
3 노드 기능
source: categories/study/nodejs/nodejs3.md
3강에선 노드에서 제공하는 것들에 대해 알아볼 건데요, 우선 3강을 진행하기 전에 2강을 잘 복습하고 오셔야합니다.
2강에서 자바스크립트의 실행 원리, 엔진 같은게 어떤식으로 돌아가는지 그럼으로인해 코드가 어떤 순서로 동작하는지, + 문법같은 걸 알려드렸습니다.
그래서 2강을 충분히 복습을 하여야 앞으로 노드 공부를 원활하게 하실 수 있습니다.
3.1 REPL 사용하기
-
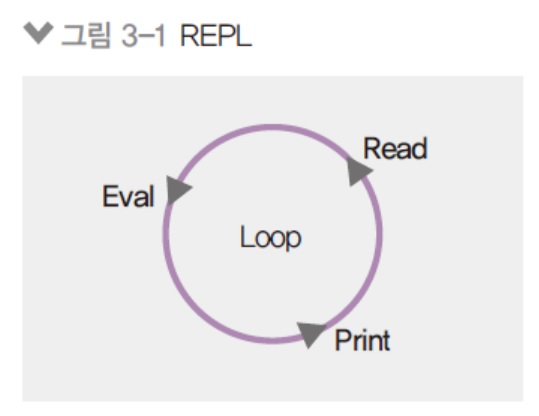
자바스크립트는 스크립트 언어라서 즉석에서 코드를 실행할 수 있음
- REPL이라는 콘솔 제공
- R(Read), E(Evaluate), P(Print), L(Loop)
읽고, 평가하고, 출력하고, 반복한다.
자바스크립트 파일을 실행을 하면 우선 파일을 읽고, 실행을 하고, 결과를 출력하고 반복합니다. -
윈도에서는 명령 프롬프트, 맥이나 리눅스에서는 터미널에 node를 입력
node
3.1.1 REPL
- 프롬프트에
node입력 - 프롬프트가 > 모양으로 바뀌면, 자바스크립트 코드 입력
-
입력한 값의 결과값이 바로 출력됨
- 간단한 코드를 테스트하는 용도로 적합
-
긴 코드를 입력하기에는 부적합
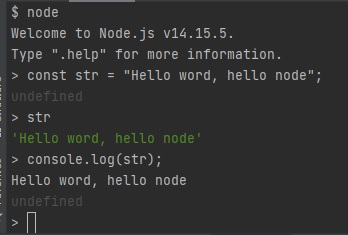
변수선언에 대한 결과는
undefined입니다.
console.log도 착각하시면 안되는게console.log의 결과물은undefined입니다.
console.log()의 소괄호 안에 있는 내용을 출력하지만,console.log자체의 return 값은undefined입니다.
str 변수를 콘솔에다 찍는 것은 부가적인 일이고console.log자체는undefined를 return합니다.
3.1.2 JS 파일 실행하기
-
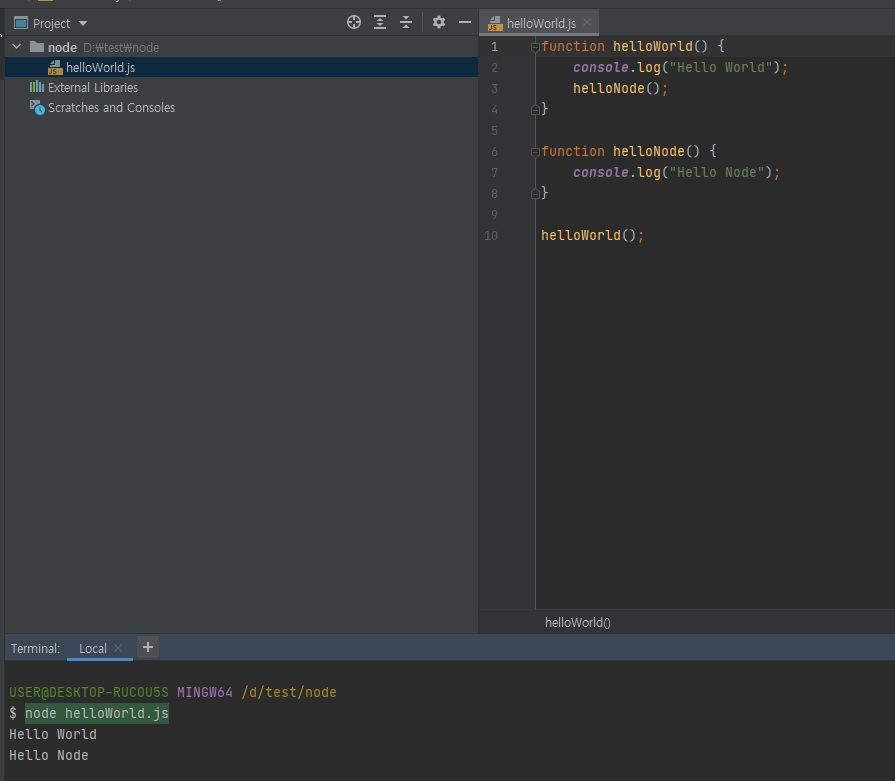
자바스크립트 파일을 만들어 통째로 코드를 실행하는 방법
- 아무 폴더(디렉토리)에서 helloWorld.js를 만들어보자
- node [자바스크립트 파일 경로]로 실행
-
실행 결과값이 출력됨
// helloWorld.js function helloWorld() { console.log("Hello World"); helloNode(); } function helloNode() { console.log("Hello Node"); } helloWorld(); // Hello World // Hello Node
3.2 모듈 만들기
3.2.1 모듈
-
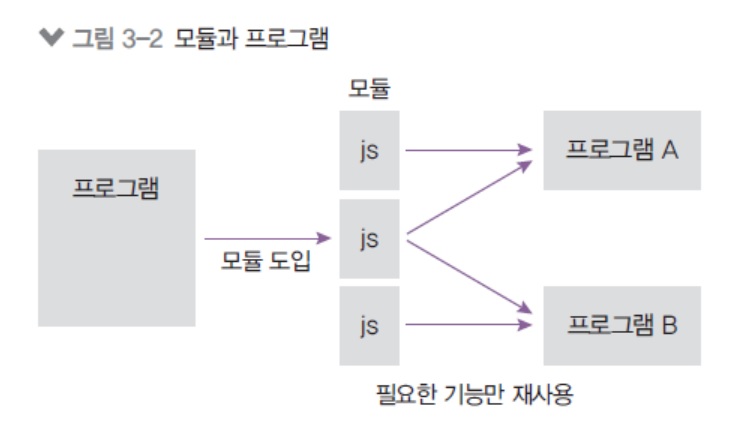
노드는 자바스크립트 코드를 모듈로 만들 수 있음
- 모듈: 특정한 기능을 하는 함수나 변수들의 집합
- 모듈로 만들면 여러 프로그램에서 재사용 가능
브라우저에도 ES2015+ 문법으로 모듈 문법이 들어왔습니다.
하지만 브라우저에선 대부분 안써보셨을 이유가 인터넷 익스플로러에선 지원이 안됩니다.
만약 모듈을 쓰셨다면 아마 webpack, gulp, grunt를 통해 사용해보셨을 겁니다.
3.2.2 모듈 만들어보기
-
같은 폴더 내에 var.js, func.js, index.js 만들기
- 파일 끝에 module.exports로 모듈로 만든 값을 지정
- 다른 파일에서 require(파일 경로)로 그 모듈의 내용 가져올 수 있음
아래와 같이 객체{}를
module.exports에 대입해줍니다.
module.exports에 객체{}만 넣으라는 법은 없습니다. 변수를 넣을 수도 있습니다.(하지만 이렇게하면 하나만 넣을 수 있음)
module.exports에는 객체{}, 배열, 변수 등을 넣을 수 있습니다.
module.exports엔 보통 객체{}로 여러개를 넘겨주거나 하나만을 넘겨줍니다.
module.exports는 파일에서 단 한번만 사용할 수 있습니다.(주의!)
require라는 함수는 노드에서 기본적으로 제공해주는 함수입니다.모듈은 코드의 중복을 줄일 수 있도록 해줍니다.
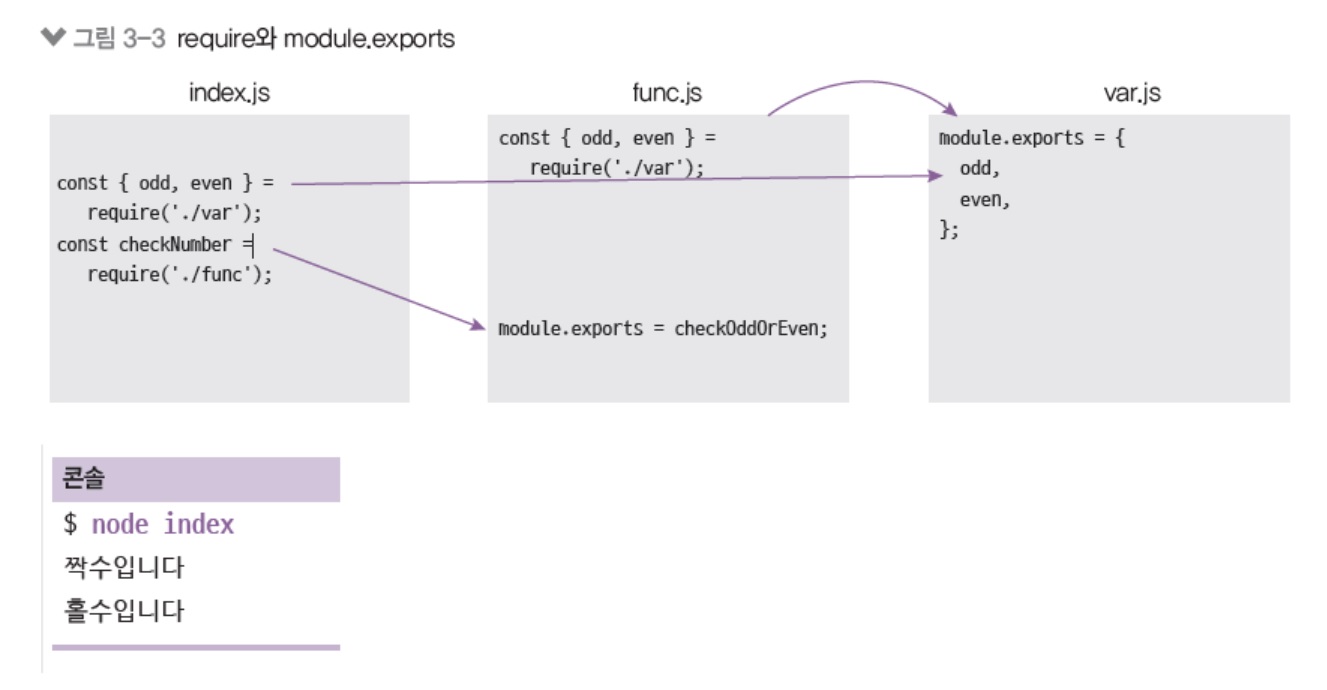
// var.js const odd = "홀수입니다"; const even = "짝수입니다"; module.exports = { odd, // 원래는 odd: odd인데, 최신 문법에서 키와 값이 같으면 하나로 작성 가능 even, // 이것도 원래는 even: even인데, 최신 문법에서 키와 값이 같으면 하나로 작성 가능 }// func.js const {odd, even} = require("./var"); function checkOddOrEven(num) { if (num % 2) { // 홀수면 return odd; } return even; } module.exports = checkOddOrEven;// index.js const {odd, even} = require("./var"); const checkNumber = require("./func"); function checkStringOddOrEven(str) { if (str.length % 2) { // 홀수면 return odd; } return even; } console.log(checkNumber(10)); console.log(checkStringOddOrEven("hello"));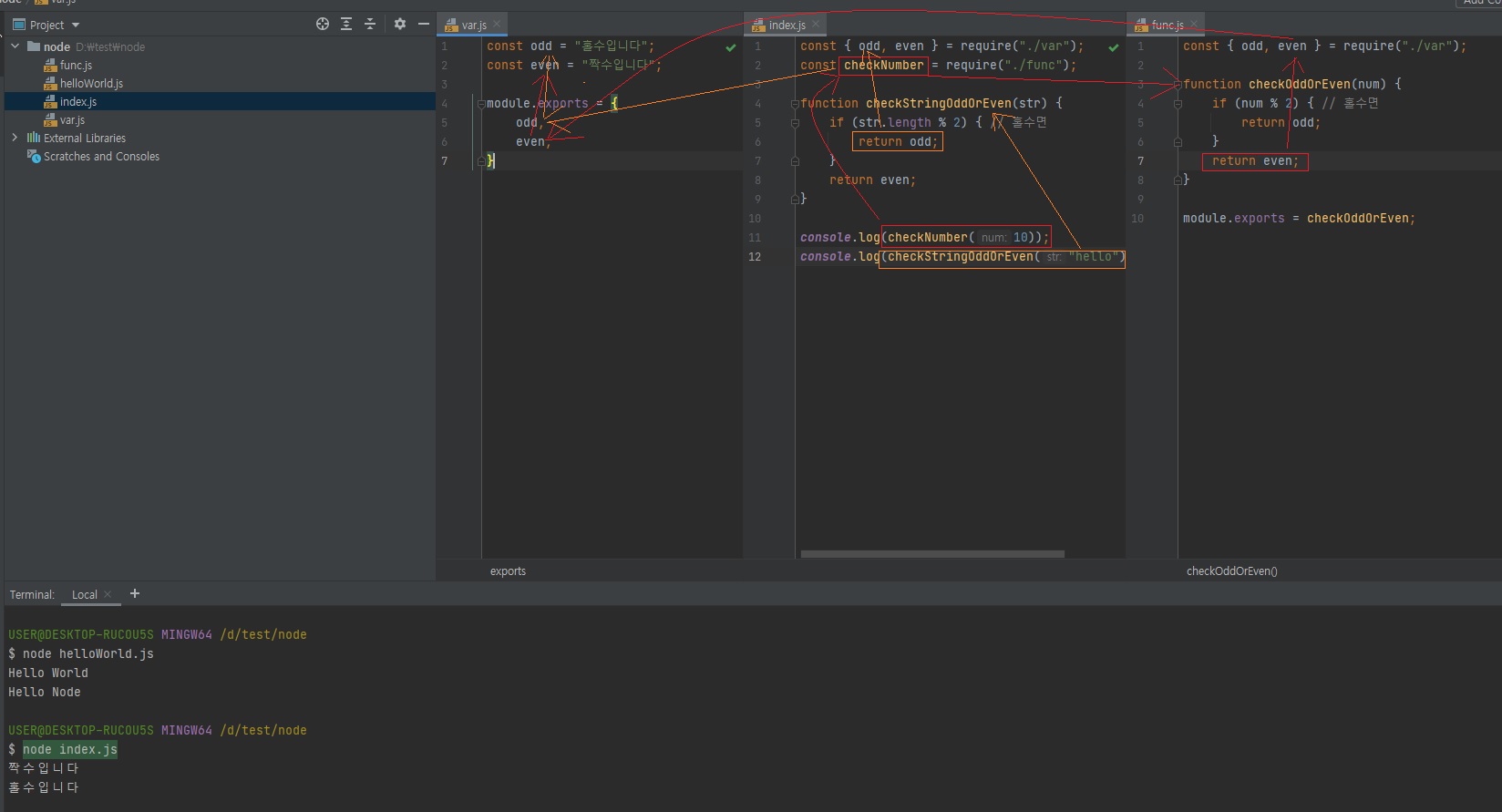
3.2.3 파일 간의 모듈 관계
-
node index로 실행
-
const { odd, even } 부분은 module.exports를 구조분해 할당한 것임(2장 참고)
-
3.2.4 ES2015 모듈
-
자바스크립트 자체 모듈 시스템 문법이 생김
- 아직 노드에서의 지원은 완벽하지 않음.
mjs확장자를 사용해야함.(무조건은 아니고mjs를 활용해야 속도가 빠르다는..) -
크게는
require대신import,module.exports대신export default를 쓰는 것으로 바뀜// func.mjs import {odd, even} from "./var"; function checkOddOrEven(num) { if (num % 2) { // 홀수면 return odd; } return even; } export default checkOddOrEven;브라우저는 위 코드처럼
import,export를 많이 씁니다.
