제로 날려버리는거는 hard delete라고 합니다.
// 여튼 paranoid: true로 설정하면 soft delete 기능을 사용할 수 있다.
// 보통 회원정보.. 약관 같은데서 몇년동안 정보를 저장하고 있겠다. 그런 약관이 정해져있으면 paranoid: true를 해서 soft delete 기능을 켜놓죠.
// charset: 'utf8mb4' 이거하면 이모티콘도 쓸 수 있음
// collate: 'utf8mb4_general_ci', 이거하면 이모티콘도 쓸 수 있음
charset: 'utf8',
collate: 'utf8_general_ci',
});
}
static associate(db) {
db.User.hasMany(db.Comment, {foreignKey: 'commenter', sourceKey: 'id'});
}
};
위와 같이 자료형을 표현하는 코드에있어서 조금씩 차이가 있습니다.
왜 이렇게 조금씩 다르냐면 시퀄라이즈는 MySQL, MSSQL, Postgre, MariaDB, Oracle 등등이 가능은 하거든요?
여러개의 DB를 동시에 지원하려고 하다보니까 이런 문구들이 조금씩 다릅니다.
이게 DB마다 표현하는 방식이 조금 달라서 MySQL에만 맞춰져있는 게 아닙니다.
- 댓글 모델 -
// models/comment.js
const Sequelize = require('sequelize');
module.exports = class Comment extends Sequelize.Model {
static init(sequelize) {
return super.init({
// 여기보시면 commenter가 없습니다.
// id는 자동 생성해주는데 댓글에서 commenter가 없습니다.
// commenter는 시퀄라이즈에서 관계 컬럼이라고 해가지고 특별하게 따로 만들어주는게 있습니다.
comment: {
type: Sequelize.STRING(100),
allowNull: false,
},
created_at: {
type: Sequelize.DATE,
allowNull: true,
defaultValue: Sequelize.NOW,
},
}, {
sequelize,
timestamps: false,
modelName: 'Comment',
tableName: 'comments',
paranoid: false,
charset: 'utf8mb4',
collate: 'utf8mb4_general_ci',
});
}
static associate(db) {
db.Comment.belongsTo(db.User, { foreignKey: 'commenter', targetKey: 'id' });
}
};
여기까지 일단 설정해주시면 될거같습니다.
그렇게 하셨으면 아래와 같이 require해옵니다.
// models/index.js
const Sequelize = require('sequelize');
const User = require('./user');
const Comment = require('./comment');
const env = process.env.NODE_ENV || 'development';
const config = require('../config/config.json')[env];
const db = {};
const sequelize = new Sequelize(config.database, config.username, config.password, config);
db.sequelize = sequelize;
db.User = User;
db.Comment = Comment;
// init 메소드를 호출하면서 인자값으로 sequelize를 넣어줍니다.
// sequelize는 연결 객체거든요?
// 연결 객체를 init 메소드에 넣어준다라는 뜻은 static init(sequelize) {} 이 부분
User.init(sequelize);
Comment.init(sequelize);
module.exports = db;
즉, 위 부분을 통해 모델이랑 MySQL을 시퀄라이즈를 통해 연결한겁니다.
이렇게 연결 객체를 통해 연결까지 해주시면됩니다.
지금 저희가 시퀄라이즈를 통해서 모델(테이블)을 만들고 연결을 해보는 중입니다.
7.6.2 모델 옵션들
-
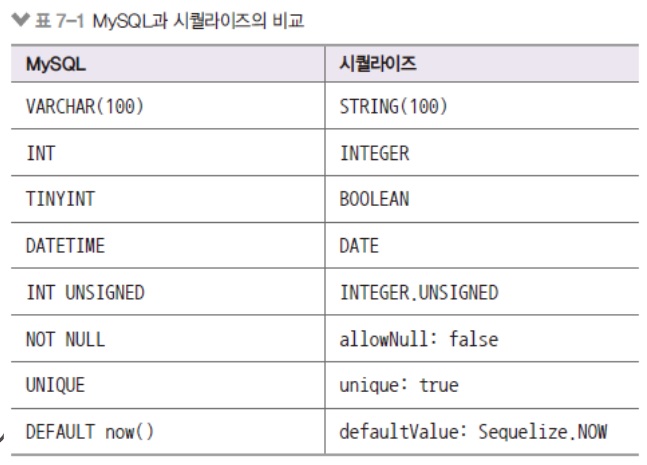
시퀄라이즈 모델의 자료형은 MySQL의 자료형과는 조금 다름
-
define 메소드의 세번째 인자는 테이블 옵션
- timestamps: true면 createdAt(생성시간), updateAt(수정시간) 컬럼을 자동으로 만듦
- 예제에서는 직접 created_at 컬럼을 만들었으므로 false로 함
- paranoid 옵션은 true이면 deletedAt(삭제시간) 컬럼을 만듦. row 복구를 위해 완전히 삭제하지 않고 deletedAt에 표시해둠.
- underscored 옵션은 케멀케이스로 생성되는 컬럼을 스네이크케이스로 생성
- modelName은 모델 이름, tableName 옵션은 테이블 이름을 설정
- charset과 collate는 한글 설정을 위해 필요(이모티콘 넣으려면 utf8mb4로)
7.6.3 댓글 모델 생성하기
코멘트 테이블 위에 생성했었죠? 다시 복습.
- comment.js 생성
// models/comment.js
const Sequelize = require('sequelize');
// Comment: 모델이름 - MySQL에선 테이블
// 시퀄라이즈에서 모델이 MySQL에선 테이블이다. 용어만 조금 구분을 해주시면된다.
module.exports = class Comment extends Sequelize.Model {
// static 메소드 init이란걸 하나 만들어준다.
static init(sequelize) {
// super <- 부모 클래스의 init 메소드를 return 한다.
// 기본 형태이다.
// super.init의 첫번째 인자는 컬럼을 정의한다. 두번째 인자는 모델에 대한 설정을 정의한다.
return super.init({
// 여기보시면 commenter가 없습니다.
// id는 자동 생성해주는데 댓글에서 commenter가 없습니다.
// commenter는 시퀄라이즈에서 관계 컬럼이라고 해가지고 특별하게 따로 만들어주는게 있습니다.
comment: {
type: Sequelize.STRING(100), // MySQL에선 VARCHAR 였는데, 시퀄라이즈에선 STRING이다.
allowNull: false, // NOT NULL을 뜻한다.
},
created_at: {
type: Sequelize.DATE, // MySQL에선 DATETIME이었는데 시퀄라이즈에선 DATE이다.
// MySQL에서 DATE라면 시퀄라이즈에선 DATEONLY이다.
allowNull: true, // NOT NULL을 뜻한다.
defaultValue: Sequelize.NOW, // MySQL에선 DEFAULT now(); 시퀄라이즈에선 아래와 같다.
},
}, {
// 두번째 인자. 모델에 대한 설정을 하는 부분이다.
sequelize,
timestamps: false, // timestamps 기본값은 true이다. true면 createdAt이랑 updatedAt 두개를 자동으로 넣어준다.
// createdAt과 updatedAt의 좋은점은 저희가 생성할 때 createdAt이 자동으로 생성이 되고 (now())
// updatedAt 또한 자동으로 수정한 시간으로 바뀐다.
// 시퀄라이즈에서 timestamps를 true로 하면 제공하는 기능들이다.
// 그런데 이번 예제에선 그 기능을 잠깐 끄고 createdAt을 직접 구현해본 것이다.
// 다음 예제부턴 이 기능을 true로 해서 사용해볼 것이다.
modelName: 'Comment', // 시퀄라이즈에선 관습상 modelName을 왼쪽과 같이 단수, 첫글자 대문자로 작성한다.
// 모델 이름은 자바스크립트상에서 사용할 이름이다.
// 자바스크립트에선 모델 이름만 쓴다.
tableName: 'comments', // tableName은 modelName과 똑같이, 그리고 복수형으로, 그리고 소문자로 작성한다.
// 테이블 이름은 실제 SQL상에서 사용할 이름이다.
paranoid: false, // paranoid: true이면 deletedAt을 만들어준다.
// deletedAt은 제거한 날짜.. 어? 제거한 row는 그냥 지워버리면되지 왜 제거한 날짜를 기록하지? 라고 생각하실 수 있는데 제가 위에서 말씀드렸죠?
// 회원 정보 같은 경우는 3년, 5년... 이렇게 저장하는 경우가 있는데,
// 중간에 회원들이 내 정보 복구해달라고하면, DB에서 한번 지워버리면 그거 복구하는 거 정말 골치아프거든?
// 그래서 삭제할 때 제거하는게 아니라 deletedAt: true로 만들어 놓는다.
// 그럼 얘는 그냥 삭제된거다 라고 치는거에요.
// 이를 soft delete라고 한다.
// 반대로 row 자체를 실제로 날려버리는거는 hard delete라고 한다.
// 여튼 paranoid: true로 설정하면 soft delete 기능을 사용할 수 있다.
// 보통 회원정보.. 약관 같은데서 몇년동안 정보를 저장하고 있겠다. 그런 약관이 정해져있으면 paranoid: true를 해서 soft delete 기능을 켜놓는다.
charset: 'utf8mb4', // charset: 'utf8mb4' 이거하면 이모티콘도 쓸 수 있음
collate: 'utf8mb4_general_ci', // collate: 'utf8mb4_general_ci', 이거하면 이모티콘도 쓸 수 있음
});
}
static associate(db) {
db.Comment.belongsTo(db.User, {foreignKey: 'commenter', targetKey: 'id'});
}
};
7.6.4 댓글 모델 활성화하기
-
index.js에 모델 연결 (이것도 복습)
- init으로 sequelize와 연결
- associate로 관계 설정
// models/index.js
const Sequelize = require('sequelize');
const User = require('./user');
const Comment = require('./comment');
const env = process.env.NODE_ENV || 'development';
const config = require('../config/config.json')[env];
const db = {};
const sequelize = new Sequelize(config.database, config.username, config.password, config);
db.sequelize = sequelize;
db.User = User;
db.Comment = Comment;
User.init(sequelize);
Comment.init(sequelize);
// 이렇게 associate도 미리 넣어둬도 됩니다.
// 이는 조금 이따 설명드리도록 하겠습니다.
User.associate(db);
Comment.associate(db);
module.exports = db;
7.7 테이블 관계 이해하기
7.7.1 관계 정의하기
테이블간 관계는 세가지 관계가 있습니다.
- 1:1 관계
- N:M 관계
- 1:N 관계
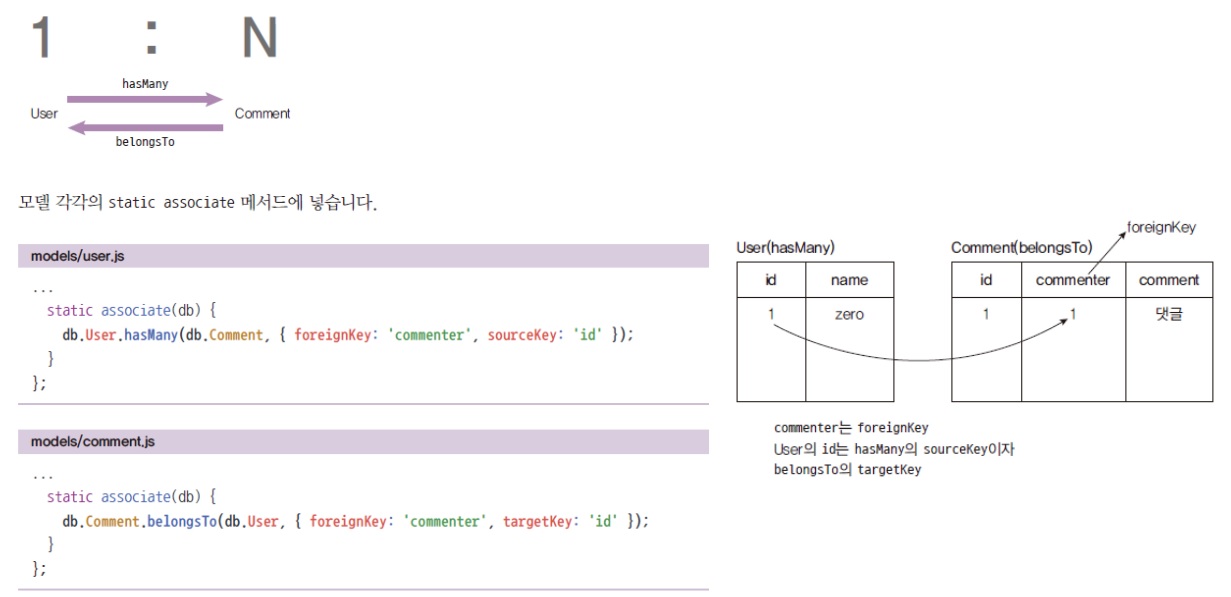
- 1:N 관계 -
-
사용자, 댓글 - 사용자 1명이 여러 댓글을 작성할 수 있습니다.