아까 위의 코드들에서 보여드렸던require,module.exports는 노드의 모듈 시스템이고, 자바스크립트의 모듈 시스템이 따로 있습니다.
그런데 노드는 왜 자바스크립트의 모듈 시스템을 안 쓰느냐.
노드에서도 쓸 수는 있거든요?
그런데 자바스크립트의 모듈 시스템이 나오기 전에 노드에서 먼저 모듈 시스템을 도입했는데 하필 안타깝게도 노드의 모듈 시스템과 자바스크립트의 모듈 시스템이 일치를 안했던 겁니다.그런데 이게 뭔가 한번 만들면, 그 문법을 바꾸기란 힘들거든요?
왜냐면 기존에module.exports랑require쓰고 있던 사람들이 많았을거잖아요?
그런데 거기서 갑자기 우리는 앞으로import,export최신 모듈 문법만을 쓰겠다! 이러면 기존 코드들이 다 고장나버리겠죠.
그래서 못 바꾸고 노드는 계속module.exports와require로 가고 있는겁니다.
다만import,export최신 문법을 사용할 수 있게 지원도 합니다.module.exports를export default로 바꿔주시면되고const {odd, even} = require('./var')은import {odd, even} from './var'로 바꿔주시면 됩니다.
그런데 한가지 알아두셔야되는 것은require와import가 1대1 대응이 아닙니다. 동작이 약간 다릅니다.
그리고module.exports랑export default도 서로 동작이 다릅니다.그래서 대부분의 경우는 위 방법처럼 바꾸면 제대로 동작하긴 하는데, 제대로 동작 안하는 경우도 있으니까 무턱대고 이거를 1대1 대응되는줄알고 바꾸시면 안됩니다.
그런데 아마 노드 버전이 올라가면import/export문법이 그대로 들어오지 않을까 생각은 하는데 아직까지는 조금 난관이 있습니다.리액트, 앵귤러, 뷰를 사용하셨다면
import/export default가 익숙하실텐데require/module.exports랑 완전히 같은게 아니라는거. 그렇게 이해하시면됩니다.
- 아직 노드에서의 지원은 완벽하지 않음.
– 노드의 내장 객체 –
3.3 global과 콘솔, 타이머
노드의 내장 객체, 처음에 노드가 도입되면서 자바스크립트의 어떤 변화가 생겼는지 처음에 말씀드렸잖아요?
자바스크립트로 서버도 만들고 데스크탑 앱도 만들고 모바일 앱도 만들고 머신러닝도 돌릴 수 있고 IoT도 할 수 있습니다.
그렇게 할 수 있었던 이유가 노드가 자바스크립트를 실행해줬던 것도 있지만 노드가 다양한 기능들을 제공하기 때문입니다.
원래는 자바스크립트에 없었는데 노드가 제공하는 기능들이 있습니다.
3.3.1 노드 내장 객체 알아보기
3.3.1.1 global
-
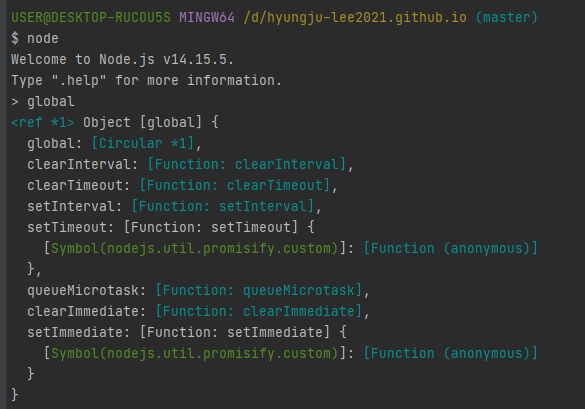
노드의 전역 객체
- 브라우저의 window 같은 역할
- 모든 파일에서 접근 가능
-
window 처럼 생략도 가능(console, require도 global의 속성)
아까 보여드렸던require,module.exports이런거 저희가 선언을 안했는데도 사용할 수 있잖아요?
원래는require is not a function,module is not defined이런 오류가 떠야하는데 그냥 사용해도되죠?
되는 이유는 노드가 제공을 하기 때문입니다.
그래서 노드가 자바스크립트에 어떤 힘을 부여했는지 내장 객체를 보시면서 공부하시면 되는데 한가지 당부의 말씀은 외우지 마세요.
외우지 마시고 당장은 이런게 있구나 라고 생각하시고 나중에 필요하면 그때 다시 찾아보세요. (너무 많아서 외울 필요가 없어요.)
노드에선
global, 브라우저에선window- 헷갈리므로 이게globalThis로 통일되었습니다.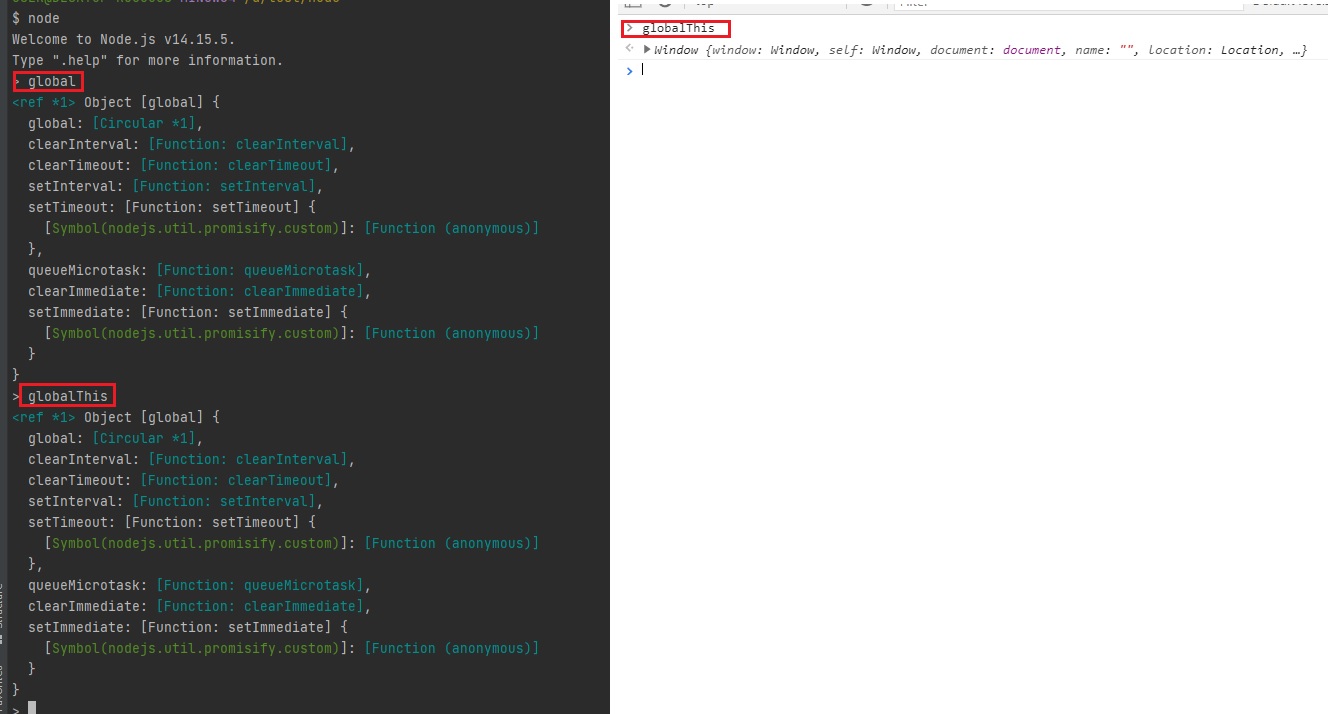
위의 스샷처럼 브라우저에서도
globalThis가 됩니다.
그런데 문제가 이게 또 인터넷 익스플로러에선 안된다는 것. 최신 브라우저에서만 됩니다.노드의
global이나 브라우저의window나 하는 역할은 같다고 보시면됩니다.
다만 브라우저의window객체엔 브라우저를 조작할 수 있는 많은 것들이 들어있었지만,document도 들어있고 그랬죠?
노드에서는window나document는 동작하지 않습니다.
왜냐하면 브라우저가 아니기 때문입니다.
노드에서는 노드만의 것들이 따로 있습니다.global이나window객체는 생략 가능합니다.global.require()global.console.log()global.setTimeout()global.module.exports
…
3.3.1.2 global 속성 공유
-
global 속성에 값을 대입하면 다른 파일에서도 사용 가능
// globalA.js module.exports = () => global.message;// globalB.js const A = require("./globalA"); global.message = "안녕하세요"; console.log(A());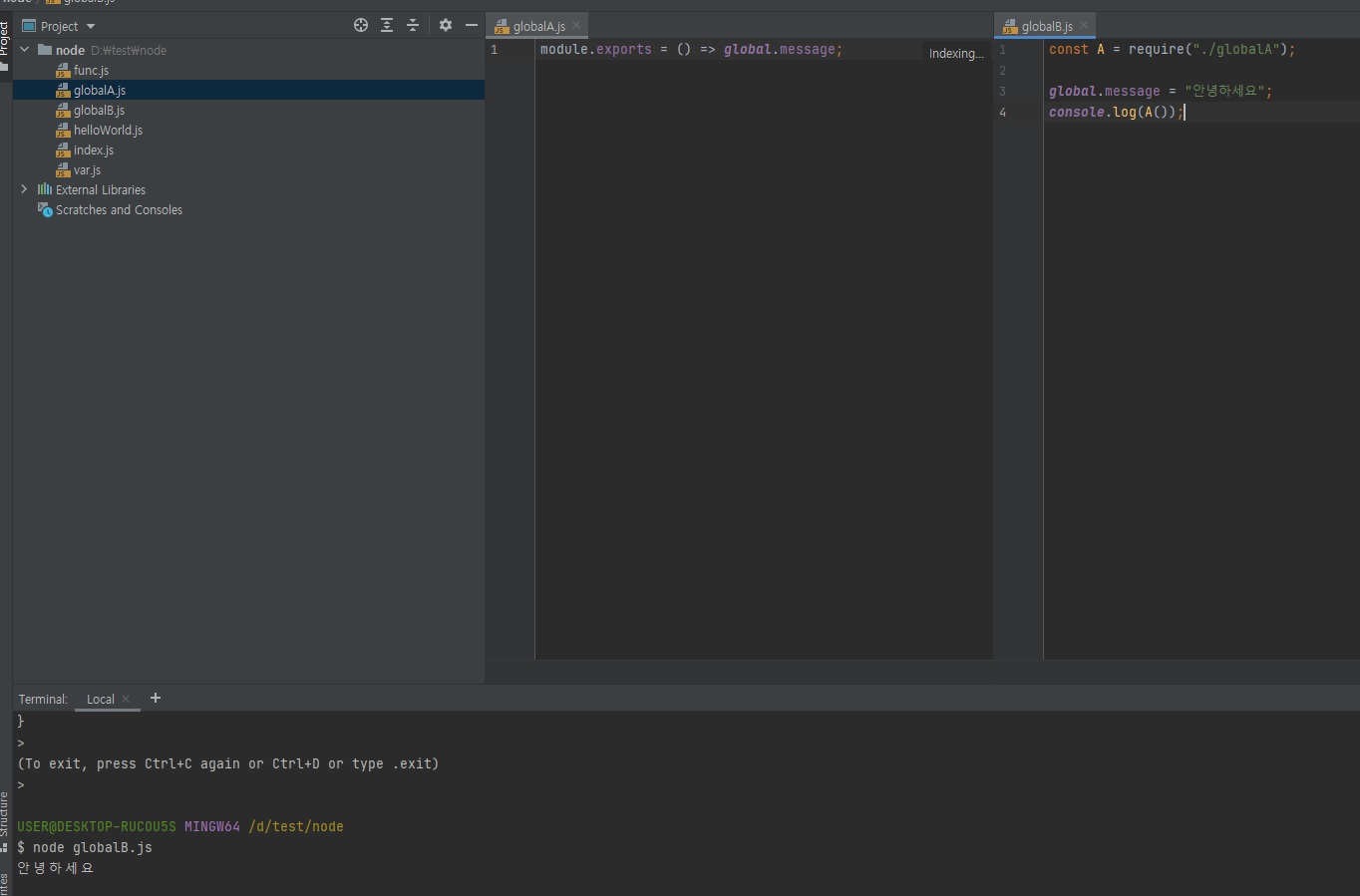
global을 활용해 전역으로 공유하는 것은 좋은 것이 아닙니다.
global객체에 저장해서 여러 파일에서 공유를 하면 아까 보여드렸던 모듈 시스템 이런 거 안써도돼서 편하다고 생각하실 수도 있는데
파일이 수백개가 되면 어디서global에 저장했는지 관리가 안되거든요?
그래서 웬만하면global에 값을 대입하진 마시고 모듈로 만드세요.
global을 활용하는 것은 안 좋은 습관입니다.
절대 권장하지 않습니다.