댓글, 사용자 - 댓글 하나에 사용자가 여러명일 수 없습니다.
사용자는 여러 댓글을 작성할 수 있지만 댓글에는 작성자 한명만 있어야됩니다. -
사용자, 게시글 - 사용자 1명이 여러 게시글을 작성할 수 있다.
반면 게시글은 작성자가 1명뿐이어야 한다.
물론 공동집필 같은 경우에는 게시글 하나에 여러 작성자가 존재할 수 있다.
- N:M 관계 -
다대다 관계는 자주 나옵니다.
인스타그램을 생각해보시면 게시글과 헤시태그가 있습니다.
게시글 하나에 해시태그를 엄청나게 많이 달아놓잖아요?
자기 포스트 검색 잘돼라고 해시태그를 많이 달아놓으면 일단 게시글 하나가 해시태그를 여러개 가질 수 있다라는 거죠?
우선 1대다 관계가 생깁니다.
반대로 해시태그 @노드 검색하면 해당 해시태그가 달려있는 게시글들이 쫙 뜨죠?
즉 해시태그 하나도 다양한 게시글들을 가지고 있는겁니다.
이를 다대다 관계라고 합니다.
-
다대다 관계
- 예) 게시글과 해시태그 테이블
-
하나의 게시글이 여러 개의 해시태그를 가질 수 있고 하나의 해시태그가 여러 개의 게시글을 가질 수 있음
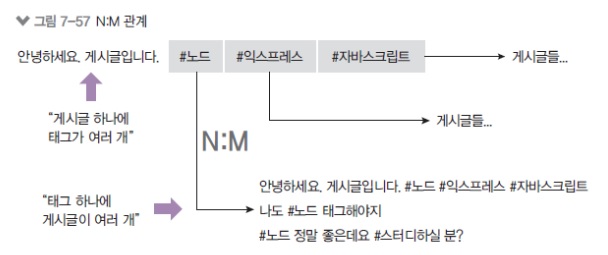
-
DB 특성상 다대다 관계는 중간 테이블이 생김
// 중간 테이블의 이름을 through로 정해줍니다. // 다대다 관계는 hasOne, hasMany 이런게 없고 둘 다 belongsToMany입니다. // 누가 주체이냐 이런게 없기 때문에 다 belongsToMany. db.Post.belongsToMany(db.Hashtag, { through: 'PostHashtag' }); db.Hashtag.belongsToMany(db.Post, { through: 'PostHashtag' });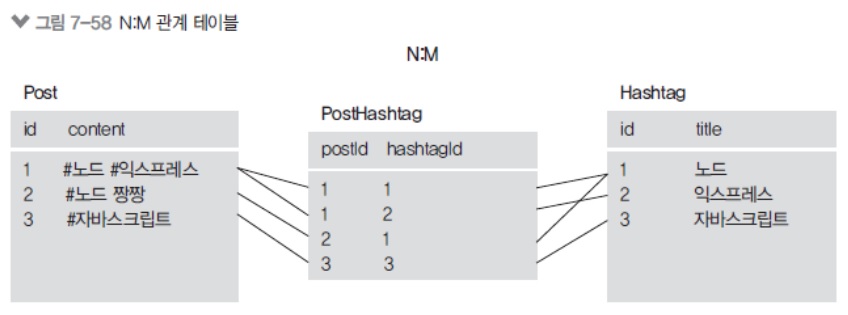 Tip
Tip사용자 테이블과 사용자 정보 테이블 1대1 관계에서 다대다 관계를 넣을 땐 보통 사용자 테이블에 넣습니다.
사용자 정보 테이블엔 보통 다대다 관계를 형성을 안합니다.
주체가 되는 사용자 테이블과 다른 테이블들을 보통 관계를 맺습니다.만약 댓글 테이블이 있는데 댓글 테이블과 사용자 테이블을 1:N 관계를 맺지 사용자 정보 테이블과 댓글 테이블을 1:N 관계를 맺지 않습니다.
사용자 정보 테이블에도 그런걸 연결해놓으면 복잡해지기 때문에 사용자 테이블에만 댓글, 해시태그 이런 테이블들과 관계를 연결해놓습니다.즉, 복잡도를 줄이기 위해 사용자 테이블에만 댓글, 해시태그 테이블 이런 1대N 관계를 연결해놓는다는 것. 사용자 정보 테이블엔 연결X 연결하면 복잡해짐
다대다 관계로가면 중간 테이블이 생기는게 어쩔 수 없는게, 여러분들이 하려고 생각해보시면 안된다는 것을 아실 수가 있는게
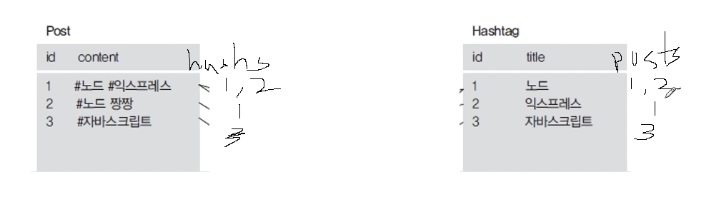
이렇게 중간 테이블 없이 콤마(,)로 구분해 연결시키면 되는 거 아니야? 라고 생각하실 수도 있습니다.
되긴하는데 이는 데이터베이스의 컬럼 만드는 원칙을 위반한겁니다.
이전에 말씀드린 정규화 위반입니다.
어떤 점에서 위반이냐면- 컬럼에는 한가지의 데이터만 들어있어야 합니다.
예를 들어, 해시태그 컬럼에는 한 가지의 데이터만 들어있어야하는데 위와 같이하면 Post 테이블의 hashs 컬럼에 1, 2.. 이렇게 2가지가 들어있게 됩니다.
hashtag 테이블의 posts 컬럼에도 1, 2 이렇게 하나의 컬럼에 2가지의 데이터가 담깁니다. 그 이상이 담기기도 하구요.
컬럼 하나엔 한가지 데이터만 들어가야하는 정규화 규칙을 위반했기 때문에 사실 이 방법은 안됩니다.
그래서 이를 해결하려고 온갖짓을 다하다보면 결국엔 PostHashtag 테이블을 만들어서 postId, hashtagId 컬럼에 1번 id에 1번 게시글 연결해주고 1번 게시글에 2번 해시태그 연결해주고..
이렇게 중간 테이블을 만들 수밖에 없습니다.그래서 이 중간 테이블은
SQL하실 때 처음으로 멘붕에 빠트리는 그런 건데, 시퀄라이즈를 쓰면 그나마 조금 편하게 하실 수 있습니다.
그런데 시퀄라이즈에 너무 적응되어있다가 나중에SQL에서 다대다 관계 만나면 쿼리문 까먹어서 대부분 못하시거든요.
그래서 너무 편한거에 익숙해지면 나중에 댓가를 치르게됩니다.- 배열로는 못넣나요?
- MySQL에 배열을 지원하긴 합니다. JSON.
그런데 배열이란걸 컬럼에 넣으면 정규화 위반입니다.
그런데 실무에선 항상 정규화 원칙에 따라서 하는게 아니라 정규화를 일부로 깨는 역정규화를 하다보면 배열도 사용할 수 있고 객체도 사용할 수 있고 그렇긴합니다.
하지만 저희는 지금 원칙을 따라야하기 때문에..
그래서 다대다 관계를 하려면 어쩔 수 없이 이렇게 중간 테이블이 나와야합니다.
- 컬럼에는 한가지의 데이터만 들어있어야 합니다.
- 1:1 관계 -
-
예) 사용자 테이블 vs 사용자 정보 테이블
db.User.hasOne(db.Info, { foreignKey: 'UserId', sourceKey: 'id' }); db.Info.belongsTo(db.User, { foreignKey: 'UserId', targetKey: 'id' });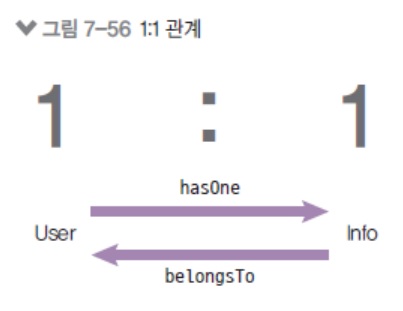
굳이 사용자 테이블과 사용자 정보 테이블을 나눠야 되는지 의문이실 수도 있습니다.
사용자 정보도 사용자 테이블에 넣어도 되지만 이를 이렇게 나누는 경우도 있습니다.
왜 나누냐면, 사용자 테이블에 컬럼이 아주 많으면 해당 컬럼을 검색하는데 시간이 오래 걸리기 때문에 자주 사용되는 정보들만 사용자 테이블에 넣어놓고 조금 덜 빈번하게 쓰이는 것들은 사용자 정보 테이블에 따로 또 넣어놓고..
그래서 빈번한 정도랑 중요도, 그 다음에 보안 위협성 이런 것 때문에 하나의 테이블을 일부로 두개로 쪼개는 경우도 많습니다.
그래서 이런건 하나의 테이블을 두개로 쪼갠거기 때문에 그 두 테이블의 관계는 1:1 관계이겠죠.
이런 경우엔hasOne과belongsTo.hasOne과belongsTo는 정말 헷갈리는게 반대로도 1:1 관계잖아요?
그럼 누가hasOne이되고 누가belongsTo가 되어야하나. 이것이 많이 헷갈리는데 이거는 저희가 정해야됩니다.
저희가 너는hasOne하고 너는belongsTo해라. 이렇게 임의로 정해야되는데 한 가지 선택의 기준은belongsTo에foreignKey컬럼이 들어간다고 했죠?
즉foreignKey가 누구한테 들어가는지를 생각하시고 정하시면 됩니다.// Info에 UserId라는 foreignKey가 생깁니다. db.Info.belongsTo(db.User, { foreignKey: 'UserId', targetKey: 'id' });// User에 UserId라는 foreignKey가 생깁니다. db.User.belongsTo(db.Info, { foreignKey: 'UserId', targetKey: 'id' });현재 문맥상 Info에 foreignKey(UserId)가 생기는게 맞겠죠?
User 테이블에 id가 있잖아요?
User 테이블에 id가 있는데 거기에 UserId까지 있으면 좀 이상하죠.- hasOne 또는 hasMany : sourceKey
- belongsTo : targetKey
- foreignKey : ‘다른 테이블'을 지칭하기보단 해당 컬럼의 이름을 뜻한다고 보면됨, 즉 belongsTo에 들어갈 컬럼의 이름.
- 관계 정의하기 -
-
users 모델과 comments 모델 간의 관계를 정의
- 1:N 관계(사용자 한명이 댓글 여러개 작성)
- 시퀄라이즈에서는 1:N 관계를
hasMany로 표현(사용자.hasMany(댓글)) - 반대의 입장에서는
belongsTo(댓글.belongsTo(사용자)) belongsTo가 있는 테이블에 컬럼이 생김(댓글 테이블에commenter컬럼)
- user 테이블 -
// models/user.js
const Sequelize = require('sequelize');
module.exports = class User extends Sequelize.Model {
static init(sequelize) {
return super.init({
name: {
type: Sequelize.STRING(20),
allowNull: false,
unique: true,
},
age: {
type: Sequelize.INTEGER.UNSIGNED,
allowNull: false,
},
married: {
type: Sequelize.BOOLEAN,
allowNull: false,
},
comment: {
type: Sequelize.TEXT,
allowNull: true,
},
created_at: {
type: Sequelize.DATE,
allowNull: false,
defaultValue: Sequelize.NOW,
},
}, {
sequelize,
timestamps: false,
underscored: false,
modelName: 'User',
tableName: 'users',
paranoid: false,
charset: 'utf8',
collate: 'utf8_general_ci',
});
}
static associate(db) {
// User가 Comment를 많이 갖고있다는 뜻임
// foreignKey: User의 foreignKey면 내가 아니라 남이잖아요? 즉 User 입장에서 남이면 Comment죠?