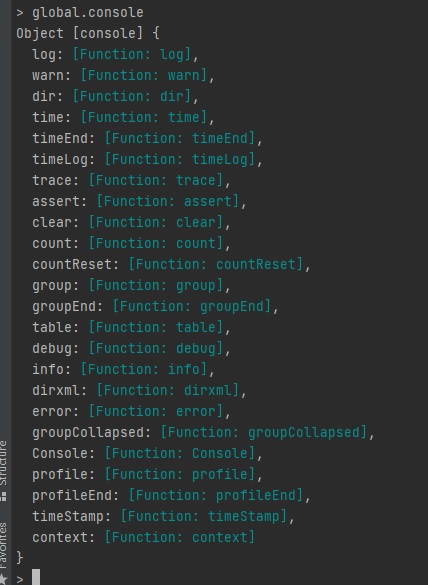
3.3.1.3 console 객체
-
브라우저의
console객체와 매우 유사- console.time, console.timeEnd: 시간 로깅
- console.error: 에러 로깅
- console.log: 평범한 로그
- console.dir: 객체 로깅
-
console.trace: 호출스택 로깅
const string = "abc"; const number = 1; const boolean = true; const obj = { outside: { inside: { key: "value" } } } console.time("전체 시간"); console.log("평범한 로그입니다 쉼표로 구분해 여러 값을 찍을 수 있습니다"); console.log(string, number, boolean); console.error("에러 메시지는 console.error에 담아주세요"); console.table([{name: "제로", birth: 1994}, {name: "hero", birth: 1988}]); console.dir(obj, {colors: false, depth: 2}); console.dir(obj, {colors: true, depth: 1}); console.time("시간 측정"); for (let i = 0; i < 100000; i++) { } console.timeEnd("시간 측정"); function b() { console.trace("에러 위치 추적"); } function a() { b(); } a(); console.timeEnd("전체 시간");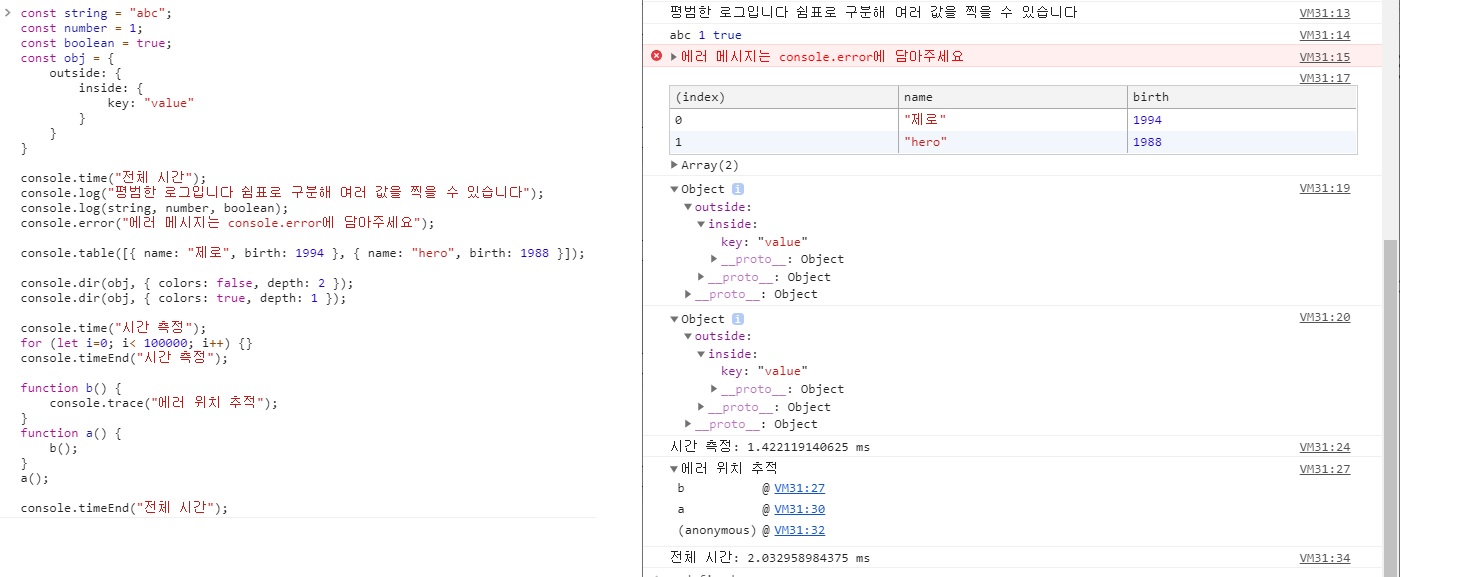
-
console.time("하이"),console.timeEnd("하이")이렇게 적으면 이 두개 사이에 있는 코드들의 실행 시간을 측정할 수 있습니다.
그래서 여러분의 코드가 얼마나 효율적인지 측정하고 싶을 때console.time("하이"),console.timeEnd("하이")이런식으로 적어주면 됩니다. -
console.trace()는 호출하면 함수 안에서 호출 스택을 보여줍니다.
-
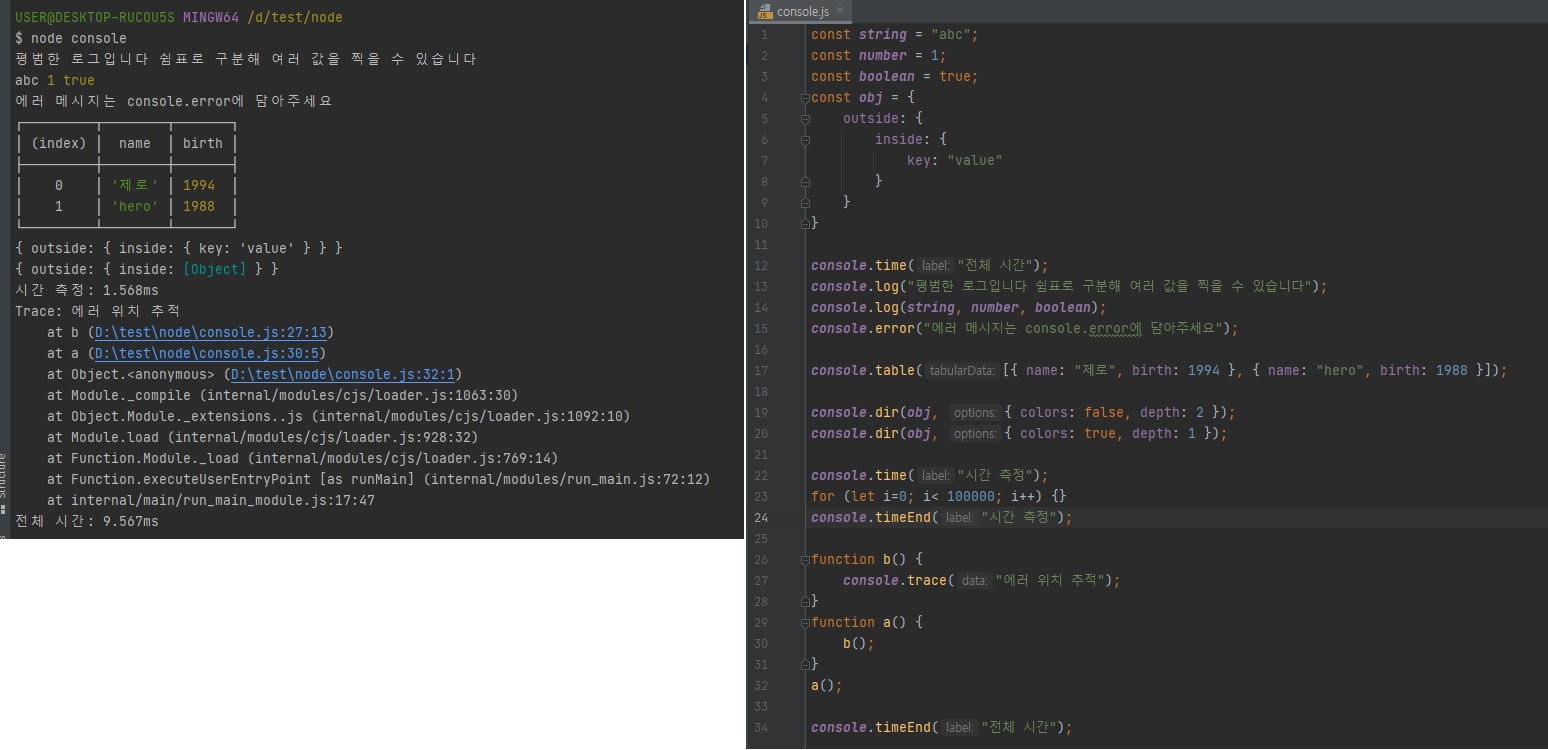
3.3.1.4 console 예제 실행하기
-
node console로 실행
3.3.1.5 타이머 메소드
-
set 메소드에 clear 메소드가 대응됨
-
set 메소드의 리턴 값(아이디)을 clear 메소드에 넣어 취소
아래 코드처럼.const val = setTimeout(() => {}, 2000); clearTimeout(val); - setTimeout(콜백함수, 밀리초): 주어진 밀리초(1000분의 1초) 이후에 콜백 함수를 실행합니다.
- setInterval(콜백함수, 밀리초): 주어진 밀리초마다 콜백함수를 반복 실행합니다.
- setImmediate(콜백함수): 콜백함수를 즉시 실행합니다.
- clearTimeout(아이디): setTimeout을 취소합니다.
- clearInterval(아이디): setInterval을 취소합니다.
- clearImmediate(아이디): setImmediate를 취소합니다.
노드에서 좀 독특한게
setImmediate함수입니다.
setImmediate함수는 콜백함수를 즉시실행 시킵니다.
즉, 어떻게보면setTimeout(콜백함수, 0)이랑 똑같은겁니다.
그럼setTimeout(콜백함수, 0)이랑setImmediate이 무슨 차이가있냐.실행 순서에서 조금 차이가 있습니다.
그런데 실행순서가 좀 헷갈리니깐
setTimeout(콜백함수, 0)하실바엔setImmediate를 사용하십시오.
setTimeout(콜백함수, 0)은 없다고 생각하시고setImmediate를 사용하시는 것이 편합니다.그럼 여기서 또 의문이 생기는데, 어, 바로 실행되는 것을 왜 굳이
setTimeout에 넣죠? 이렇게 생각하실 수도 있습니다.
타이머 함수는 타이머 함수 안에 있는 콜백 함수가 기본적으로 백그라운드에 넘어가죠?
백그라운데 가면 동시에 실행될 수 있다고 했습니다. 어디랑? 호출스택에 쌓여있는 코드들이랑.
물론 모든 코드가 동시에는 안되지만 특정한 코드들을 동시에 실행할 수 있거든요.(2장에서 말씀드린 특정 코드들 - 규칙)
즉,setImmediate로 어떤 코드들은 동시에 실행되게 백그라운드로 보낼 수가 있습니다.setTimeout,setInterval,setImmediate이 세개의 함수는 콜백함수를 백그라운드로 보내는 대표적인 비동기 코드라고 보시면 됩니다.
이거 말고 Promise의 then도 봤었죠? -
3.3.1.6 타이머 예제
-
다음 예제의 콘솔 출력을 맞춰보자
-
setTimeout(콜백, 0)보다 setImmediate 권장
// timer.js const timeout = setTimeout(() => { console.log("1.5초 후 실행"); }, 1500) const interval = setInterval(() => { console.log("1초마다 실행"); }, 1000) const timeout2 = setTimeout(() => { console.log("실행되지 않습니다"); }, 3000) setTimeout(() => { clearTimeout(timeout2); clearInterval(interval); }, 2500) const immediate = setImmediate(() => { console.log("즉시 실행"); }) const immediate2 = setImmediate(() => { console.log("실행되지 않습니다"); }) clearImmediate(immediate2); // 즉시 실행 // 1초마다 실행 // 1.5초 후 실행 // 1초마다 실행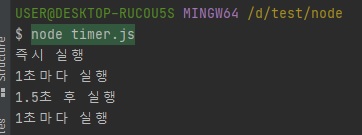
위와 같이
setImmediate도 취소할 수 있습니다.
그 이유는setImmediate의 콜백함수가 바로 실행되는 것이 아니라 백그라운드로 갔다가 테스크 큐로 갔다가 이벤트 루프에 의해 호출 스택으로 가는 것이기 때문에
백그라운드 -> 테스크 큐 -> 이벤트루프 -> 호출스택 이 과정에서 취소하면 바로 실행되는 것도 취소할 수 있습니다.
-
3.3.1.7 타이머 예제 결과

3.4 exports와 this
3.4.1 __filename, __dirname
노드는 브라우저와 다르게 여러분들의 컴퓨터에 접근할 수가 있습니다.
여러분들의 파일을 지우거나 생성할 수 가 있거든요?
그래서 노드로 자바스크립트 실행을 하실 땐 좀 조심하셔야됩니다.
악의적인 의도를 가진 해커가 작성한 코드를 실행하면 여러분들의 소중한 파일들이 증발한다던가 개인정보를 가져갈 수도 있기 때문에 그 점을 조심하셔야됩니다.
이점이 노드를 만든 사람이 후회한 부분이기도한데, 노드가 파일시스템 접근에 보안적인 이슈가 있어서..
여튼 노드로 여러분들의 파일시스템, 하드디스크나 SSD에 접속할 수 있다는 거.
- __filename: 현재 파일 경로
- __dirname: 현재 폴더(디렉토리) 경로
위와 같이 REPL에선 안됩니다.
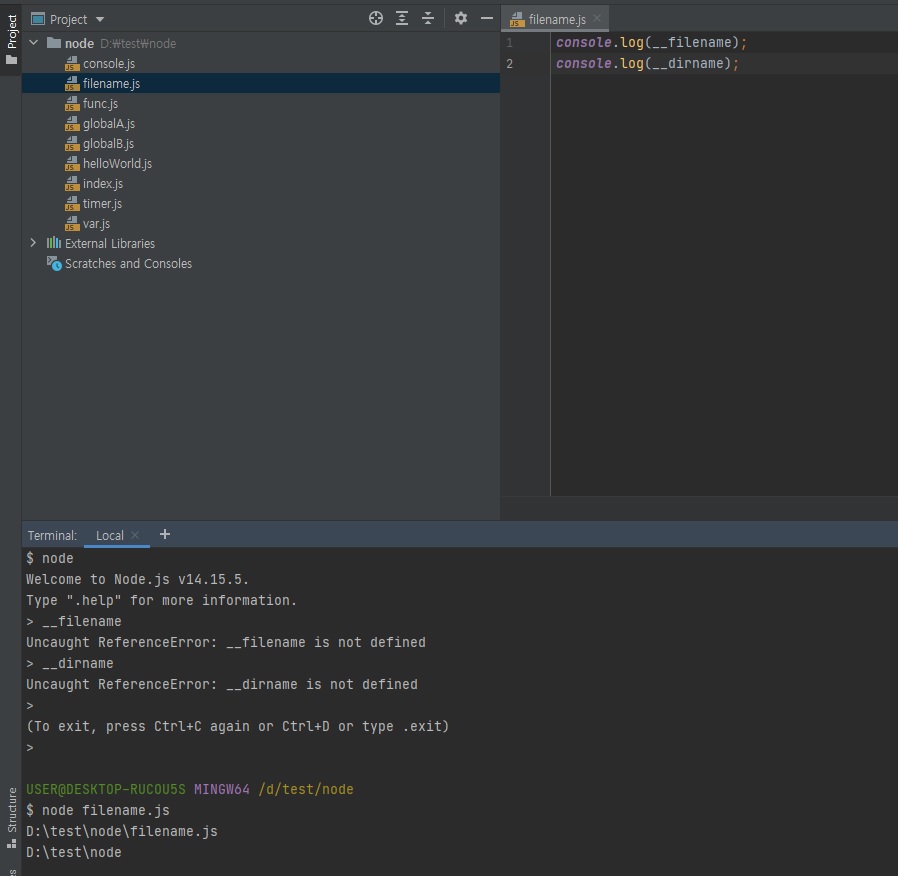
__filename, __dirname 생각외로 자주 쓰입니다.
나중에 path 모듈 배울텐데 이 모듈이랑 조합해서 많이 쓰입니다.