// Comment의 commenter라는 컬럼이 내 sourceKey - id를 참조하고 있다 이렇게 보시면 됩니다.
// sourceKey가 나, foreignKey가 남.
db.User.hasMany(db.Comment, { foreignKey: 'commenter', sourceKey: 'id' }); // 정리하자면 User의 id를 Comment 테이블의 commenter라는 남의 컬럼이 참조하고 있다.
// '내'가 누군지 '남'이 누군지를 정확히 파악할 필요가 있습니다.
}
};
- comment 테이블 -
// models/comment.js
const Sequelize = require('sequelize');
module.exports = class Comment extends Sequelize.Model {
static init(sequelize) {
return super.init({
comment: {
type: Sequelize.STRING(100),
allowNull: false,
},
created_at: {
type: Sequelize.DATE,
allowNull: true,
defaultValue: Sequelize.NOW,
},
}, {
sequelize,
timestamps: false,
modelName: 'Comment',
tableName: 'comments',
paranoid: false,
charset: 'utf8mb4',
collate: 'utf8mb4_general_ci',
});
}
static associate(db) {
// Comment 테이블은 User에게 속해있다.
// belongsTo에선 sourceKey가 아니라 targetKey이다. target, 즉 남의 키.
// foreignKey는 대신 똑같습니다. User 테이블 입장에서도 foreignKey는 commenter이고 Comment 테이블 입장에서도 foreignKey는 commenter이다.
// 다만, commenter 컬럼은 어떤 테이블에 추가되느냐. belongsTo가 있는 테이블에 컬럼으로 추가된다.
// db.Comment.belongsTo(db.User, { foreignKey: 'commenter', targetKey: 'id', onDelete: 'cascade', onUpdate: 'cascade' });
// 이렇게 옵션을 더 추가할 수도 있는데 여기선 굳이 사용하지 않습니다.
db.Comment.belongsTo(db.User, { foreignKey: 'commenter', targetKey: 'id' });
}
};
7.8 시퀄라이즈 쿼리 알아보기
시퀄라이즈가 자바스크립트문을 SQL로 바꿔준다고 했습니다.
-
윗 줄이 SQL문, 아랫 줄은 시퀄라이즈 쿼리(자바스크립트)
INSERT INTO nodejs.users (name, age, married, comment) VALUES ('zero', 24, 0, '자기소개1');const {User} = require("../models"); // User.create()는 Promise입니다. // 아래 나오는 findAll() 메소드도 Promise입니다. // 그래서 앞에 await 붙여주셔야됩니다. 또는 뒤에 then 붙이시거나. 그래야 결과값 받아오실 수 있다는 것. User.create({ name: "zero", age: 24, married: false, // MySQL에선 TINYINT라는 거 comment: "자기소개1", })SELECT * FROM nodejs.users;User.findAll({});SELECT name, married FROM nodejs.users;User.findAll({ attribuetes: ["name", "married"], }) -
특수한 기능들인 경우 Sequelize.Op의 연산자 사용(gt, or 등)
SELECT name, age FROM nodejs.users WHERE married = 1 AND age > 30;const {Op} = require("sequelize"); const {User} = require("../models"); User.findAll({ attributes: ["name", "age"], where: { married: true, // gt (greater than) // lt (little than) // gte (greater than equal) // lt (little than equal) // in [1, 2, 3] // ne 1 (= not equal 1) // ES6+ 문법 - 동적 프로퍼티 age: {[Op.gt]: 30}, } })SELECT id, name FROM users WHERE married = 0 OR age > 30;const {Op} = require("sequelize"); const {User} = require("../models"); User.findAll({ attributes: ["id", "name"], where: { [Op.or]: [{married: false}, {age: {[Op.gt]: 30}}] } }) -
ORDER
SELECT id, name FROM users ORDER BY age DESC;User.findALL({ attributes: ['id', 'name'], // order는 2차원 배열로 작성 // 왜 2차원 배열로 작성하냐면 정렬이라는게 여러가지 기준으로 할 수가 있거든요? // 그런데 같은 나이인 사람이 여러명인 경우에 두번째 조건으로 그 사람들을 나열할 수 있잖아요? // 나이가 같으면 생성일 순으로 정렬해라 그러면 이렇게 2차원 배열이 되어야 하는거죠. // 예) [['age', 'DESC'], ['createdAt', 'asc']] // 첫번째가 1순위 정렬, 두번째가 2순위 정렬 - 그래서 order는 기본적으로 2차원 배열로 작성. order: [['age', 'DESC']] })시퀄라이즈로 날짜 같은 것도 다 검사가 됩니다.
LIMIT로 조회할 개수 제한
SELECT id, name FROM users ORDER BY age DESC LIMIT 1;user.findAll({ attributes: ['id', 'name'], order: [['age', 'DESC']], limit: 1, })OFFSET으로 앞의 로우들 스킵 가능(OFFSET 2면 세번째 것부터 찾음)
SELECT id, name FROM users ORDER BY age DESC LIMIT 1 OFFSET 1;User.findAll({ attributes: ['id', 'name'], order: ['age', 'DESC'], limit: 1, offset: 1, }) -
수정
UPDATE nodejs.users SET comment='바꿀내용' WHERE id=2;User.update({ comment: "바꿀내용", }, { // where 꼭 적어주라고 했죠? // 시퀄라이즈에선 where를 안 적었을 때 어떻게 반응하는지 테스트를 해봐야될 거 같긴 한데, // 일단 MySQL에선 WHERE 작성 안하면 모든 데이터들이 UPDATE되기 때문에 난리가 납니다. // 제가 예상하기엔 시퀄라이즈는 where를 안 적으면 에러를 내서 막아줄거 같긴한데.. where: {id: 2}, }) -
삭제
DELETE FROM nodejs.users WHERE id=2;User.destroy({ // destroy도 조건이 있어야합니다. // 조건 제대로 설정 안했다가 테이블이 다 날라갈 수도 있습니다. // 정확히 뭘 지울지 조건을 설정해줍니다. where: {id: 2}, })
- in은 어떨때 쓸까? -
1, 2, 3번을 지울 때.
User.destroy({
where: { id: 1 }
})
User.destroy({
where: { id: 2 }
})
User.destroy({
where: { id: 3 }
})
위와 같이 작성하면 좀 낭비니깐 이럴 때는
User.destroy({
where: { id: { [Op.in]: [1, 3, 5] } }
})
이렇게 작성합니다.
User.destroy({
where: { id: { [Op.ne]: 5 } } // not equal
})
이렇게 작성되어있으면 5번 빼고 나머지 다 지워라. 이런 뜻.
시퀄라이즈 연산자 목록
-
공식문서 읽어보시는게 더 나으실 수도 있습니다.
7.9 관계 쿼리 알아보기
7.9.1 관계 쿼리 1
-
결과값이 자바스크립트 객체임
// 한명만 가져올 땐 findOne, 가장 먼저 선택되는거 갖고옴 // 다 가져올 땐 findAll const user = await User.findOne({}); console.log(user.nick); // 사용자 닉네임 -
include로 JOIN과 비슷한 기능 수행 가능(관계 있는 것을 엮을 수 있음)
제가 쓴 댓글들을 갖고 오고 싶다면?
MySQL에선JOIN을 활용해야하지만 시퀄라이즈에선 아래와 같이 작성하면됨.// 사용자 가져오면서 const user = await User.findOne({ // Comment까지 갖고옵니다. include: [{ model: Comment }] }) // 왜 Comments이냐 // hasMany 관계이기 때문. 사용자는 여러개 댓글을 작성할 수 있음 // 시퀄라이즈가 1대다, 다대다, 1대1에 따라 단수형, 복수형을 알아서 바꿔줌 console.log(user.Comments); // 사용자 댓글 -
다대다 모델은 다음과 같이 접근 가능
db.sequelize.models.PostHashtag
7.9.2 관계 쿼리 2
-
get+모델명으로 관계 있는 데이터 로딩 가능const user = await User.findOne({}); // 아까 위에선 include로 가져왔는데 아래처럼 가져오는 방법도 있음 const comments = await user.getComments(); console.log(comments); // 사용자 댓글저는
get+모델명,include방법 중에서include를 많이 사용하는데,include하면 성능상 문제가 생길 수 있습니다.
왜냐하면,// 사용자 가져오면서 const user = await User.findOne({ // Comment까지 갖고옵니다. include: [{ model: Comment }] }) console.log(user.Comments); // 사용자 댓글사용자를 가져오면서 동시에 댓글까지 다 가져와야되니까 동시에 갖고오기 위해선 데이터베이스가 조금 더 일을 많이해야겠죠?
const user = await User.findOne({}); // 아까 위에선 include로 가져왔는데 아래처럼 가져오는 방법도 있음 const comments = await user.getComments(); console.log(comments); // 사용자 댓글얘는 데이터베이스에 요청은 두번보냅니다.
User.findOne({});으로 사용자 한번 가져오고
user.getComments();데이터베이스 한번 더 요청해서 댓글만 다시 가져오고..각각 장단점이 있습니다.
- 한번 요청해서 동시에 다 가져올건지.. 대신에 데이터베이스는 둘 다 찾아야하기 때문에 머리가 아플 것이고.
- 요청을 두번 보내서 사용자 가져오고 댓글을 따로 가져오고 할건지.
이거는 무조건 뭐가 더 낫다가 아니라 둘 다 해보면서 어떤게 성능이 더 좋은지 찾아보셔야합니다.
요청을 더 보낸다고 해서 성능이 안좋거나 그런게 아니라 이거는 진짜 비교를 해보셔야합니다.const user = await User.findOne({}); // 아까 위에선 include로 가져왔는데 아래처럼 가져오는 방법도 있음 const comments = await user.getComments(); console.log(comments); // 사용자 댓글그리고
getComments에서 난 Comments 부분이 싫다 하시면 이 부분을 바꾸실 수 있거든요?// 사용자 가져오면서 const user = await User.findOne({ // Comment까지 갖고옵니다. include: [{ model: Comment }] }) console.log(user.Comments); // 사용자 댓글또는
user.Comments로 나오는게 싫다.
이런 부분은 아래as로 이름을 바꿀 수 있습니다. -
as로 모델명 변경 가능// 관계를 설정할 때 as로 등록 db.User.hasMany(db.Comment, { foreignKey: 'commenter', sourceKey: 'id', as: 'Answers' }); // 쿼리할 때는 const user = await User.findOne({}); const comments = await user.getAnswers(); console.log(comments); // 사용자 댓글위와 같이
getAnswers로 바뀌고, include인 경우도 마찬가지.
user.Answers로 바뀜.그런데
as로 바꾸면 헷갈리니깐 자주 쓰는건 권장드리지 않습니다.// 사용자 가져오면서 const user = await User.findOne({ // Comment까지 갖고옵니다. include: [{ // 아래 Comment는 Comment라 적어주셔야합니다. as로 바꿨다고해서 바꾼걸 적어주시면 안됩니다. // 왜냐면 Answers라는 모델은 존재하지 않기 때문입니다. // 이 자리는 모델자리이거든요. model: Comment }] }) // Answers로 바꿨다면 아래 코드에서 user.Answers로 바꿔주면된다. console.log(user.Comments); // 사용자 댓글 -
include나 관계 쿼리 메서드에도where나attributesconst user = await User.findOne({ // 사용자의 id가 1인것을 원하면 include 바깥인 이 위치에 where를 넣어주셔야함 // 사용자의 id만 불러오겠다 한다면 이 위치에 attributes 설정 include: [{ // 댓글의 id가 1인걸 원할 때 (댓글의 id가 1인것과 사용자의 id가 1인것은 완전히 다름) model: Comment, where: { id: 1, }, // 댓글 테이블에서 id 컬럼만 가져오겠다 라는 뜻 attributes: ['id'] }] }) // 또는 const comments = await user.getComments({ // 코드상으론 이게 더 직관적이긴 함 where: { id: 1, }, attributes: ['id'] }) -
생성쿼리
예를 들어 사용자를 먼저 만들고 그 사용자가 댓글을 쓰는 경우가 있습니다.
댓글을 쓸 때 2가지 방법이 있는데const comment = await Comment.create({ userId: 1 });이런 방법. 위와 같은 방법이 가장 자주 쓰이는 방법임.
위와 같이 작성하면 해당 댓글은 1번 사용자의 댓글이 됨.const user = await User.findOne({}); const comment = await Comment.create(); await user.addComment(comment); // 또는 await user.addComment(comment.id);가끔가다가 위 처럼 우선 빈 댓글 생성해주고 나중에 1번 사용자와 연결해주는 경우도 있습니다.
어떤 때에 그런지 도저히 감이 안오실 수도 있는데, 이게 댓글이 아니라 다른거면 이런 경우가 발생할 수도 있습니다.게임 아이템. 게임에서 아이템이 드롭이 됐습니다.
몬스터에서 아이템이 드롭되었는데 그럼 저희가 아이템 부터 생성을 해야겠죠?
그리고 그 아이템을 누가 줍느냐에 따라서 해당 아이템이 1번 사용자꺼가 될 수도 있고 2번 사용자 꺼가 될 수도 있고 그런 경우가 있겠죠.그래서 항상 어떤 데이터를 등록할 때, 그게 누구의 것인지 그때 바로 정해지는 것이 아니라 나중에 정해지는 케이스도 있습니다.
댓글이 아니라 게임 아이템이라고 생각하시면 좀 편할거에요.const user = await User.findOne({}); const comment = await Comment.create(); // 그런 경우엔 이와 같이 나중에 누구꺼인지 추가를 해주는데 이럴 때 add가 나옵니다. await user.addComment(comment); // 또는 await user.addComment(comment.id);위와 같이 addComment로 comment 자체를 넣어주거나 comment.id를 넣어주거나.
그러면 사용자와 댓글이 알아서 연결이돼서 저장됩니다.
- 중복데이터 값은 어떻게하나요? -
- foreign key, primary key, unique index 등등 이런 것들이 중복되는거를 막아줍니다.
예를 들어hasOne이어서 한 사람에 하나의 정보만 있어야되는데 그 사람에 다른 정보를 또 추가한다면 자동으로 시퀄라이즈에서 에러가 납니다.
정확히 말하면MySQL에서 에러가납니다.
MySQL에서 에러가 난거를 시퀄라이즈를 통해 노드로 갖다주거든요?MySQL이 이런 에러를 냈어 하면서.
여튼 foreign key, primary key, unique index 이런거 설정하면 다 알아서 걸러줍니다.
- 다시 관계쿼리 -
-
여러 개를 추가할 때는 배열로 추가 가능
const user = await User.findOne({}); const comment1 = await Comment.create(); const comment2 = await Comment.create(); await user.addComment([comment1, comment2]); -
수정은
set+모델명, 삭제는remove+모델명
이게 일부로 단어를 좀 달리만든거 눈치채셨나요?
원래 USER CREATE, USER FIND, USER UPDATE, USER DESTROY 이렇게 4개가 있잖아요?
그런데 관계 쿼리에서는user add, user get, user set, user remove 이렇게 일부로 단어를 덜 헷갈리라고 단어들을 달리 만들었습니다.
그런데 이게 오히려 더 헷갈릴 수도 있습니다.
7.9.3 raw 쿼리
나는 도저히 시퀄라이즈 어려워서 못 써먹겠다.
그럼 시퀄라이즈를 쓰셔도 아래와 같이 쿼리문으로 작성하실 수 있습니다.
그래서 굳이 시퀄라이즈 지우실 필요는 없습니다.
-
직접 SQL을 쓸 수 있음
const [result, metadata] = await sequelize.query('SELECT * from comments'); console.log(result);
제 생각엔 시퀄라이즈는 모델 관리할 때 좋습니다.
모델에 작성되어있는거 보고 자동으로 테이블 생성해주고 그런거?
시퀄라이즈 문법으로 꼭 작성 안하더라도 테이블(모델) 연결할 때 시퀄라이즈로 연결해두시고 쿼리는 위 코드처럼 MySQL문법으로 날려도 충분할 거 같습니다.
7.10 시퀄라이즈 실습하기
-
https://github.com/hyungju-lee/node-study/tree/master/ch7/7.6/learn-sequelize
프런트 코드 복사
-
프론트 코드보다는 서버 코드 위주로 보기
-
프론트 코드는 서버에 요청을 보내는 AJAX 요청 위주로만 파악
// routes/index.js const expres = require("express"); const User = require("../models/user"); const router = express.Router(); router.get('/', async (req, res, next) => { try { const users = await User.findAll(); res.render('sequelize', {users}); } catch (err) { console.error(err); next(err); } }) module.exports = router;
-
패키지 버전 업데이트 방법
- npm outdated로 확인
- 최신버전으로 package.json 상에서 수정
- npm update 실행
실습 전에 생성한 테이블들은 모두 지워야됨.
지우는 방법
- 워크벤치
- 테이블 우클릭 DROP TABLE
- 참조하는 테이블부터 지우기 - 참조받는 테이블은 다른 테이블의 참조를 받고있으므로 안지워질 수 있음.
참조 관계에 있는 테이블은 참조하는 테이블부터(belongsTo) 지워야함.
- 데이터베이스 시퀄라이즈로 만드는 방법 -
npx sequelize db:create
위 명령어를 입력하면 아래 config/config.json 파일을 참고하여 데이터베이스를 만들어줍니다.
{
"development": {
"username": "root",
"password": "",
"database": "nodejs",
"host": "127.0.0.1",
"dialect": "mysql"
},
"test": {
"username": "root",
"password": null,
"database": "database_test",
"host": "127.0.0.1",
"dialect": "mysql"
},
"production": {
"username": "root",
"password": null,
"database": "database_production",
"host": "127.0.0.1",
"dialect": "mysql"
}
}
- 테이블 생성법 -
app.js가 실행되어 sequelize.sync() 코드가 실행되면 테이블(모델)이 만들어짐.
npm start
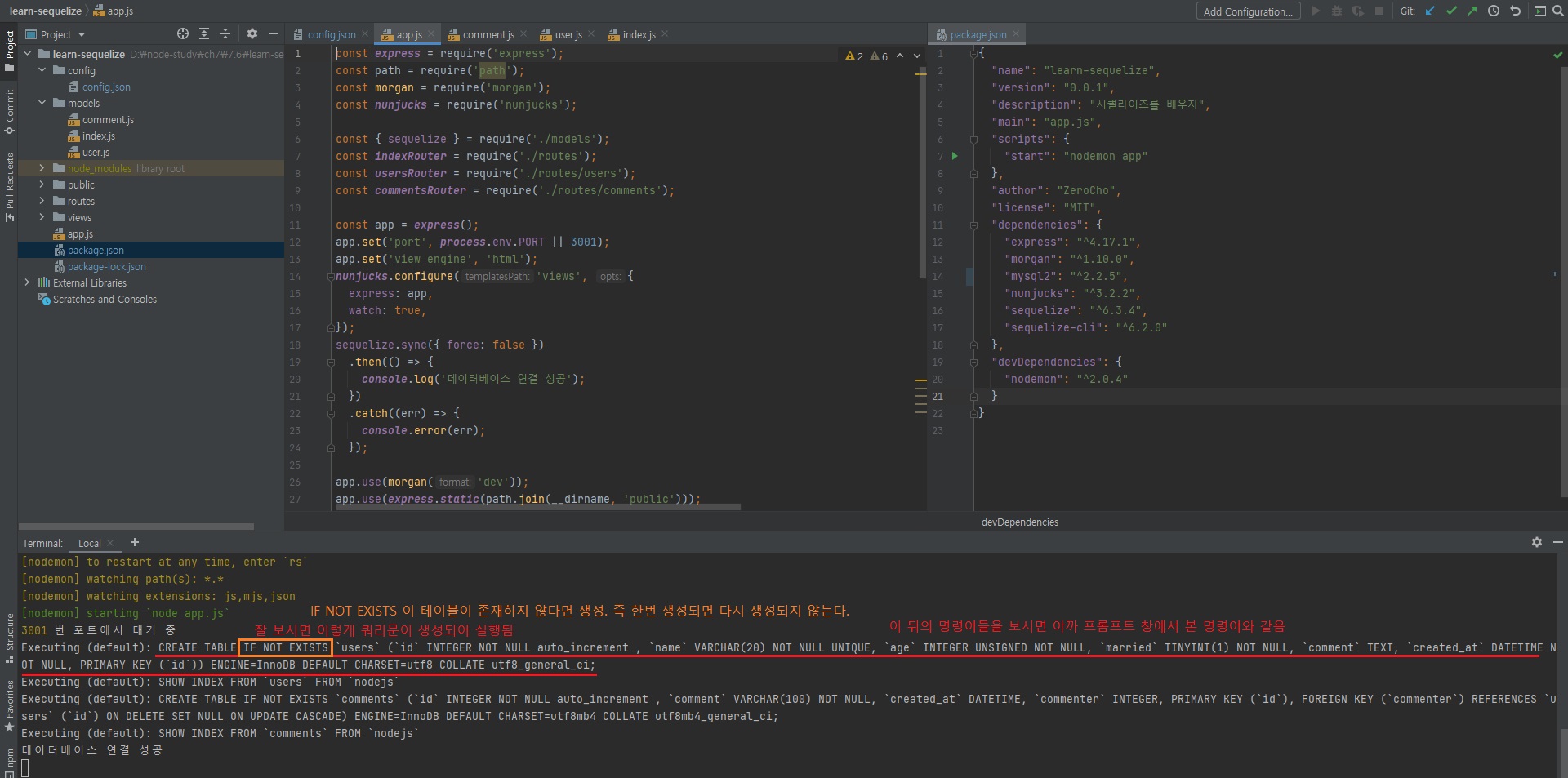
이렇게 시퀄라이즈가 모델들 코드를 통해 자동으로 테이블까지 생성해줍니다.
이렇게 워크벤치에서 테이블이 생성된걸 확인할 수 있습니다.
스페너 버튼을 누르면 해당 테이블이 어떤 형태로 생성되었는지를 확인할 수 있습니다.
그리고 옆에 표 모양을 누르면 실제 엑셀처럼 확인하실 수 있습니다.
워크벤치 쓰시는게 데이터베이스 초기에는 SQL에 대한 감도 잡을 수 있고 좋습니다.