3.4.2 module, exports
-
module.exports외에도exports로 모듈을 만들 수 있음- 모듈 예제의 var.js를 다음과 같이 바꾼 후 실행
- 동일하게 동작함
- 동일한 이유는
module.exports와exports가 참조 관계이기 때문 -
exports에 객체의 속성이 아닌 다른 값을 대입하면 참조 관계가 깨짐// var.js exports.odd = "홀수입니다"; exports.even = "짝수입니다";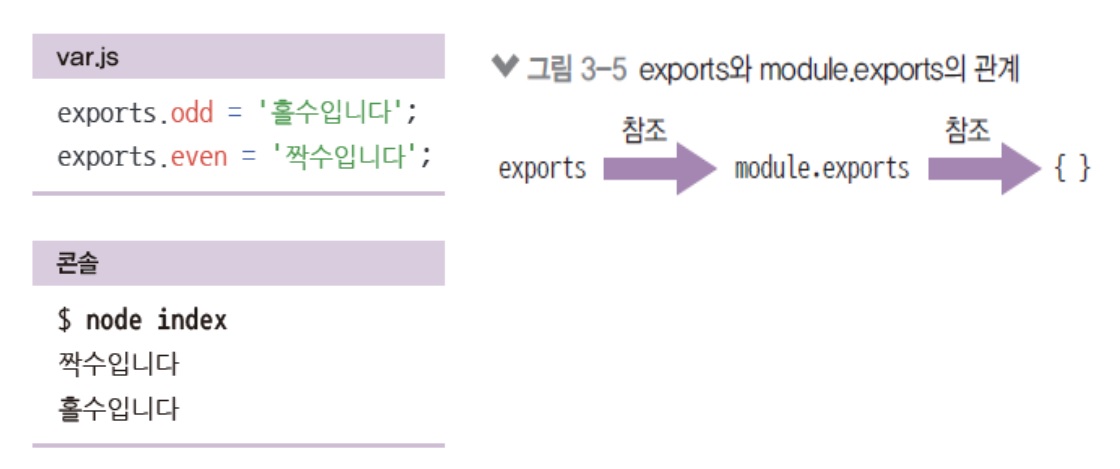
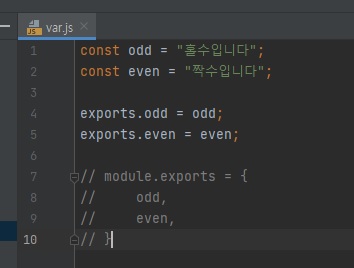
module도 생략이 가능하기 때문에 위와 같이 사용할 수 있습니다.그럼
module.exports랑exports가 무슨 차이냐?
아래와 같이 서로 같습니다.
그리고 객체{}와도 같은데module.exports === exports === {}
문제는 module.exports에 함수를 넣었을 경우입니다.
const { odd, even } = require("./var");
function checkOddOrEven(num) {
if (num % 2) { // 홀수면
return odd;
}
return even;
}
module.exports = checkOddOrEven;
위와 같이 함수를 넣은 경우
module.exports !== exports === {}
이렇게 되어버립니다. module.exports와 exports가 서로 같지 않게되는거죠.
<span style="color:red'>객체의 참조관계가 끊겨버리기 때문에 주의하셔야됩니다.</span>
이것이 복잡하다고 생각되시면, 제가 한가지 원칙을 말씀드릴텐데
-
두가지 이상을 내보낼 땐
exports를 많이 씁니다.
exports만 쓰시면 그 파일에선exports만 쓰셔야됩니다.
module.exports와 섞어쓰면 안됩니다.
아래와 같이module.exports를 하는 순간 위의exports를 덮어씌워버립니다.
즉,exports내용들이 다 날라가버리는 것이죠. (참조 관계가 끊겨서)const odd = "홀수입니다"; const even = "짝수입니다"; exports.odd = odd; exports.even = even; module.exports = { odd, even, } -
module.exports는 보통 한가지를 내보낼 때 많이 씁니다.const {odd, even} = require("./var"); function checkOddOrEven(num) { if (num % 2) { // 홀수면 return odd; } return even; } module.exports = checkOddOrEven; -
exports랑module.exports를 한 파일 내에서 같이 쓰면 안된다.
3.4.3 this
-
노드에서
this를 사용할 때 주의점이 있음- 최상위 스코프의
this는module.exports를 가리킴 - 그 외에는 브라우저의 자바스크립트와 동일
-
함수 선언문 내부의
this는global(전역) 객체를 가리킴// this.js console.log(this); // {} console.log(this === module.exports); // true console.log(this === exports); // true function whatIsThis() { console.log("function", this === exports, this === global); // function, false, true } whatIsThis();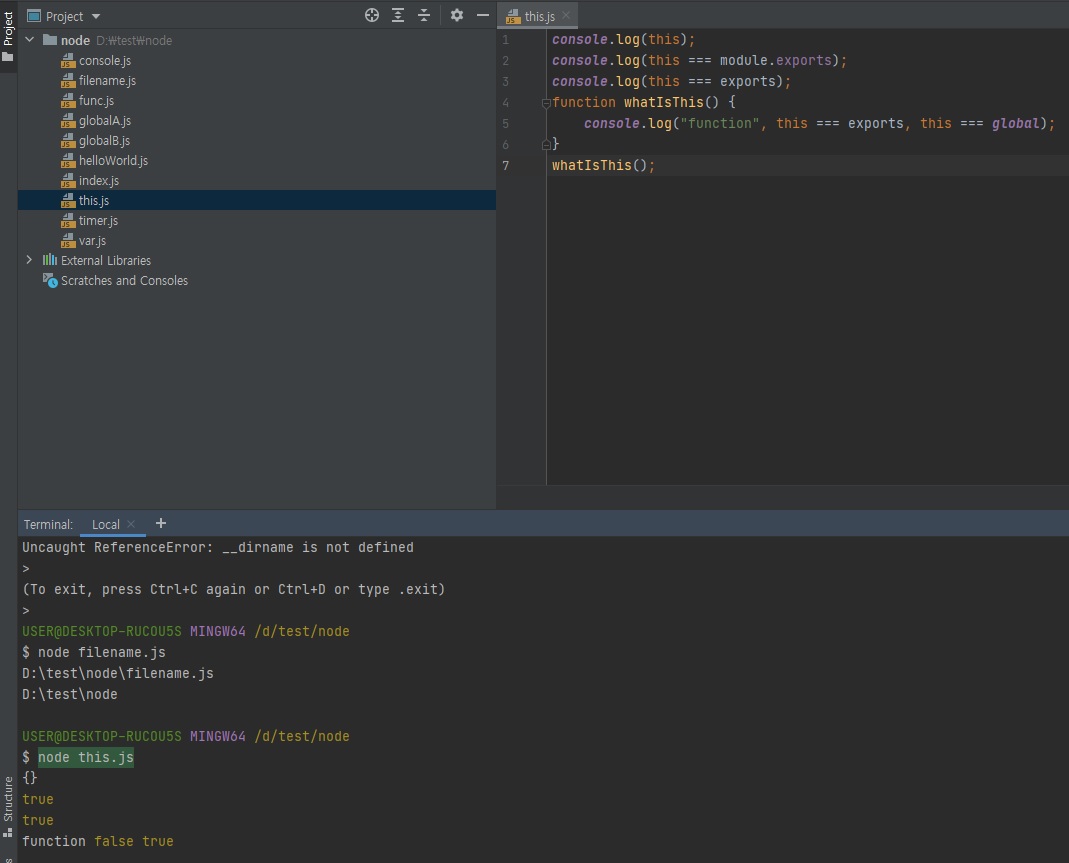
이것이 브라우저의 자바스크립트와 노드의 자바스크립트의 차이점입니다.
브라우저에서의console.log(this)는 글로벌 객체(window)를 가리킵니다.
때문에 노드에서도console.log(this)위치의this가 global이지 않을까? 라는 합리적인 추측을 할 수 있는데, 노드에선 다릅니다.
이 전역 스코프, anonymous 스코프라고도 하죠?
노드에서 이 anonymous의 this는빈 객체{}를 가리킵니다.
이 빈 객체가 나오는 이유는this === module.exports === exports = {}이기 때문이죠.위의 함수처럼 저 위치에 위치한 function 안의
this는 global을 가리킴 -
이 외에는 자바스크립트의
this동작과 똑같습니다.
function마다this가 새로 생기는 거 똑같고 화살표 함수를 쓰면 부모의this를 물려받는 것도 똑같고.
전역 스코프의this만module.exports라는 것.const odd = "홀수입니다"; const even = "짝수입니다"; this.odd = odd; this.even = even;그럼 이렇게도 쓸 수 있겠죠?
하지만 이렇게 쓰는 경우는 거의 없습니다.
이렇게 안 쓰는 이유는 헷갈리기 때문.
- 최상위 스코프의
3.5 모듈 심화, 순환 참조
3.5.1 require의 특성
-
몇 가지 알아둘 만한 속성이 있음
- require가 제일 위에 올 필요는 없음
require은 순서에 상관이 없습니다.
하지만 앞서 말씀드렸던import/export최신 문법,import가 가장 위에 있어야합니다.
그래서require는 가장 위에 없어도 되지만import는 가장 위에 있어야된다.
이런 것들이 최신 자바스크립트 모듈 문법과 노드 모듈 사이의 차이입니다. - require.cache에 한번 require한 모듈에 대한 캐시 정보가 들어있음
require한 모듈뿐만아니라 exports한 모듈들.. 순서대로 다 들어가있음.
상위에 있을 수록 부모 모듈로 인식하는 것 같음. 아래 콘솔창에 찍히는거보니까.
즉, 이것도 실행 콘텍스트가 설정되면서 서로 스코프가 형성되고, 그 스코프를 통해 체이닝하는 것 같음.
그런식으로 되게끔 구조가 되어있는 듯.
자바스크립트의 원래 특성과 같음. -
require.main은 노드 실행시 첫 모듈을 가리킴
// require.js console.log("require가 가장 위에 오지 않아도 됩니다."); module.exports = "저를 찾아보세요."; require("./var"); console.log("require.cache입니다."); console.log(require.cache); console.log("require.main입니다."); console.log(require.main); console.log(require.main === module); console.log(require.main.filename);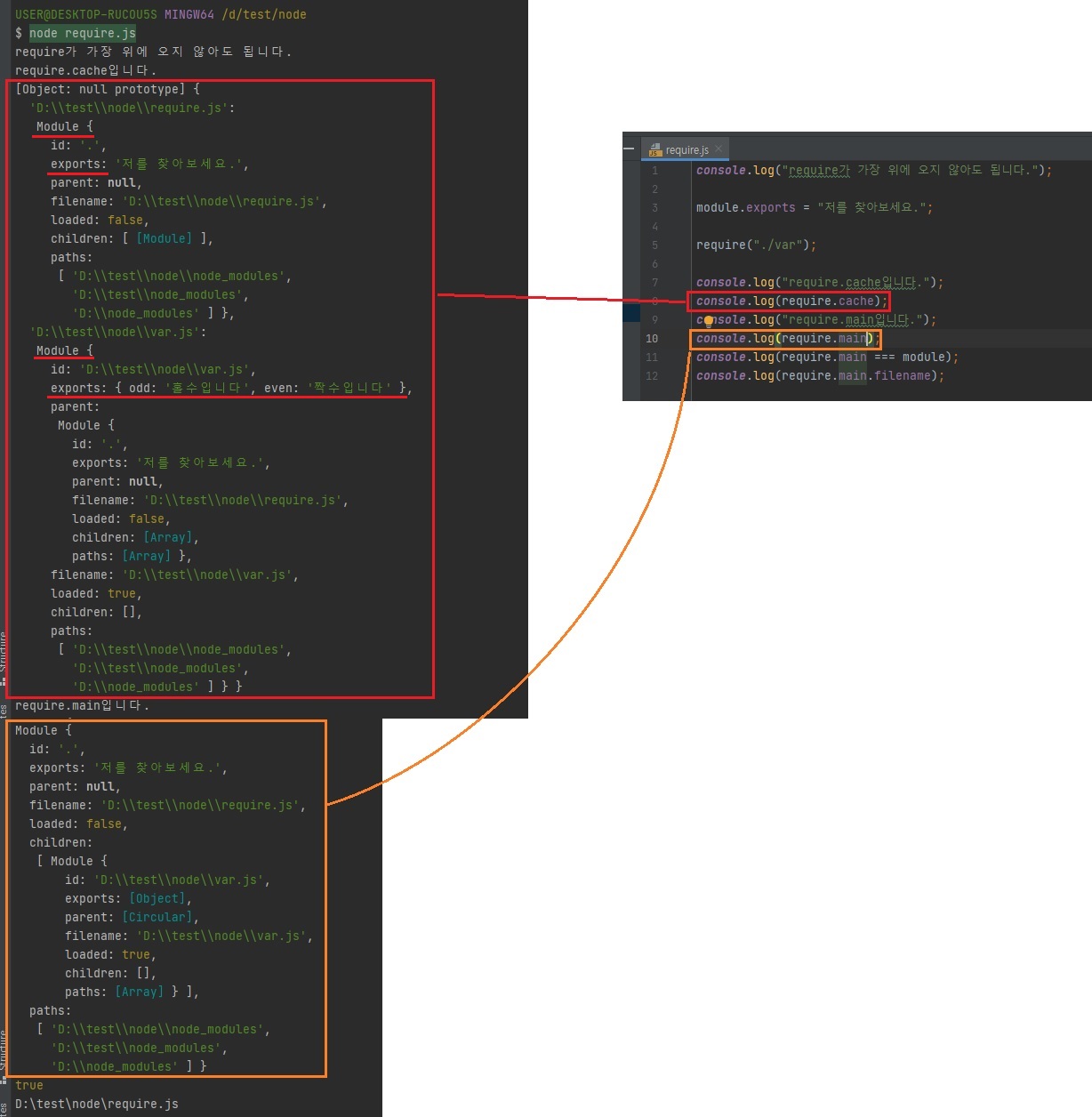
위에 보시면 변수에
require("./var")를 안 담죠?
안 담아도 되나요? 라고 의문을 가지실 수 있는데 안 담아도 됩니다.
단, 위와 같이 불러오면 효과가 뭐냐.
var.js가 실행은 됩니다.
실행은 되는데var.js에서exports또는module.exports로 내보낸 것들을 위 파일에서 안 쓸뿐입니다.즉, 다른 파일을 불러와 실행만 시키고 싶다, 그 파일 안에 변수들 같은거를 사용하진 않을거다. 라고 한다면 위와 같이
require로만 불러오고 변수에 담지 않아도 됩니다.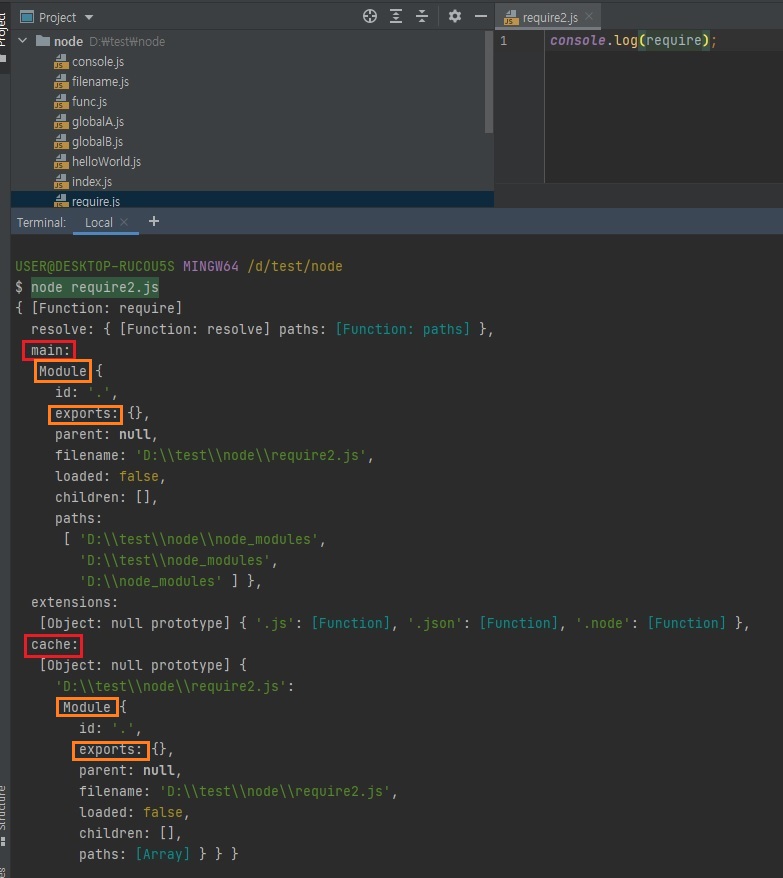
위에서 중요한게
main,cache정도입니다.
이 두개만 알아두시면 됩니다.
extension은 확장자이니깐 굳이 아실 필요는 없을 것 같고, main이 머냐면 위의require.js파일,require2.js파일 둘 다 모두 모듈이죠?자바스크립트를 노드로 실행하면 파일들은 거의 다 모듈이라고 보시면 됩니다.
왜냐면 자바스크립트js파일마다 기본적으로module.exports = {}코드가 존재하기 때문입니다.
아무것도exports안해도 빈객체{}가 exports되고 있는겁니다.require.main으로 현재 어떤 파일을 실행한건지 알아낼 수 있습니다.
require.cache라는 것이 있는데 이것은require한 코드를 효율을 위해 메모리 안에 저장해둔 것입니다.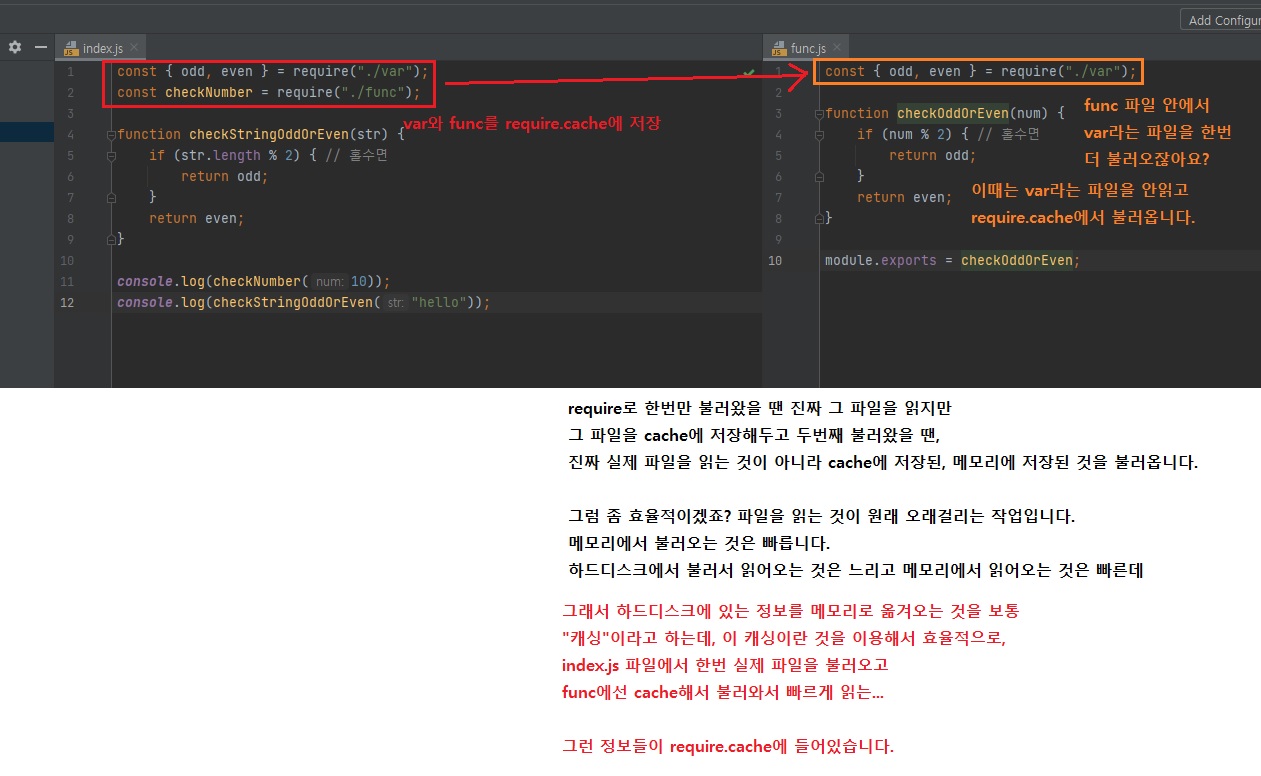
require.cache를 초기화하시면 다음에var.js를 불러오면require.cache에var가 없으니까 다시 파일을 불러서 읽어오겠죠?
그런식으로require.cache를 조작해서 초기화하는 방법도 있습니다.
그런데 그러면 좀 위험하겠죠?
아무래도 내장되어있는 객체를 조작하는 것은 좀 위험합니다.
어쨌든 그런게 가능하긴 합니다.require.cache를delete해서 초기화할 수 있는데 많이 쓰는 방법은 아닙니다.
여튼require.main과require.cache에 대해 알아두시면 좋습니다.Noterequire.main,require.cache활용 예시노드에서 파일을 실행한 후 파일 코드를 수정하면 노드를 껐다가 다시 켜야지 변경된 것이 적용이 됩니다.
그런데 이require.cache를 적절히 수정을 하면, 노드를 껐다가 켜지 않아도 실시간으로 코드를 업데이트하는 꼼수를 쓸 수가 있습니다.
그런데 그렇게하려면 노드의 동작을 완벽하게 알아야겠죠?
그런거를 나중에 혹시 하실 분들을 위해서require.cache를 소개를 해드릴 뿐이지 웬만하면 직접 다루실 일은 없을겁니다.
- require가 제일 위에 올 필요는 없음
그럼 이런식으로도 접근이 되겠죠?
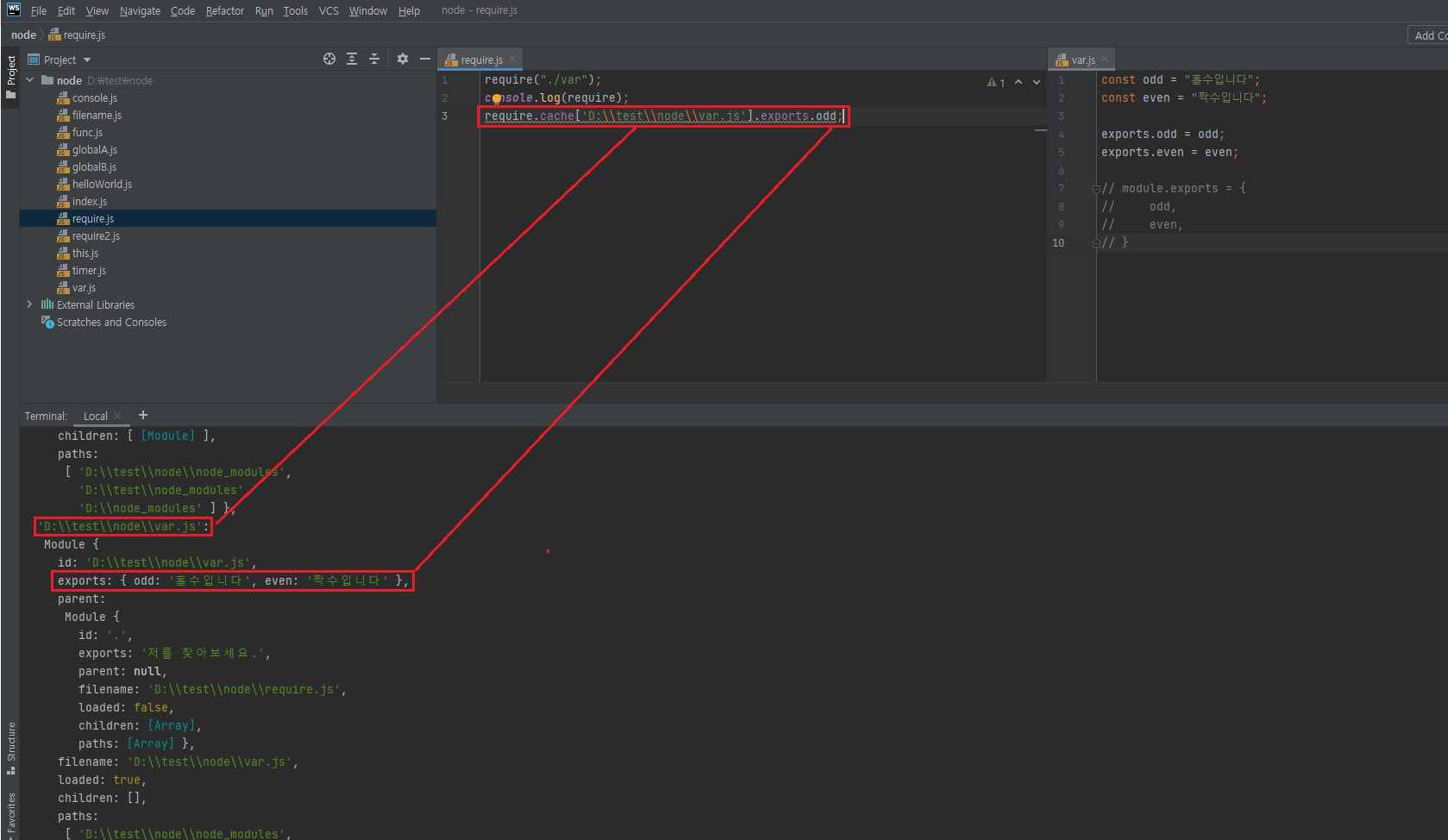
이런 식으로 require.cache에 접근해서 다른 파일의 exports를 꺼내오는 방법도 있습니다.
방법만 있을 뿐이지 실제로 쓰는 것은 못봤습니다.
왜냐하면 위험하기 때문에
여튼 이런 내부적인 것을 아시면 노드를 좀 더 효율적으로 접근하실 수 있는데, 이런 내부적인걸 직접 사용하는 경우는 그렇게 많지는 않다,라는 정도로 이해하시면 되겠습니다.
3.5.2 순환참조
-
두 개의 모듈이 서로를 require하는 상황을 조심해야 함
- dep1이 dep2를
require하고, dep2가 dep1을require함. - dep1의