- 실습 -
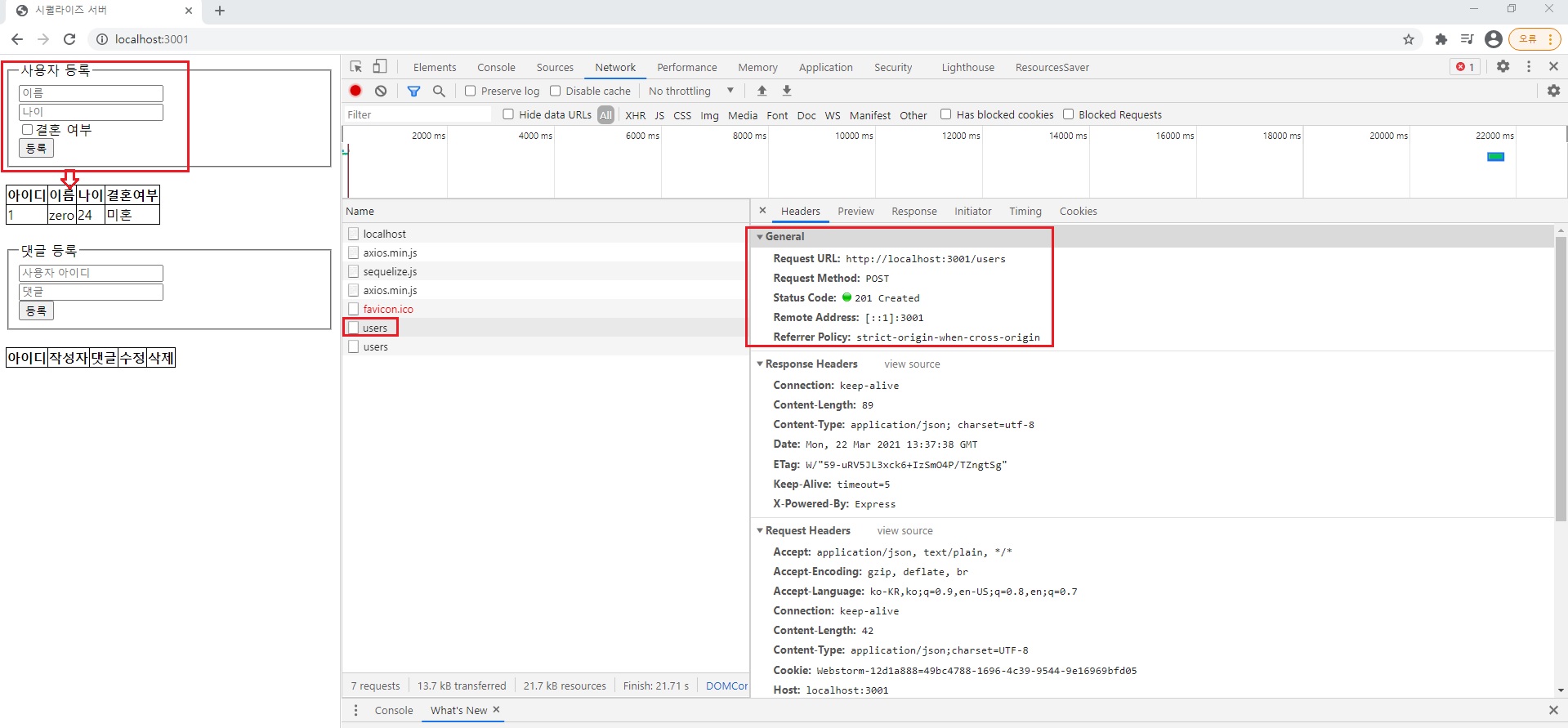
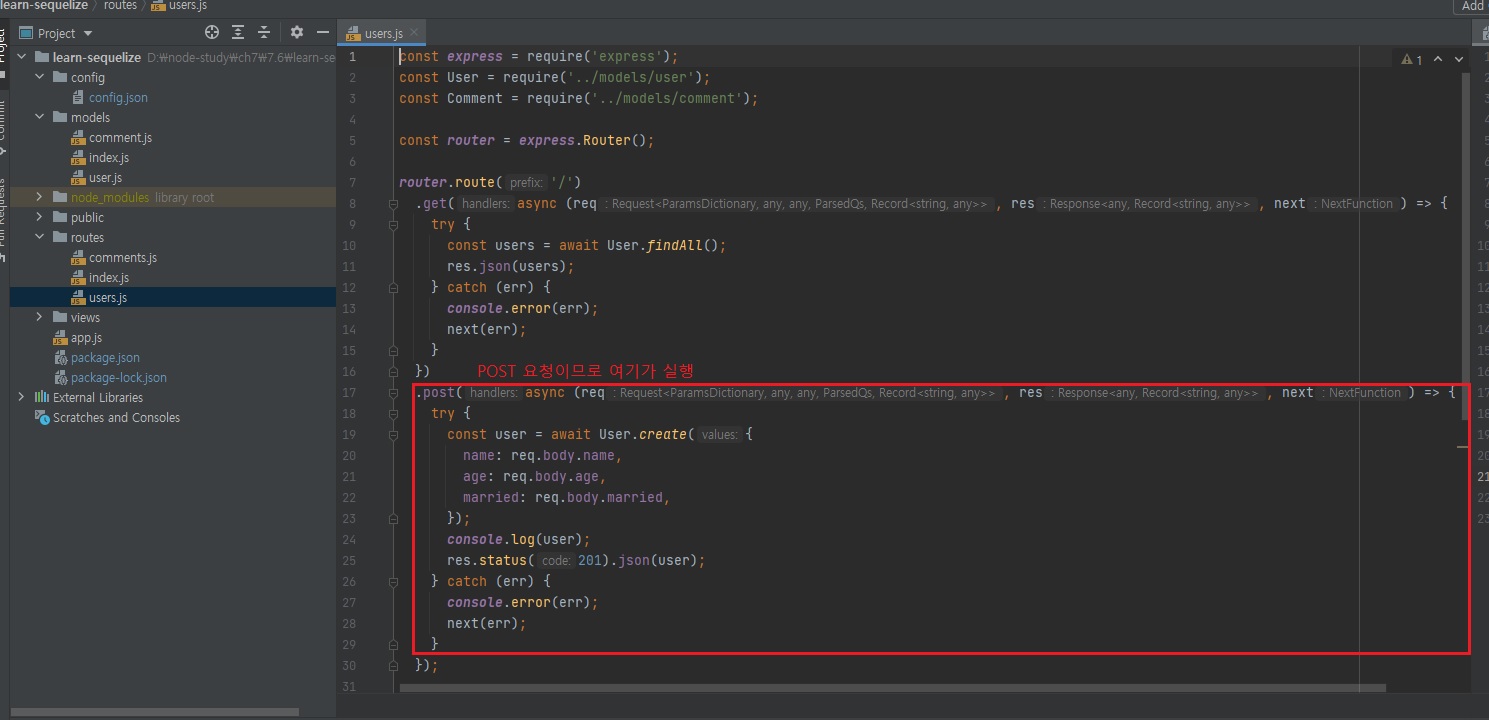
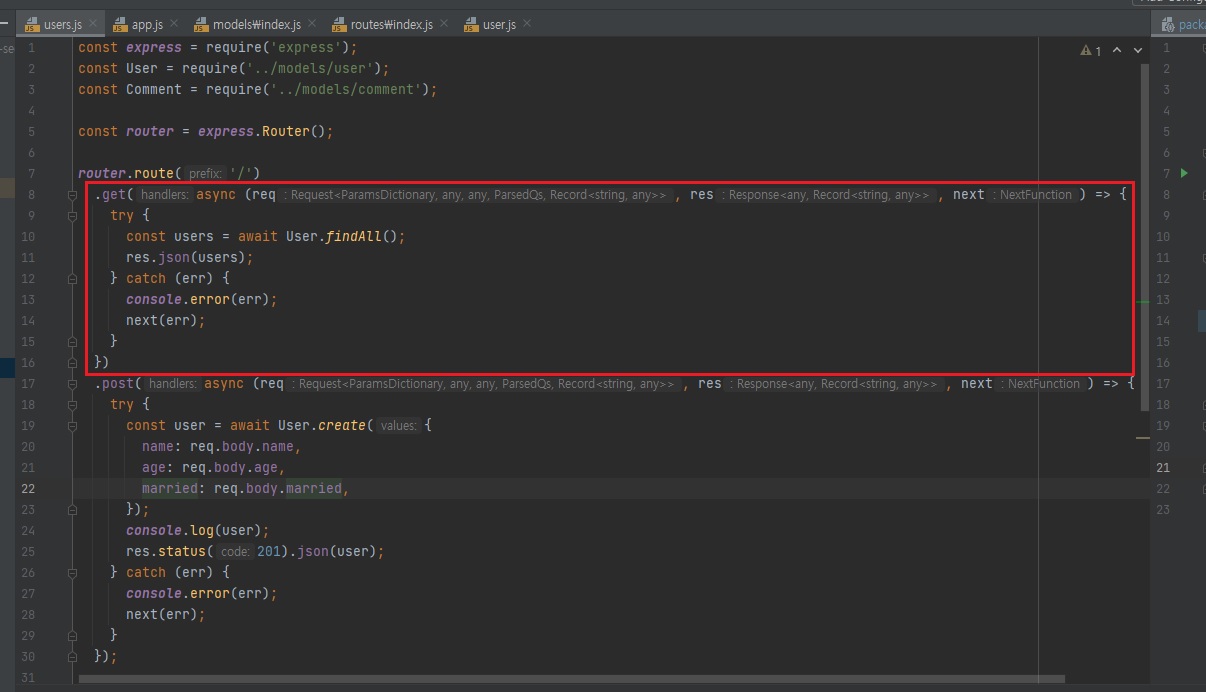
GET/users하면 위 코드부분이 실행.
페이지를 보내는게 아니라면 보통 json을 쓴다고 보면됩니다.
단순한 문자열 보낼 때는 send 또는 binary.
0, 1 이런 데이터 보낼 때는 send를 쓰고 파일을 보낼 땐 sendFile 쓰고 템플릿 엔진 렌더링할 땐 render 사용하고 그 외 API에서 JSON 같은 거 보낼 때는 다 json.
API 서버는 거의 다 JSON이라고 보시면 됩니다.
API 관련해선 10장에서 나가도록 하겠습니다.
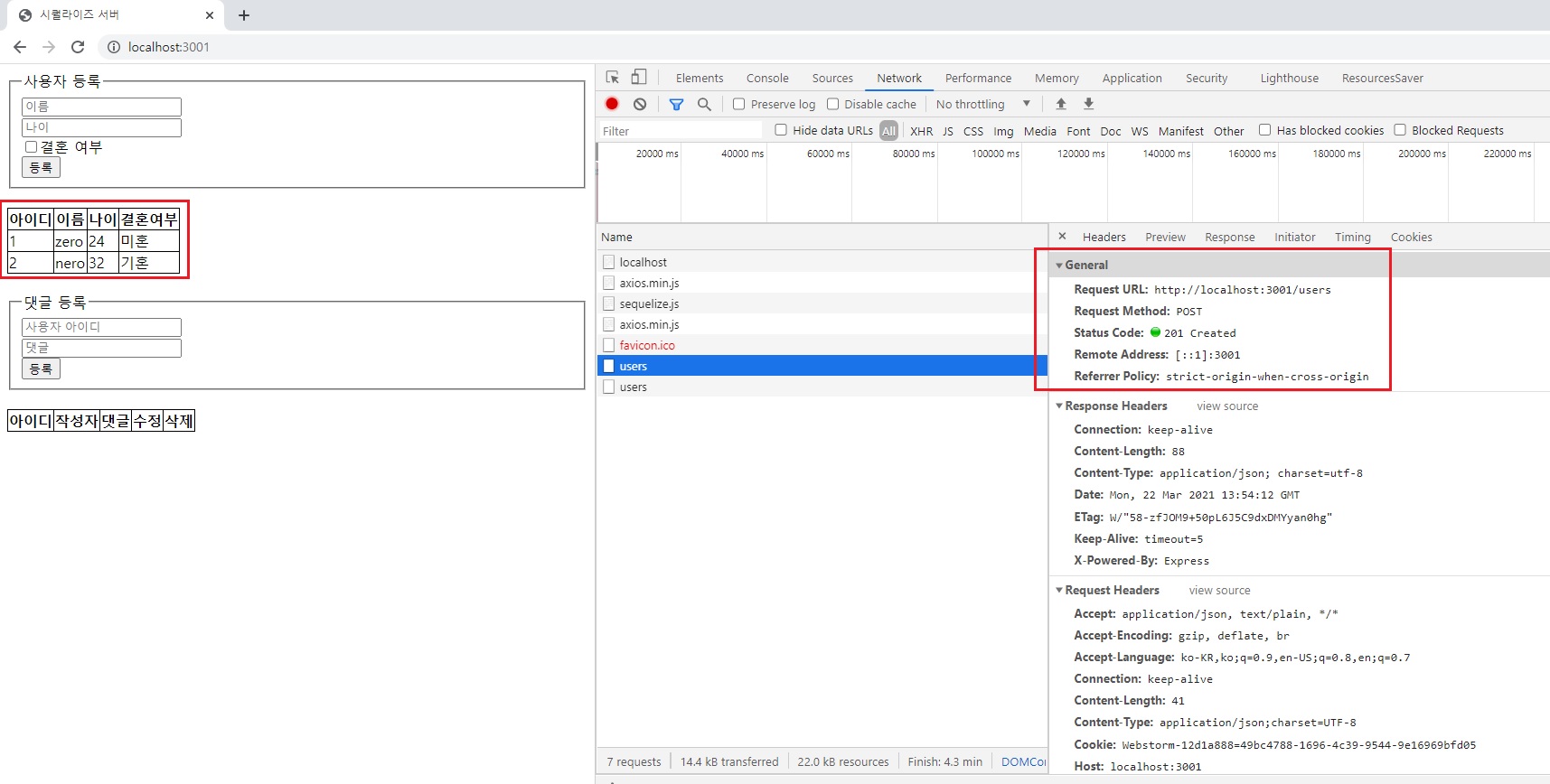
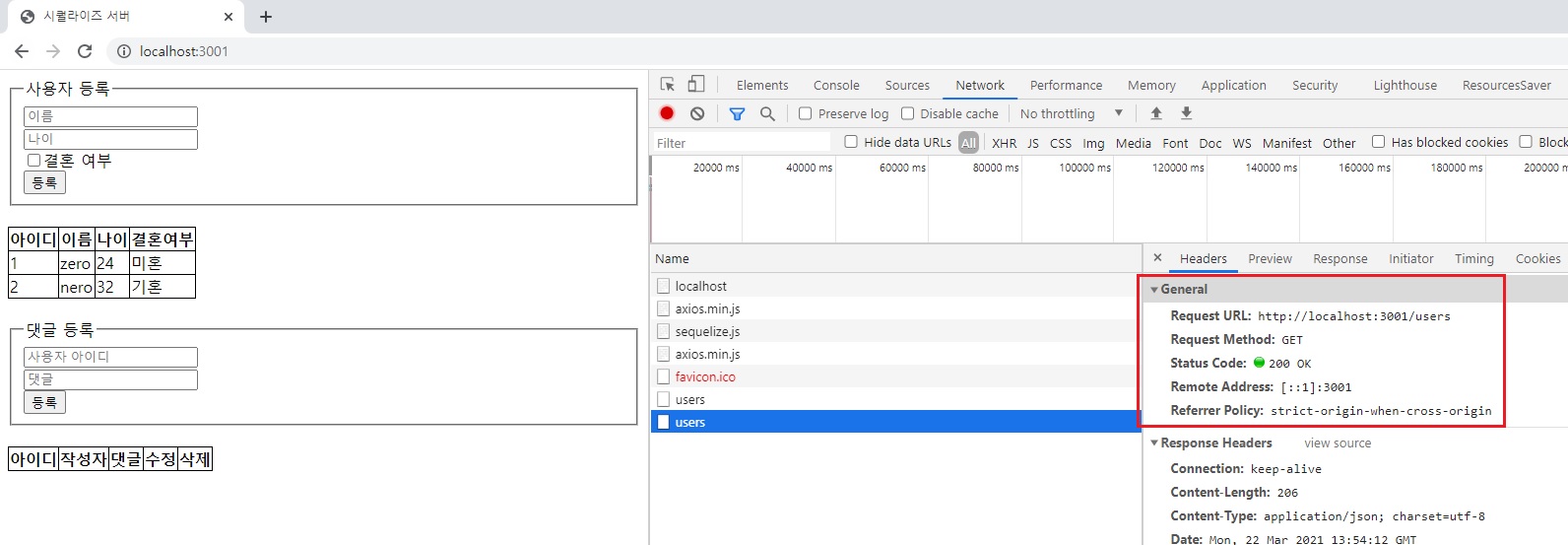
POST 요청한 다음에 바로 GET 요청보내도록 함.