module.exports가 함수가 아니라 빈 객체가됨(무한 반복 때문에 컴퓨터가 멈춰버리는 것을 막기위해 의도됨) -
순환참조하는 상황이 나오지 않도록 하는게 좋음
// dep1.js const dep2 = require("./dep2"); console.log("require dep2", dep2); module.exports = () => { console.log("dep2", dep2); }// dep2.js const dep1 = require("./dep1"); console.log("require dep1", dep1); module.exports = () => { console.log("dep1", dep1); }// dep-run.js const dep1 = require("./dep1"); const dep2 = require("./dep2"); dep1(); dep2();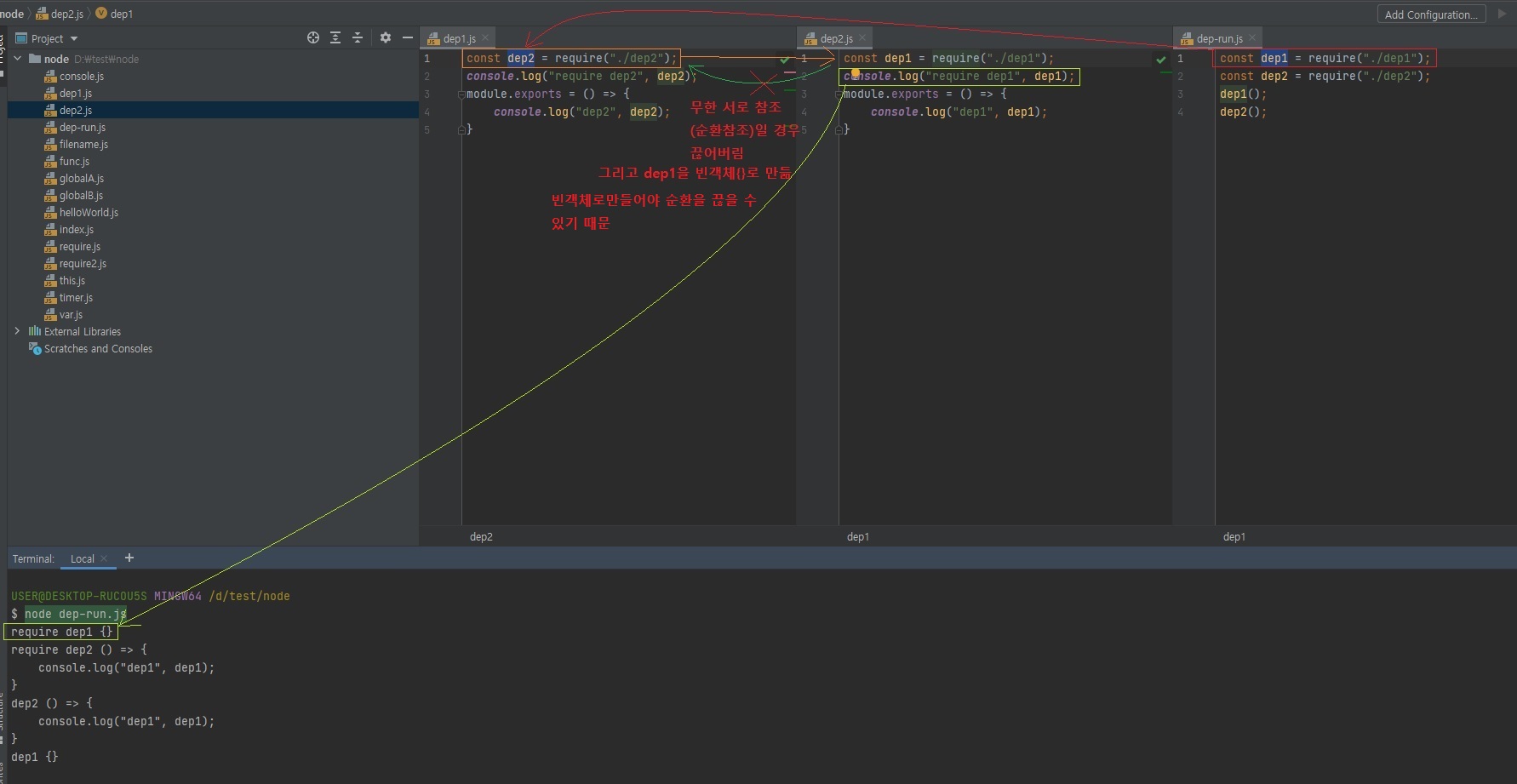
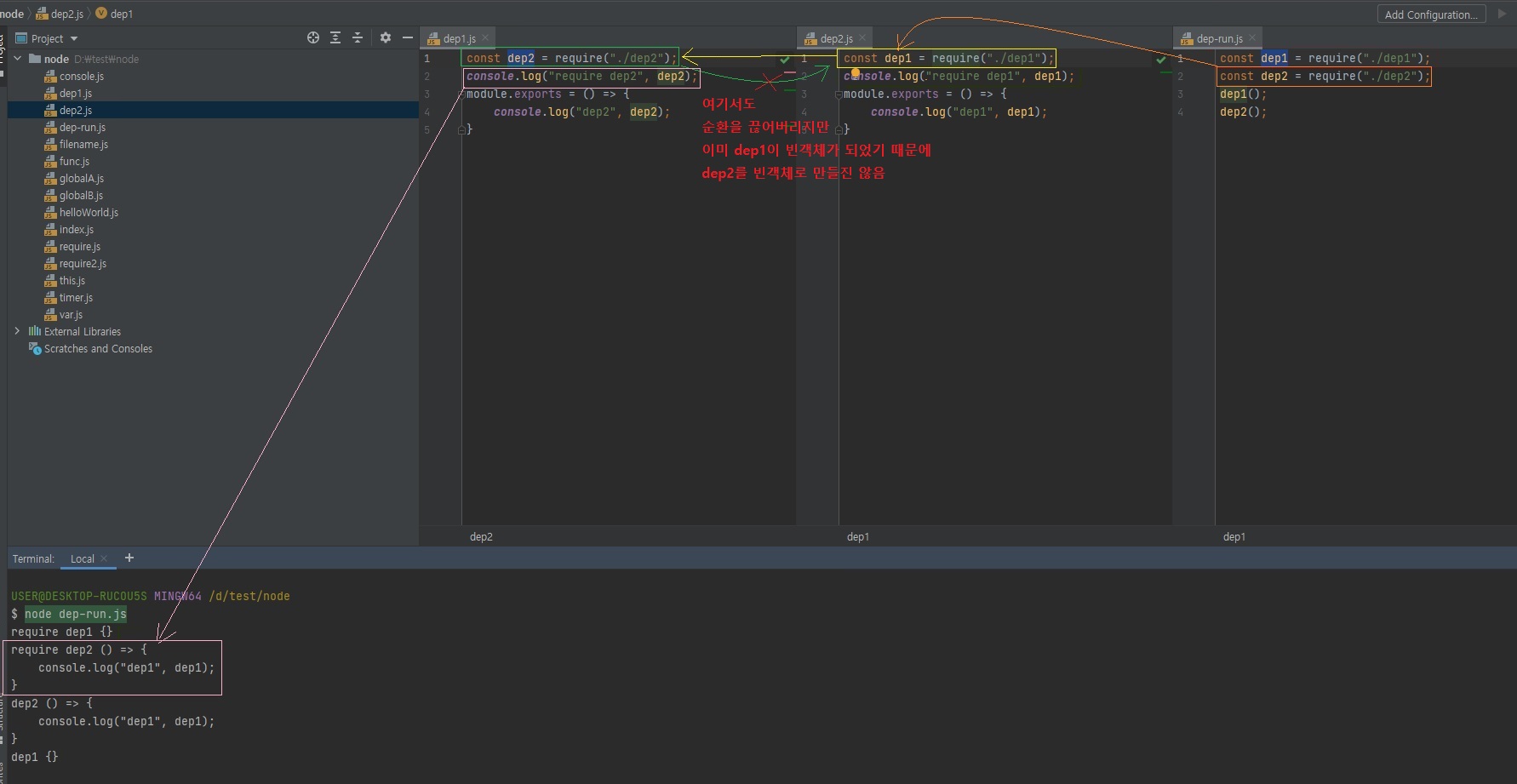
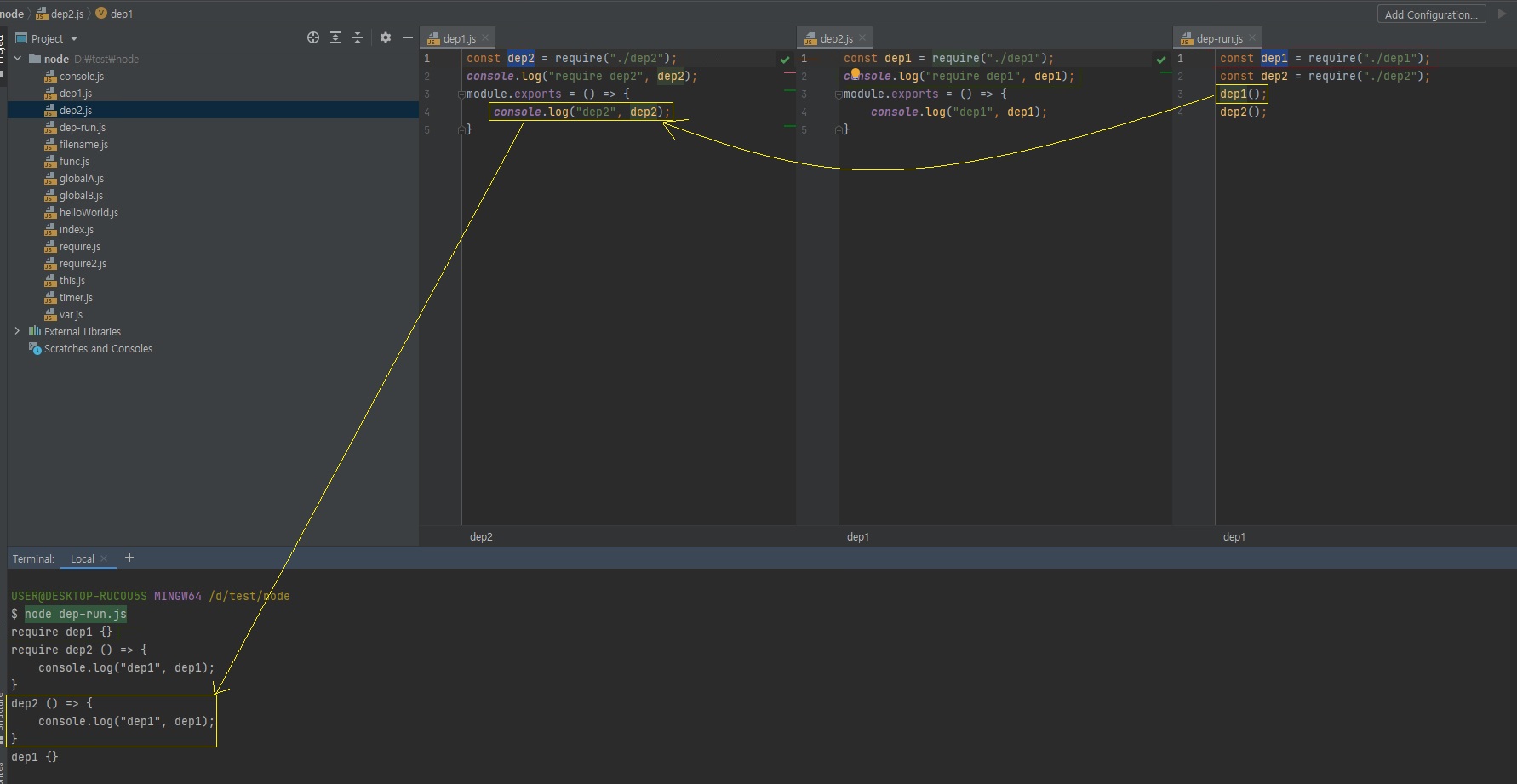
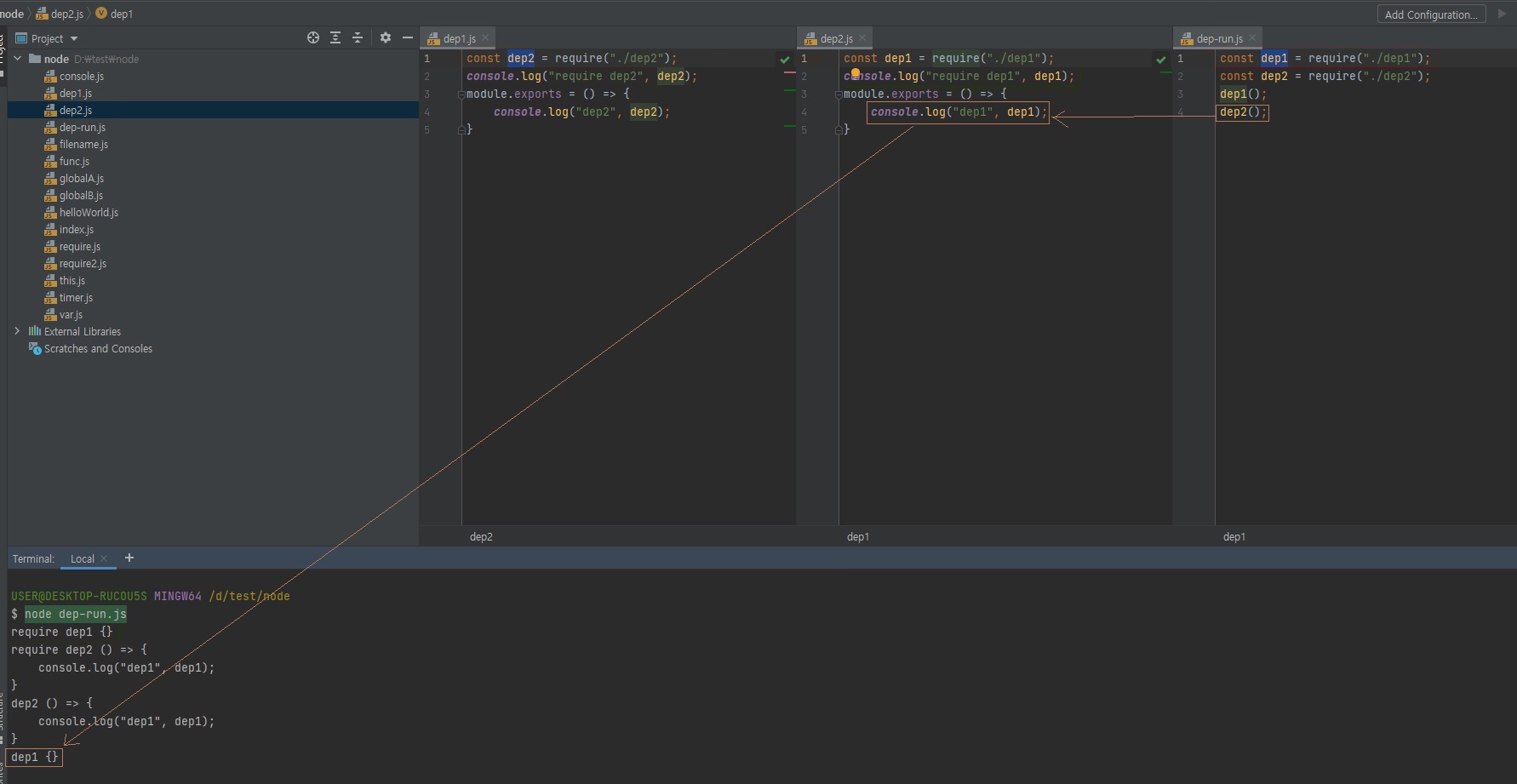
이걸 알면 순환참조를 쓰셔도 되겠죠?
하지만 웬만하면 순환참조는 없는게 낫죠.
복잡하고 직관적이지 않으니깐.
require.cache와 비슷한겁니다.
그렇게 정확하게 작동하는 것을 알면 쓰셔도되는데, 그래도 복잡한건 안하시는게 낫습니다.
복잡한건 실수할 확률이 있거든요.그래서 최대한 이런 순환잠조 되는 상황은 피해주시는게 마음에 편하실거에요.
- dep1이 dep2를
3.6 process
노드는 file system에 접근할 수 있는 것처럼 "운영체제"에도 접근할 수 있습니다.
그리고 컴퓨터가 언제 켜졌는지에도 접근할 수가 있습니다.
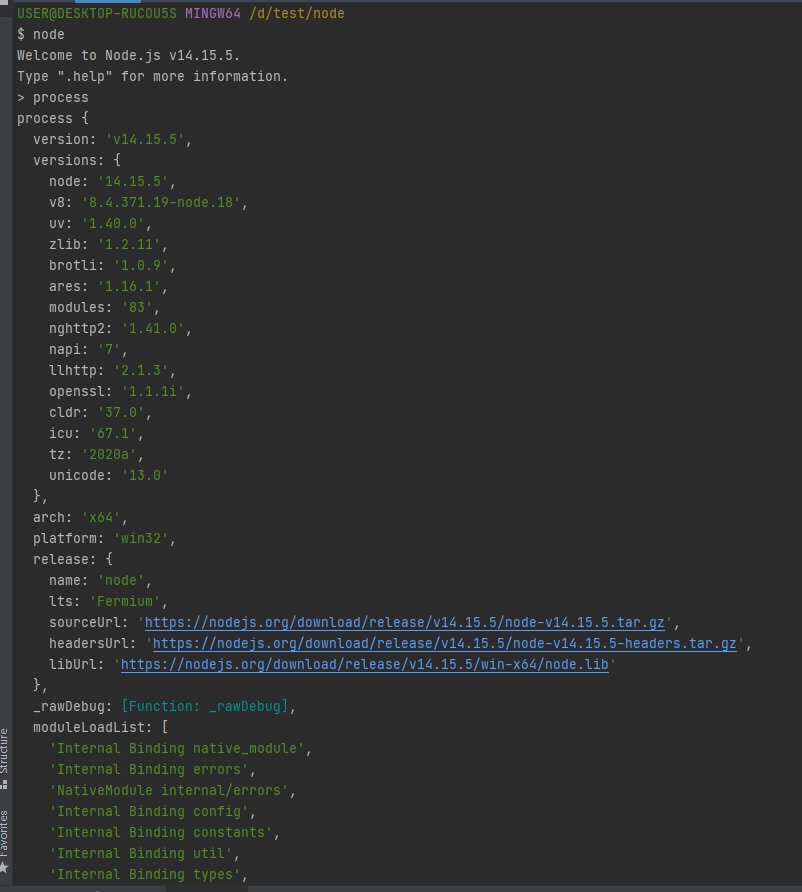
제가 노드를 실행하면 process가 하나가 뜬다고했죠?
그 process 안에 현재 실행중인 process에 대한 정보들이 엄청 많이 들어있는데, 노드의 버전이라던지, 윈도우 아키텍처(arm, ia32 등), 윈도우 운영체제(win32라던지, linux, darwin(mac), freebsd 등등) 같은 정보를 볼 수 있습니다.
-
현재 실행중인 노드 프로세스에 대한 정보를 담고 있음
-
컴퓨터마다 출력값이 다를 수 있음
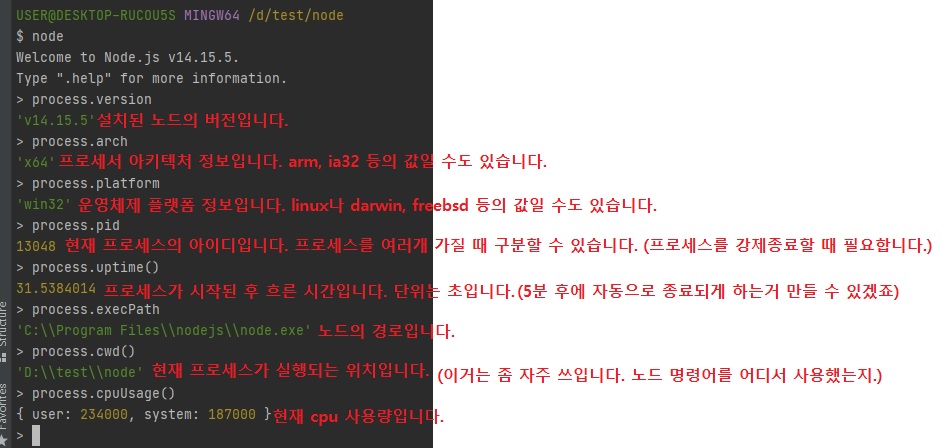
파일 경로 알아내는 것 중에 2가지
- 여튼
__filename,__dirname
__언더 스코어 두번, double underscore라고 해서 줄여서 dunder라고 합니다. process.cwd()
- 여튼
-
3.6.1 process.env
시스템 환경변수란?