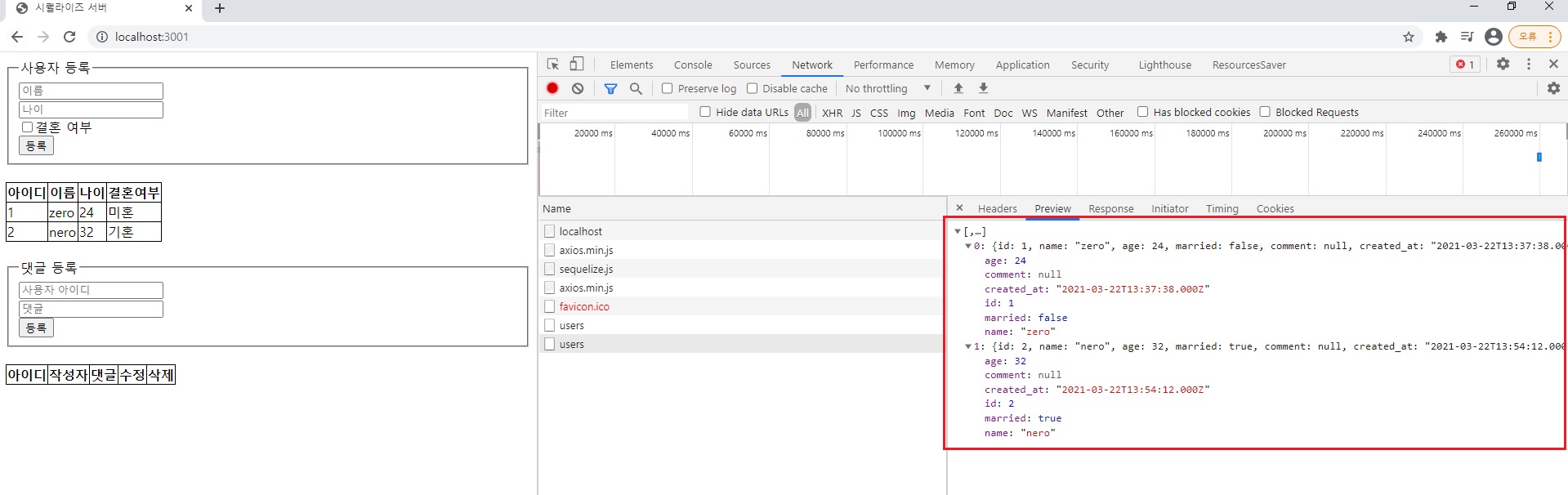
GET 요청을 하면 이렇게 데이터가 온 것을 볼 수 있음.
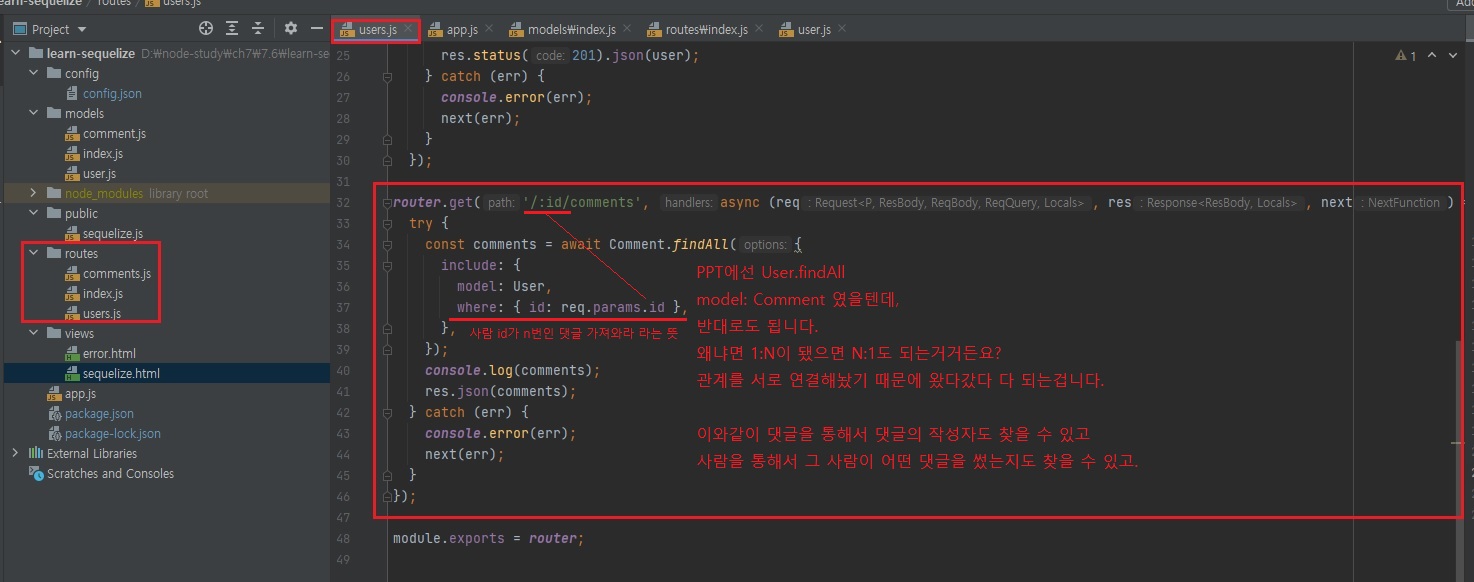
이거는 어떤 사람의 댓글을 가져오는 코드입니다.
예를 들어 id가 1번인 사람의 댓글을 불러오면 zero의 댓글들이겠죠?
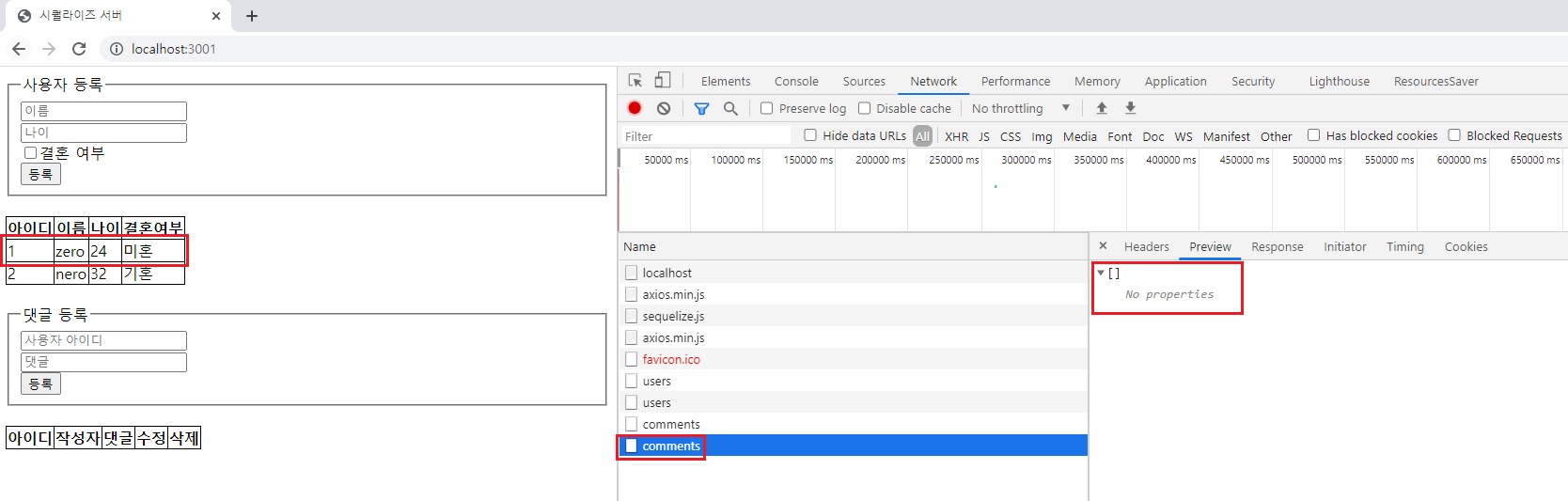
zero를 눌러보면 아무런 데이터도 반환되지 않습니다.
아직은 댓글을 작성한게 없기 때문에.
(click 이벤트 핸들러 함수 등록되어있음.)