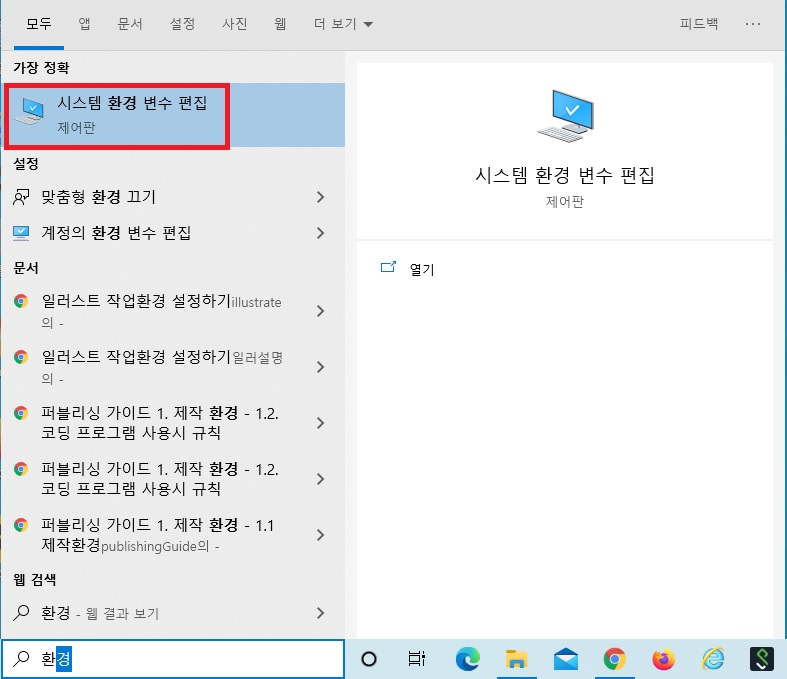
이런게 process.env에 들어있습니다.
-
시스템 환경 변수들이 들어있는 객체
- 비밀키(데이터베이스 비밀번호, 서드파티 앱 키 등)를 보관하는 용도로도 쓰임
-
환경변수는
process.env로 접근 가능.
아래 코드처럼 환경 변수에 직접 값을 넣기도 합니다.
비밀 키 같은 경우는process.env안에 넣어서 나중에 불러오기도 합니다.
소스 코드 안에다가 비밀 키를 넣어버리면 해킹당했을 시 위험하니까,process.env안에다 비밀키를 넣고 아래 코드처럼 가져옵니다.
그럼 소스 코드에는process.env.SECRET_ID이렇게 적혀있지 실제 비밀 키는 안 적혀있잖아요.
즉, 이런식으로 비밀키를 저장하는 용도로도 사용됩니다.const secretId = process.env.SECRET_ID; const secretCode = process.env.SECRET_CODE; -
일부 환경 변수는 노드 실행시 영향을 미침.
노드가 메모리를 처음엔 조금만 사용하는데, 그러다보면 자바스크립트 코드를 실행하다가 서버가 펑 터져버릴 수도 있습니다. 메모리가 부족해서.
그럴 때는 아래처럼 메모리를 늘리는 코드도 있고, 스레드 풀, 이건 백그라운드와 관련있는데, 백그라운드에서 아무리 동시에 많이 돌아간다고해도 실제로는 동시에 돌아가는 갯수가 정해져있습니다.
보통 4개씩 돌아가는걸로 제가 기억을 하고있는데, 복잡한 작업일 경우 4개로는 부족한 경우도 있습니다.
그럼 아래와 같이UV_THREADPOOL_SIZE사이즈를 8로 늘리면 노드에서 8개까지 동시에 돌릴 수 있습니다. -
예시)
NODE_OPTIONS(노드 실행 옵션),UV_THREADPOOL_SIZE(스레드풀 개수)-
max-old-space-size는 노드가 사용할 수 있는 메모리를 지정하는 옵션NODE_OPTIONS=--max-old-space-size=8192 UV_THREADPOOL_SIZE=8
-
3.6.2 process.nextTick(콜백)
-
이벤트 루프가 다른 콜백 함수들보다
nextTick의 콜백 함수를 우선적으로 처리함- 너무 남용하면 다른 콜백 함수들 실행이 늦어짐
- 비슷한 경우로
promise가 있음(nextTick처럼 우선순위가 높음) -
아래 예제에서
setImmediate,setTimeout보다promise와nextTick이 먼저 실행됨// nextTick.js setImmediate(() => { console.log("immediate"); }) process.nextTick(() => { console.log("nextTick"); }) setTimeout(() => { console.log("timeout"); }, 0) Promise.resolve().then(() => console.log("promise")); // nextTick // promise // timeout // immediate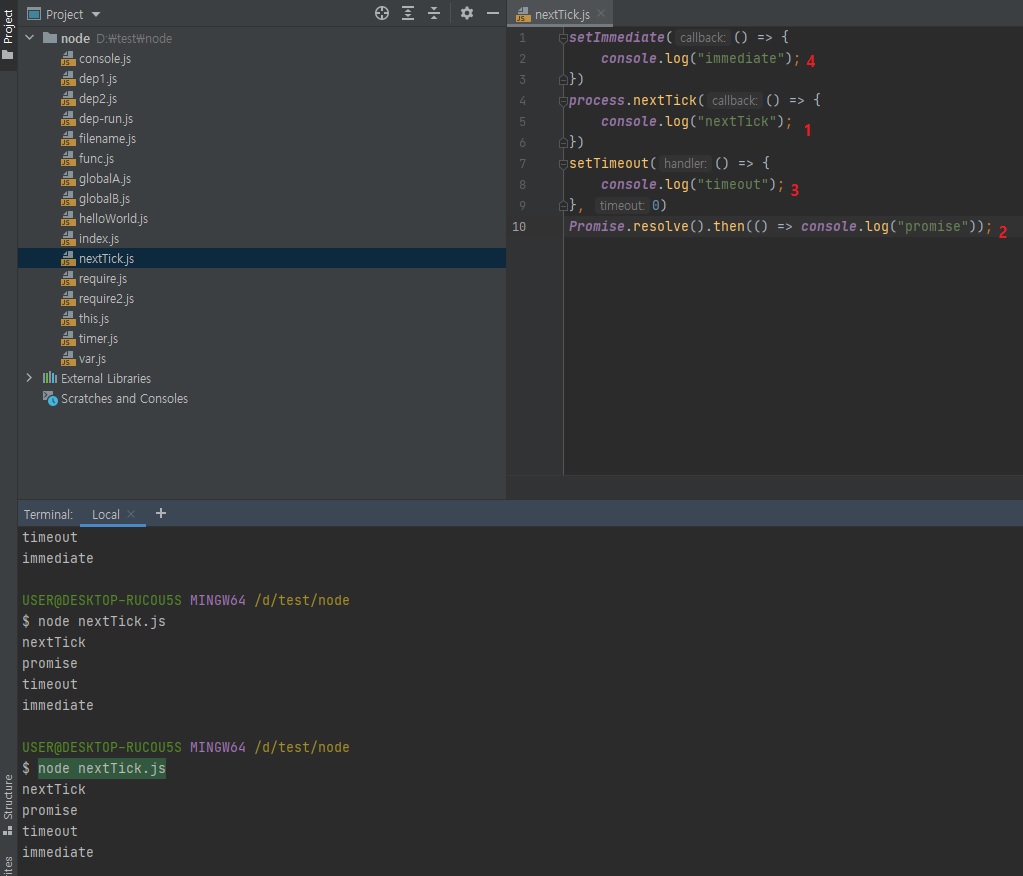
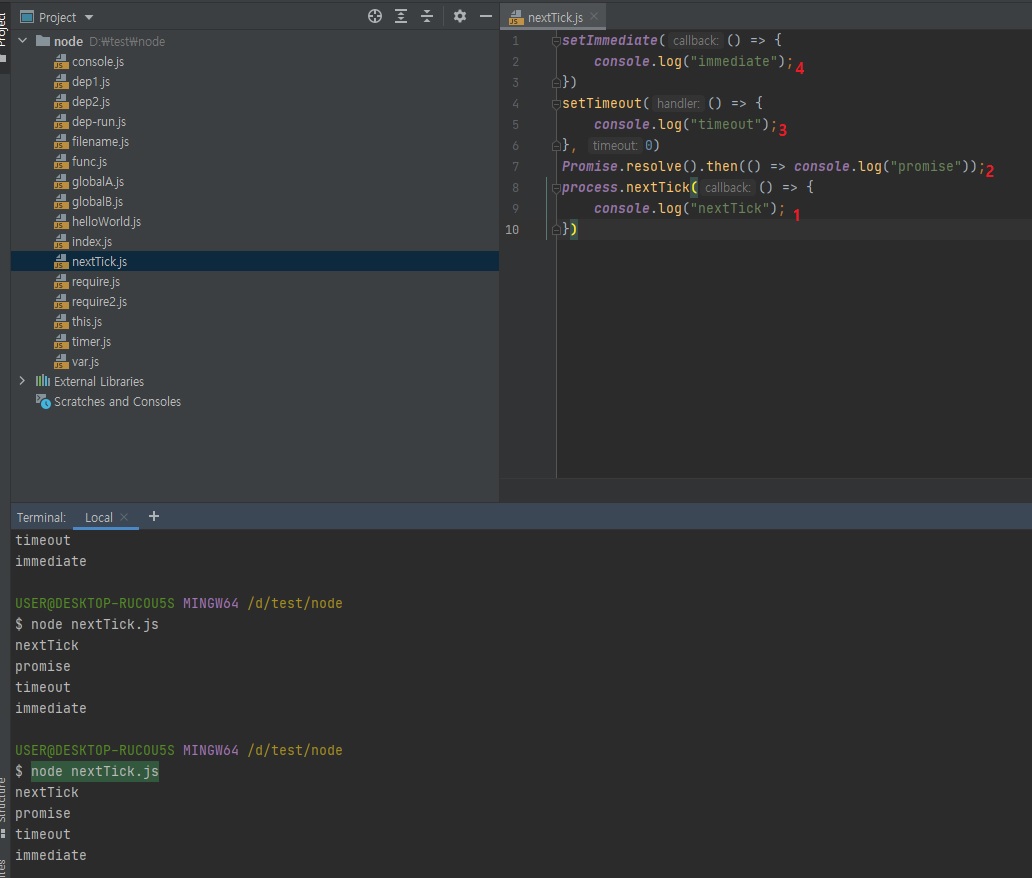
코드를 보면 직관적으로 맨 위부터 순서대로 실행될 것 같지만, 위에서 말씀드렸다시피 새치기를 합니다.
nextTick은 마이크로 테스크라는 우선순위가 있는 테스크 큐에 있어서 새치기를해 제일 먼저 실행됩니다.
promise도 그 다음에 바로 실행됩니다.
nextTick과promise둘 다 마이크로 테스크니까 얘네 둘 끼리는 순서가 지켜집니다.(nextTick->Promise)우선순위가 없는 타임아웃 함수끼리는 순서가 지켜질줄 알았는데
setTimeout(콜백, 0)이 먼저 실행되고setImmediate가 그 다음에 실행됩니다.
그래서 위 코드만 보면 순서가 완전 난장판이죠?- 한가지 규칙은 마이크로 테스크가 먼저 실행된다는 것.
- 그리고
setTimeout(콜백, 0)과setImmediate는 둘 중에 누가먼저 실행될지 모릅니다.
정확히 말하면 랜덤은 아니지만, 환경에 따라서 어떨 때는setImmediate가 먼저 실행되고 어떨 때는setTimeout(콜백, 0)이 먼저 실행되는데, 이거 헷갈리므로setTimeout(콜백, 0)은 쓰지 마시고 노드에서는setImmediate만 쓰라고 말씀을 드리는겁니다.
3.6.3 process.exit(코드)
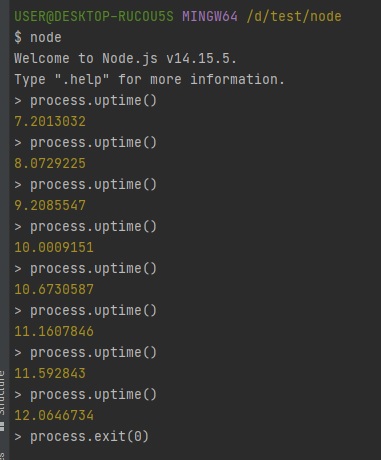
node 명령어를 입력하면 노드가 실행된겁니다.
노드가 실행됐으므로 process가 뜨겠죠?
process.uptime()으로 노드를 실행한지 몇초가 지났는지 체크해봅니다.
그리고 process.exit(0) 명령어로 노드를 종료합니다.
이런걸 언제쓸까?
가끔씩 서버를 종료하고 싶을 때, 그 서버 안에서 process.exit(0)를 해주면 서버가 종료됩니다.
process.exit(0) 자체는 많이 쓰이진 않는데 가끔 쓰입니다.
process.exit(1)이라고 할 수도 있는데, 이게 0이 아니면 에러가 있는겁니다.
0이면 에러 없이 종료된 거고, 1이면 에러가 있이 꺼진건데, 혹시 에러났을 때 에러났다는 걸 알리고 종료하기위해서 process.exit(1) 이렇게 많이합니다.
process.exit(0)은 보통 잘 안쓰는데, process.exit(1)은 서버에서 에러가 있는 경우에 에러가 있다고 알리고 끄기위해 자주 사용합니다.
-
현재의 프로세스를 멈춤
- 코드가 없거나 0이면 정상 종료
-
이외의 코드는 비정상 종료를 의미함
// exit.js let i = 1; setInterval(() => { if (i === 5) { console.log("종료!"); process.exit(); } console.log(i); i += 1; }, 1000)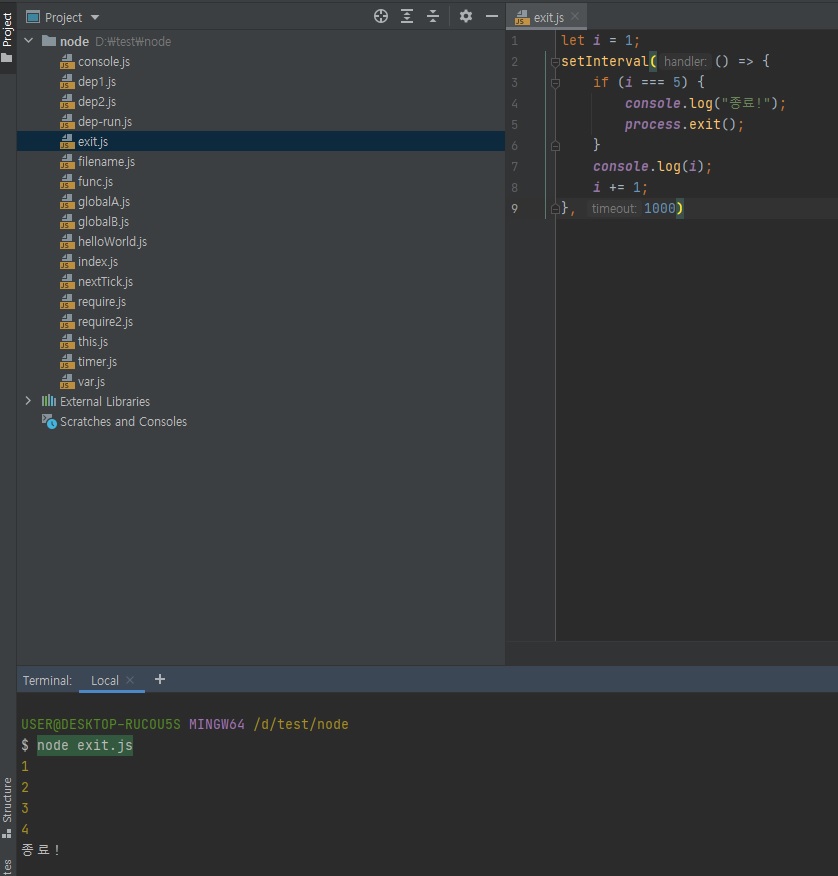
노드 내장 객체들
- global
- require
- module
- __filename, __dirname
- process
– 여기서부턴 노드 내장 모듈 –
3.7 os와 path
3.7.1 os
operation system.
process와 어느정도 겹치는 면도 있습니다.