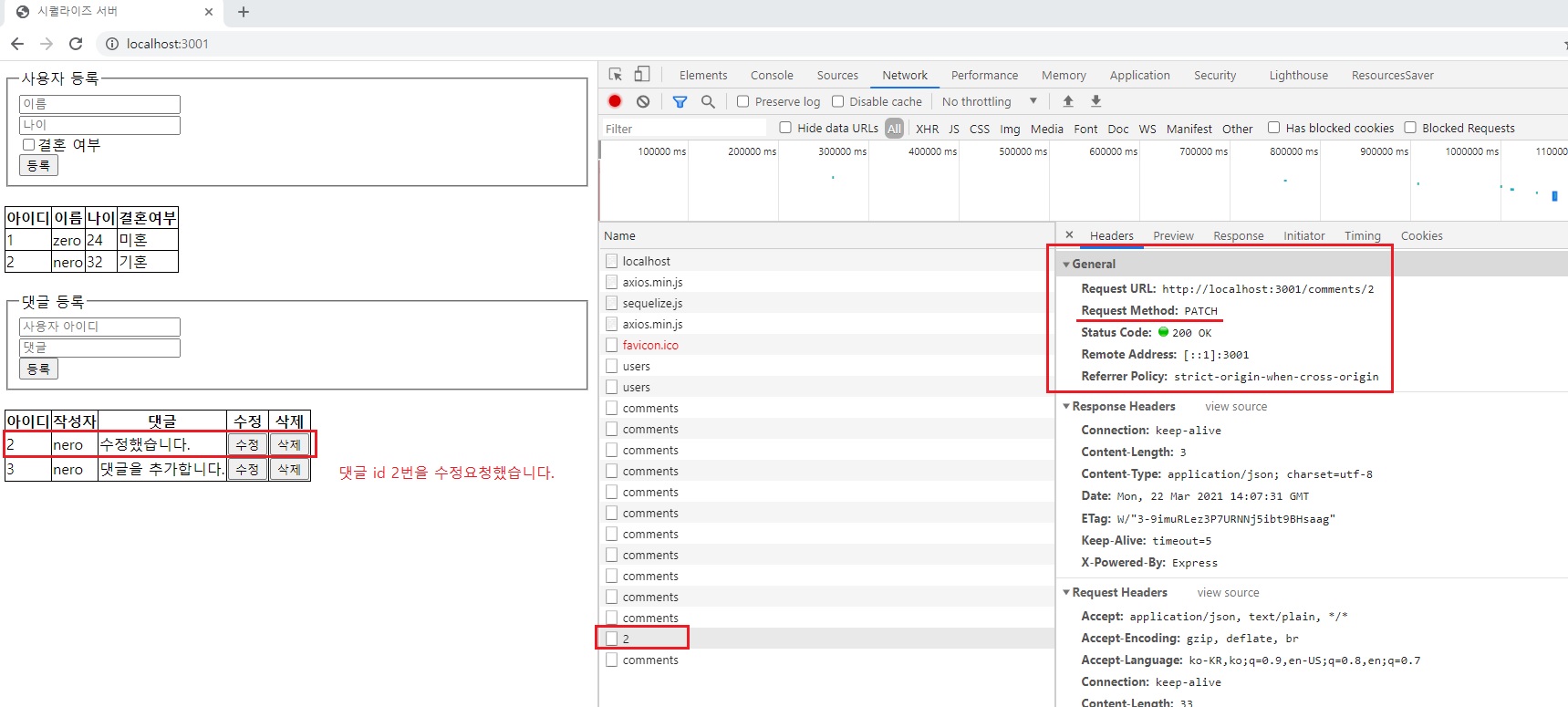
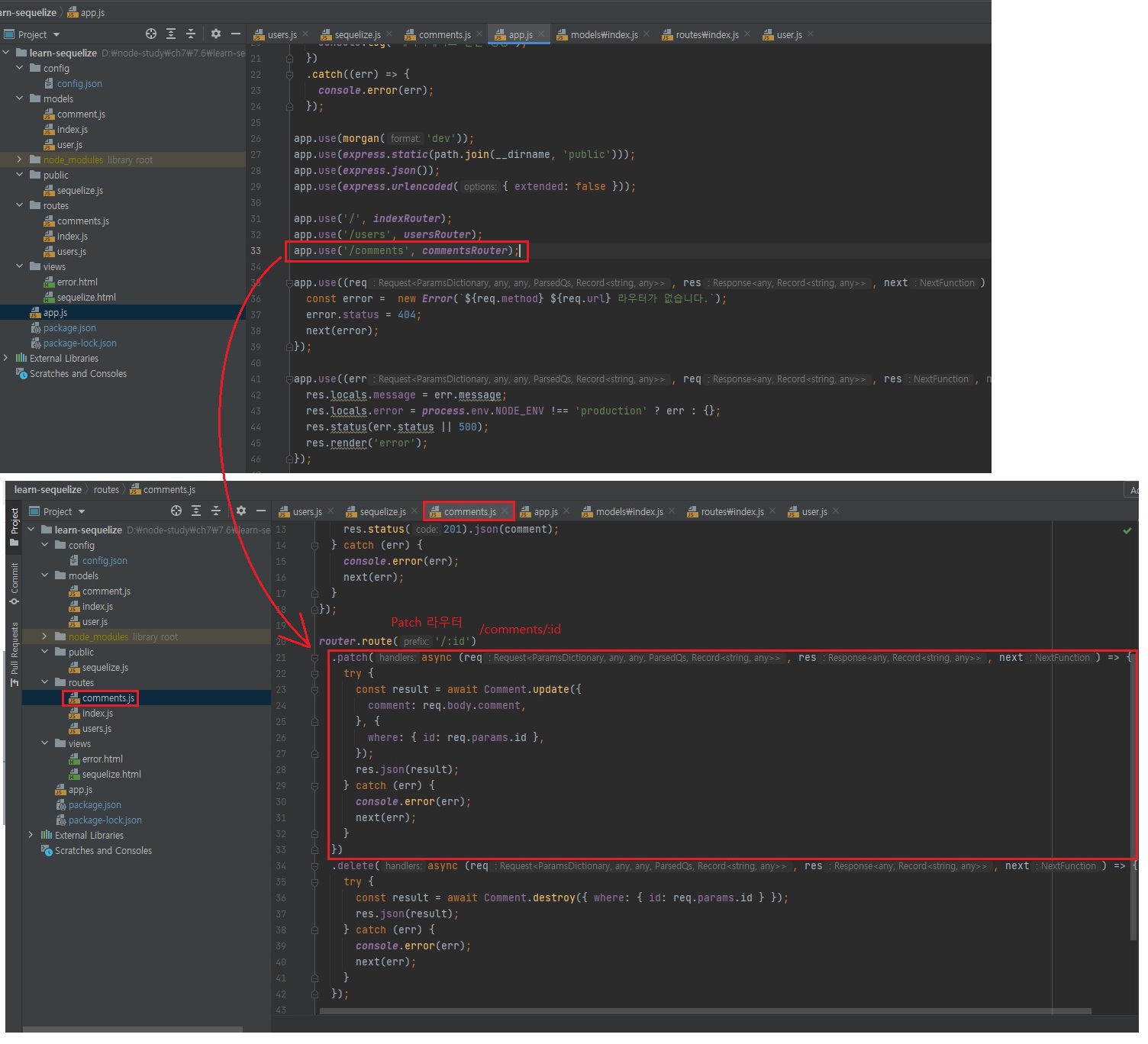
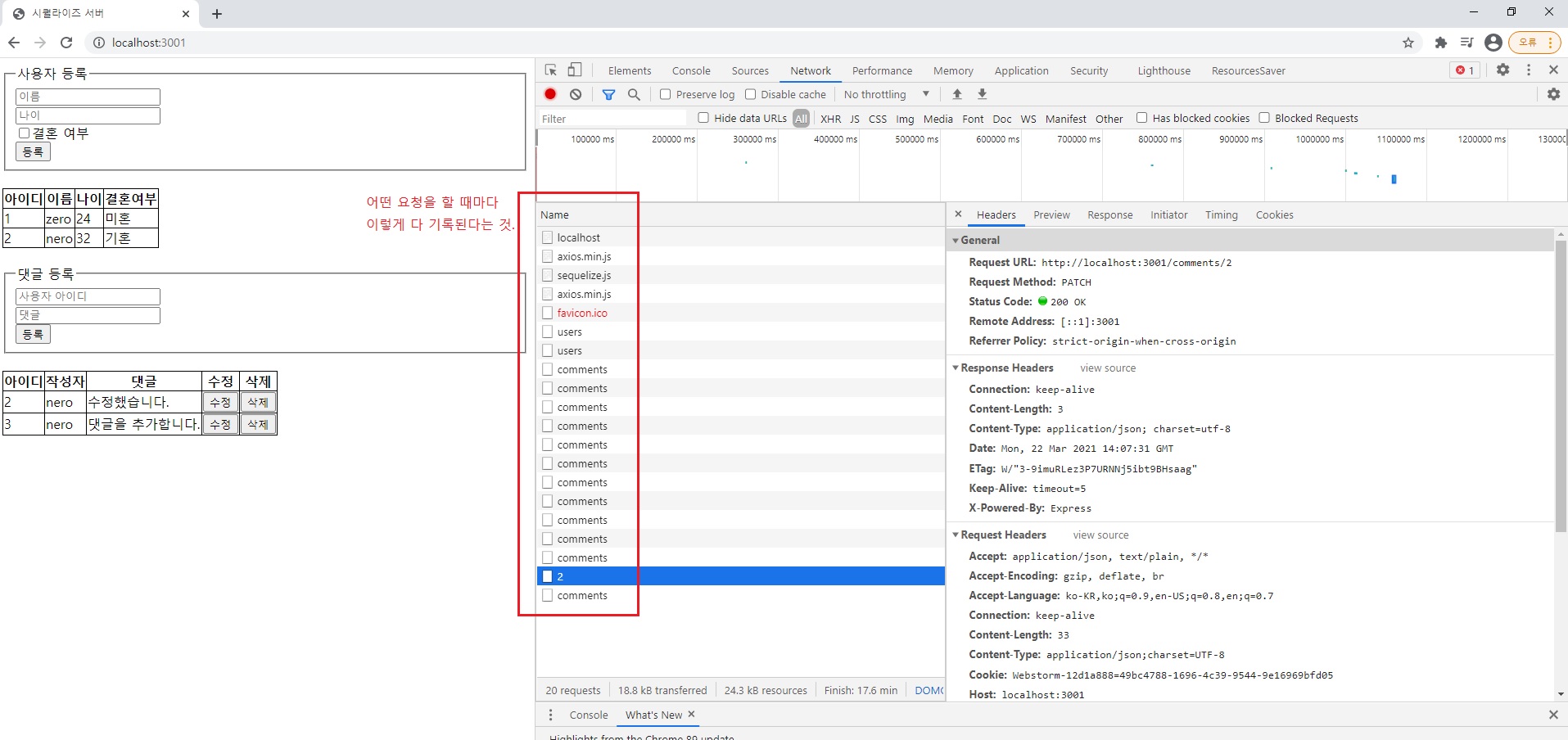
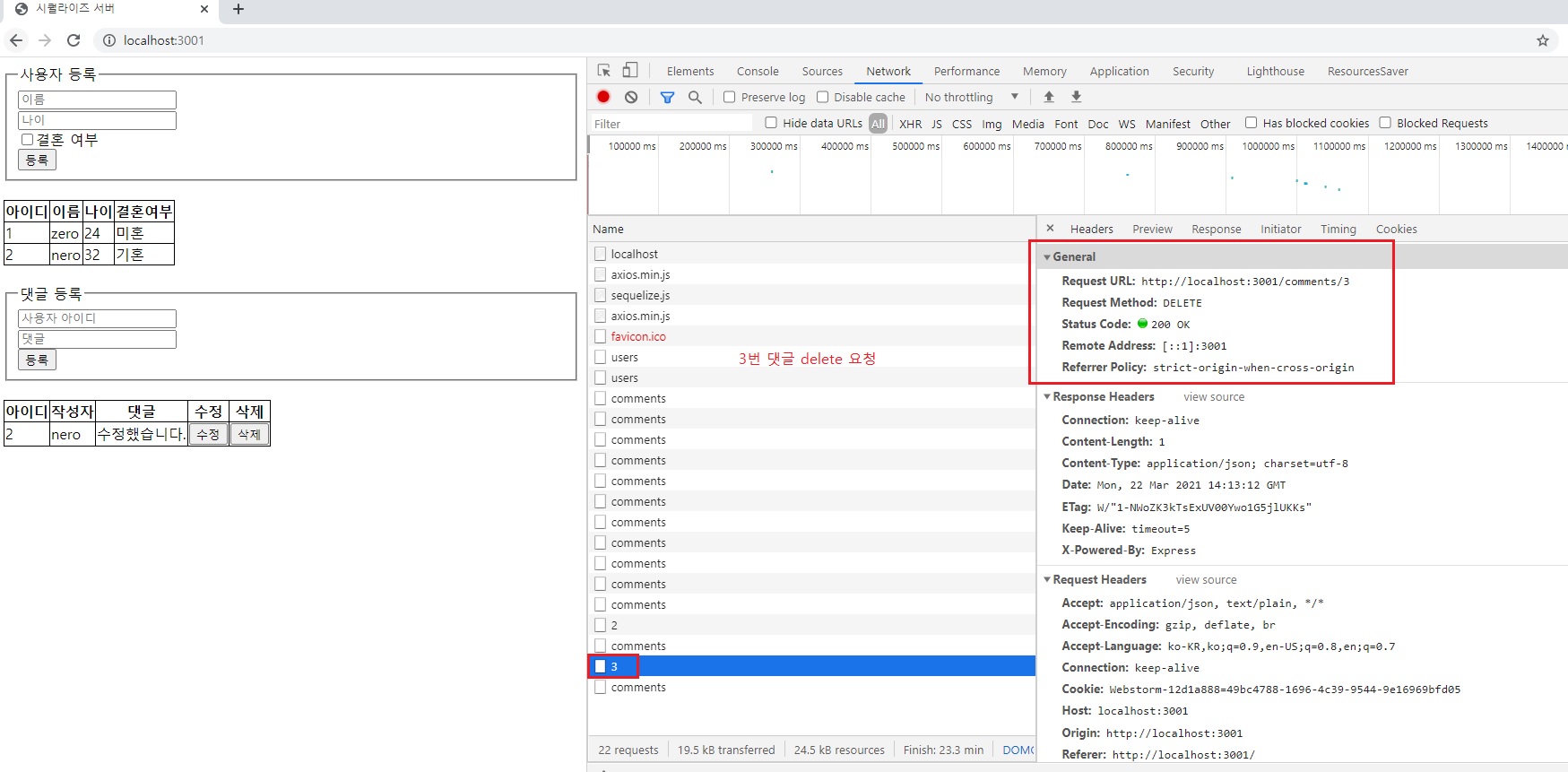
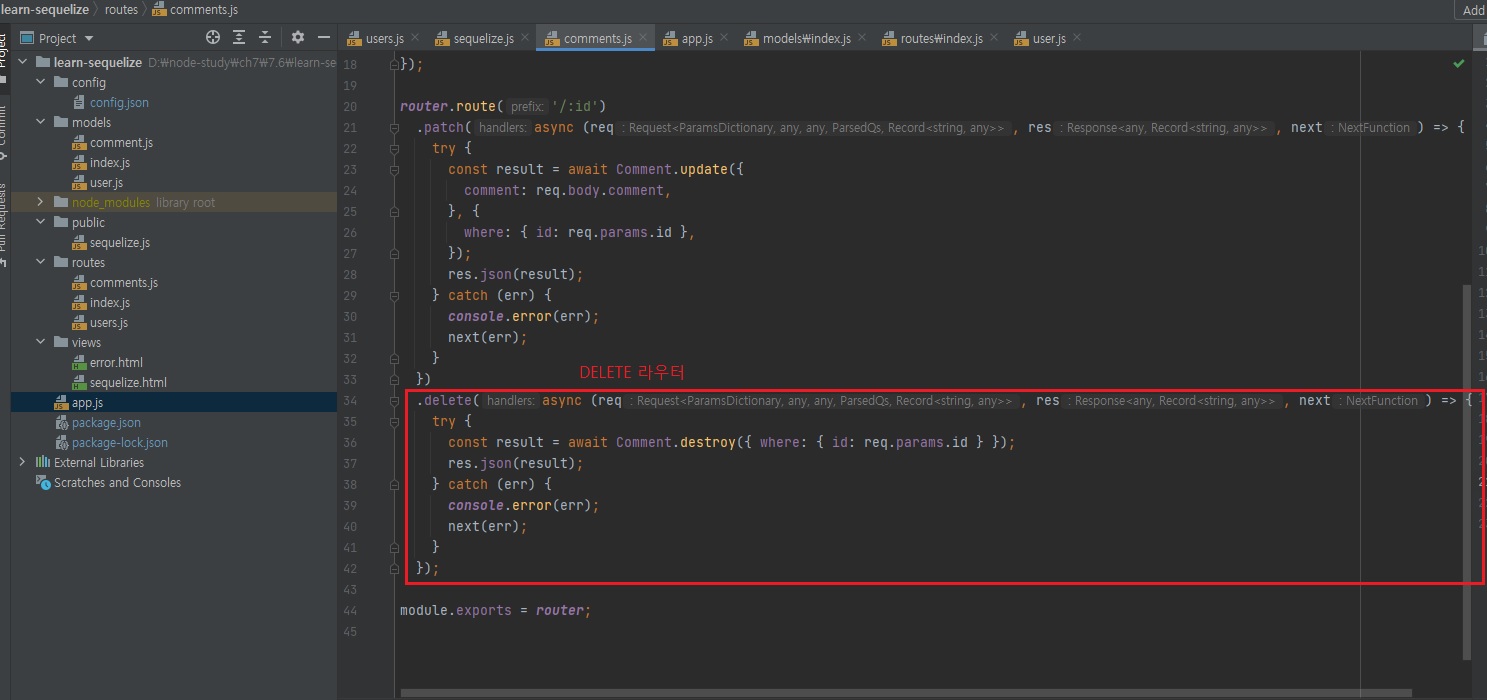
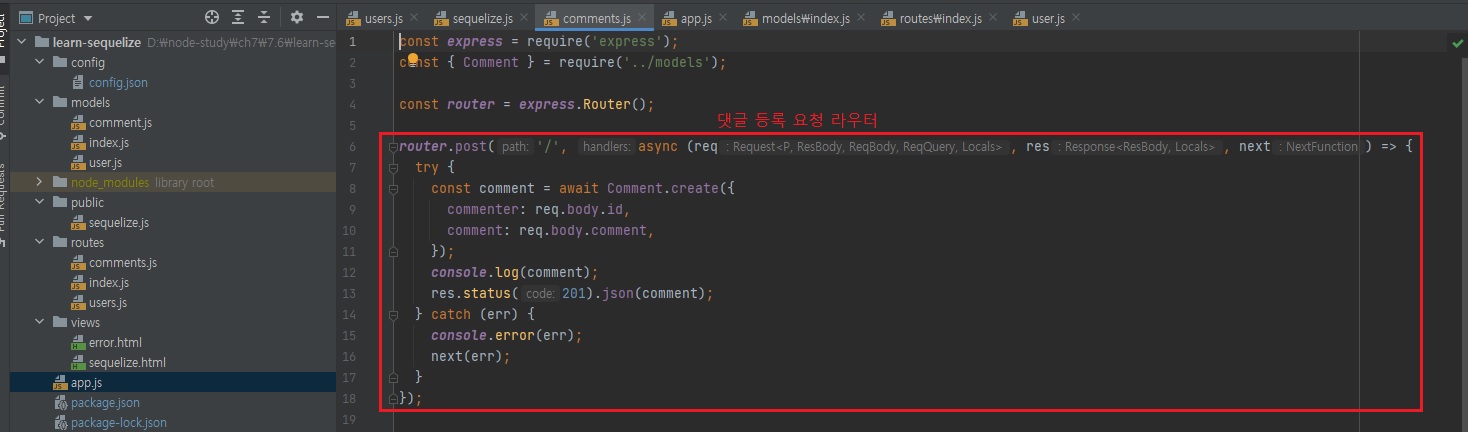
위 코드를 아래와 같은 방법으로도 쓸 수 있다고 했습니다.
const user = await User.findOne({ where: { id: req.body.id }})
// 빈 댓글을 작성하고
const comment = await Comment.create({
comment: req.body.comment,
})
// 해당 댓글과 사용자를 연결
const userComment = await user.addComment(comment);
위와 같은 경우는 아까도 말했지만 게임 아이템인 경우.
먼저 소유권 없이 생성이 되고 나중에 누군가가 그 아이템 주우면 그 사람 소유가 되는 경우에는 addItem 이런걸 나중에 해줘야되는 경우도 생길 수 있다는거.
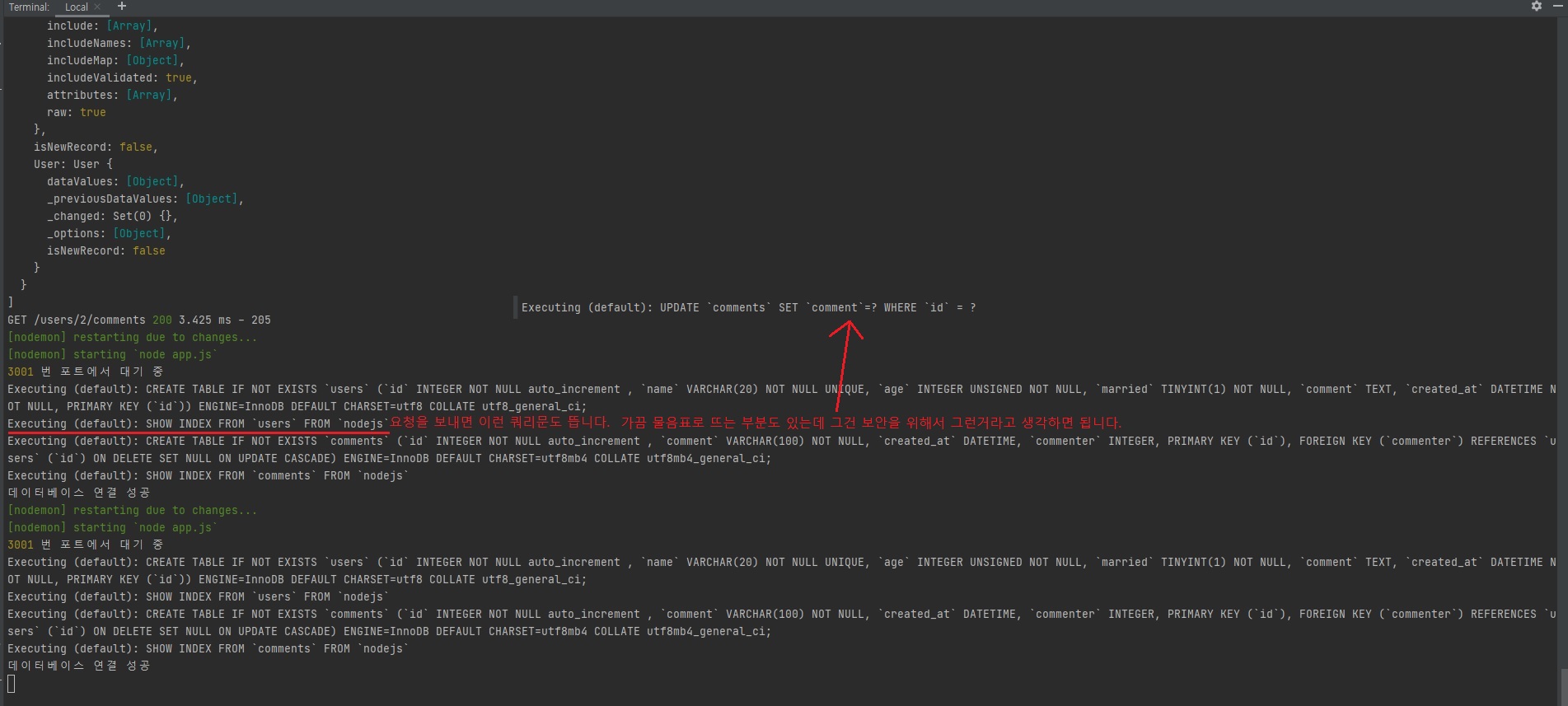
해커들이 많이 하는 수법 중 하나가 직접 해킹을 하진 못하니까 이런 콘솔에 기록된 로그들을 보고 해킹하는 경우가 많거든요?
예를들어 이 로그에 사용자 등록을 하는데 아이디와 비밀번호가 로그에 그대로 노출된다면 바로 털리겠죠?
그래서 로그 기록해주는 애들은 보안을 위해서 사용자 입력값을 ? 물음표로 대체해주는 경우가 많습니다.
개발자들이 자주하는 실수가 로그로 해킹당하는거.
실컷 암호화 잘해놔도 로그에다 그 사용자 아이디와 비번을 노출시키면, 해커가 이 로그를 빼돌리는 순간 모든 사용자의 아이디와 비밀번호가 다 기록되어있을테고 그러면 안되니까 ? 물음표 처리까지 시퀄라이즈가 해주고 있습니다.