-
운영체제의 정보를 담고 있음
-
모듈은 require로 가져옴(내장 모듈이라 경로 대신 이름만 적어줘도 됨)
// os.js const os = require("os"); console.log("운영체제 정보----------------------------------------"); console.log("os.arch():", os.arch()); console.log("os.platform():", os.platform()); console.log("os.type():", os.type()); console.log("os.uptime():", os.uptime()); console.log("os.hostname():", os.hostname()); console.log("os.release():", os.release()); console.log("경로------------------------------------------------"); console.log("os.homedir():", os.homedir()); console.log("os.tmpdir():", os.tmpdir()); console.log("cpu 정보--------------------------------------------"); console.log("os.cpus():", os.cpus()); console.log("os.cpus().length:", os.cpus().length); console.log("메모리 정보------------------------------------------"); console.log("os.freemem():", os.freemem()); console.log("os.totalmem():", os.totalmem());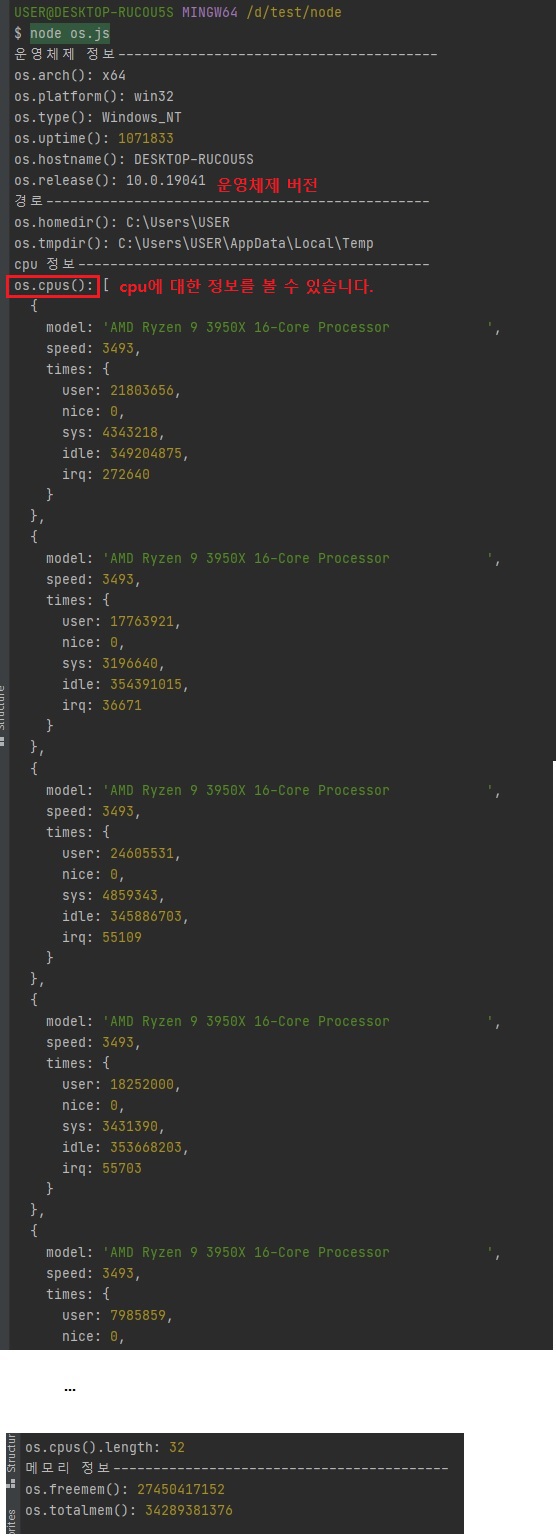
os.cpus()가 왜 중요하냐면, 노드가 싱글 스레드라고 했잖아요?
나중에 서버를 띄울 때, 제가 CPU가 6개가 있으면 그 중에서 CPU를 하나밖에 사용을 안합니다.
그럼 나머지 5개 놀고있죠?
5개 놀고있으니까, 제가 서버를 효율적으로 구성하려면 서버를 6개 띄우면 되겠죠.
그런데 그 6이라는 숫자를 알아내기 위해서는os.cpus()라는 걸 사용을 해야됩니다.왜냐하면 어떤 컴퓨터는 코어가 하나만 있을 수도 있고 어떤 컴퓨터는 8개, 라이젠 같이 팔이 여러개 달린거는 32개가 될 수도 있습니다.
라이젠 같은 경우는 서버를 한번에 32개를 띄울 수도 있고 그러거든요?
그래서 이게 환경마다 다르기 때문에os.cpus()메소드로 정확히 코어가 몇개인지를 알아내야됩니다.참고로
os에서 난 8코어 16스레드다, 16코어 32스레드다, 이렇게 여기서 말하는 스레드랑 1강 때 말씀드렸던 프로세스, 스레드와 다른 스레드입니다.
os의 스레드랑 노드의 스레드는 다른 스레드입니다.
개념을 혼동하지 않으시는게 좋고, 예를 들어 8코어 16스레드라고 하면 코어가 16개라고 생각하시면 됩니다.
여튼 하드웨어에서 쓰이는 용어와 노드에서 쓰이는 용어의 개념이 다를 수 있다는거
-
3.7.2 os 모듈 메소드
-
os.arch():process.arch와 동일합니다.os.platform():process.platform과 동일합니다.os.type(): 운영체제의 종류를 보여줍니다.os.uptime(): 운영체제 부팅 이후 흐른 시간(초)을 보여줍니다.process.uptime()은 노드의 실행 시간이었습니다.os.hostname(): 컴퓨터의 이름을 보여줍니다.os.release(): 운영체제의 버전을 보여줍니다.os.homedir(): 홈 디렉토리 경로를 보여줍니다.os.tmpdir(): 임시 파일 저장 경로를 보여줍니다.os.cpus(): 컴퓨터의 코어 정보를 보여줍니다.os.freemem(): 사용 가능한 메모리(RAM)를 보여줍니다.os.totalmem(): 전체 메모리 용량을 보여줍니다.
3.7.3 path
-
폴더와 파일의 경로를 쉽게 조작하도록 도와주는 모듈
-
운영체제별로 경로 구분자가 다름(Windows: ‘\', POSIX: ‘/')
윈도우에서는\or\\이 표시로 구분을 하고, 리눅스, mac에선/이 표시로 구분을 합니다.
리눅스와 mac을 합쳐서 POSIX라고 부릅니다.운영체제마다 분기 처리해주는게 너무 귀찮은 일입니다.
그런데path모듈을 쓰시면 알아서 이 부분을 처리를 해줍니다.
경로 처리를 하실 때에는 웬만하면path모듈을 쓰시는게 좋습니다.다른 언어에서도 이런
path모듈을 다 제공을 합니다.
왜냐하면 운영체제마다 다른 파일 경로 구분법은 프로그래머들을 몇십년간 골머리썩혀왔던 것이기 때문에 다 제공을 합니다.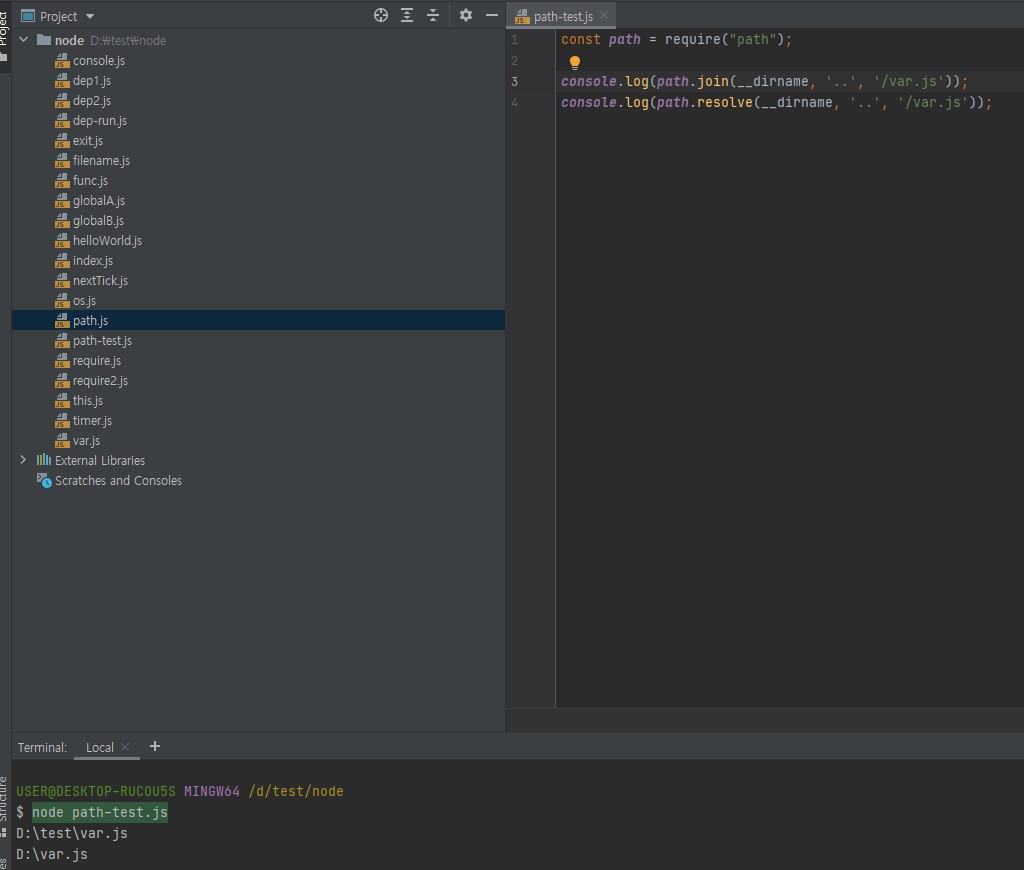
path.join(__dirname, '..', 'var.js'): 현재 디렉토리 위치가test\node라면test\var.js라고 나옵니다.
..이걸로 부모 폴더로 올라가기 때문.
POSIX에선test/var.js라고 나올 것입니다.
join은 절대 경로를 무시합니다.
- path.resolve(__dirname, '..', '/var.js'):
/var.js이거를 절대 경로라고 하는데resolve는 절대 경로를 무시하지 않습니다.
대신 앞에 인자들__dirname,..이것들이 무시됩니다.// path.js const path = require("path"); const string = __filename; console.log("path.sep:", path.sep); console.log("path.delimiter:", path.delimiter); console.log("----------------------------"); console.log("path.dirname():", path.dirname(string)); console.log("path.extname():", path.extname(string)); console.log("path.basename():", path.basename(string)); console.log("path.basename - extname:", path.basename(string, path.extname(string))); console.log("----------------------------"); console.log("path.parse()", path.parse(string)); console.log("path.format():", path.format({ dir: "D:\\test\\node", name: "path", ext: ".js", })) console.log("path.normalize():", path.normalize("D://test\\\\node\\\path.js")); console.log("----------------------------"); console.log("path.isAbsolute(D:\\):", path.isAbsolute("D:\\")); console.log("path.isAbsolute(./home):", path.isAbsolute("./home")); console.log("----------------------------"); console.log("path.relative():", path.relative("D:\\test\\node\\path.js", "D:\\")); console.log("path.join():", path.join(__dirname, "..", "..", "/test", ".", "/node")); console.log("path.resolve():", path.resolve(__dirname, "..", "/test", ".", "/node"));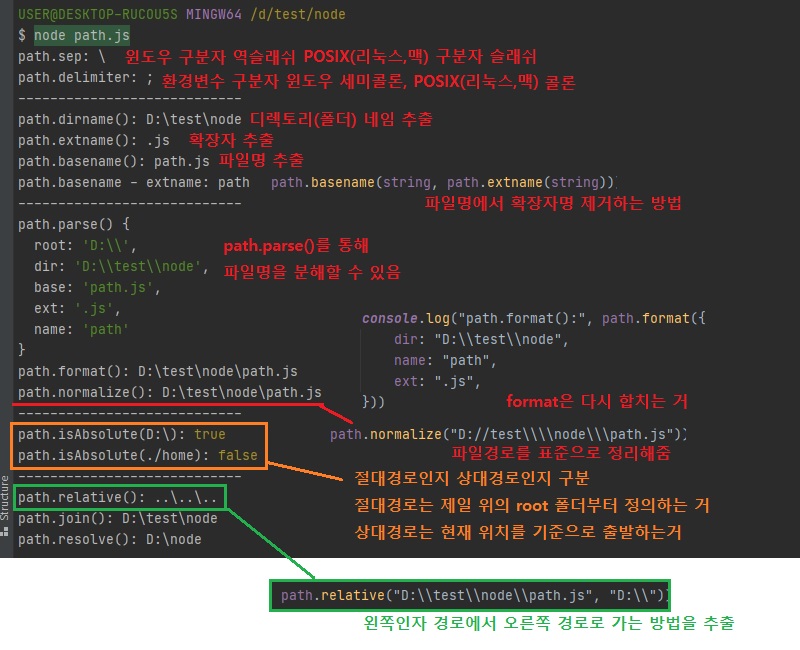
-
3.7.4 path 모듈 메소드
path.sep: 경로의 구분자입니다. Windows는 \, POSIX는 /입니다.path.delimiter: 환경 변수의 구분자입니다.
process.env.PATH를 입력하면 여러 개의 경로가 이 구분자로 구분되어 있습니다.
Windows는 세미콜론(;)이고 POSIX는 콜론(:)입니다.path.dirname(경로): 파일이 위치한 폴더 경로를 보여줍니다.path.extname(경로): 파일의 확장자를 보여줍니다.path.basename(경로, 확장자): 파일의 이름(확장자 포함)을 보여줍니다.
파일의 이름만 표시하고 싶다면basename의 두번째 인자로 파일의 확장자를 넣어주면 됩니다.path.parse(경로): 파일 경로를 root, dir, base, ext, name으로 분리합니다.path.format(객체): path.parse()한 객체를 파일 경로로 합칩니다.path.normalize(경로): /나 \를 실수로 여러번 사용했거나 혼용했을 때 정상적인 경로로 변환해줍니다.path.isAbsolute(경로): 파일의 경로가 절대경로인지 상대경로인지 true나 false로 알려줍니다.path.relative(기준경로, 비교경로): 경로를 두 개 넣으면 첫번째 경로에서 두번째 경로로 가는 방법을 알려줍니다.path.join(경로, .. .): 여러 인자를 넣으면 하나의 경로로 합쳐줍니다.
상대 경로인 ..(부모 디렉토리)과 .(현 위치)도 알아서 처리해줍니다.path.resolve(경로, .. .): path.join()과 비슷하지만 차이가 있습니다.
차이점은 다음에 나오는 Note에서 설명합니다.
3.7.5 알아둬야할 path 관련 정보
-
join과resolve의 차이:resolve는/를 절대경로로 처리,join은 상대경로로 처리- 상대경로: 현재 파일 기준. 같은 경로면 점 하나(.), 한 단계 상위 경로면 점 두개(..)
-
절대경로는 루트 폴더나 노드프로세스가 실행되는 위치가 기준
path.join("/a", "/b", "c"); // /a/b/c path.resolve("/a", "/b", "c"); // /b/c
\\와\차이:\는 윈도 경로 구분자,\\는 자바스크립트 문자열 안에서 사용(\가 특수문자라\\로 이스케이프 해준 것)-
윈도에서 POSIX path를 쓰고 싶다면:
path.posix객체 사용- POSIX에서 윈도 path를 쓰고 싶다면:
path.win32객체 사용
- POSIX에서 윈도 path를 쓰고 싶다면:
3.8 url와 querystring
3.8.1 url 모듈
-
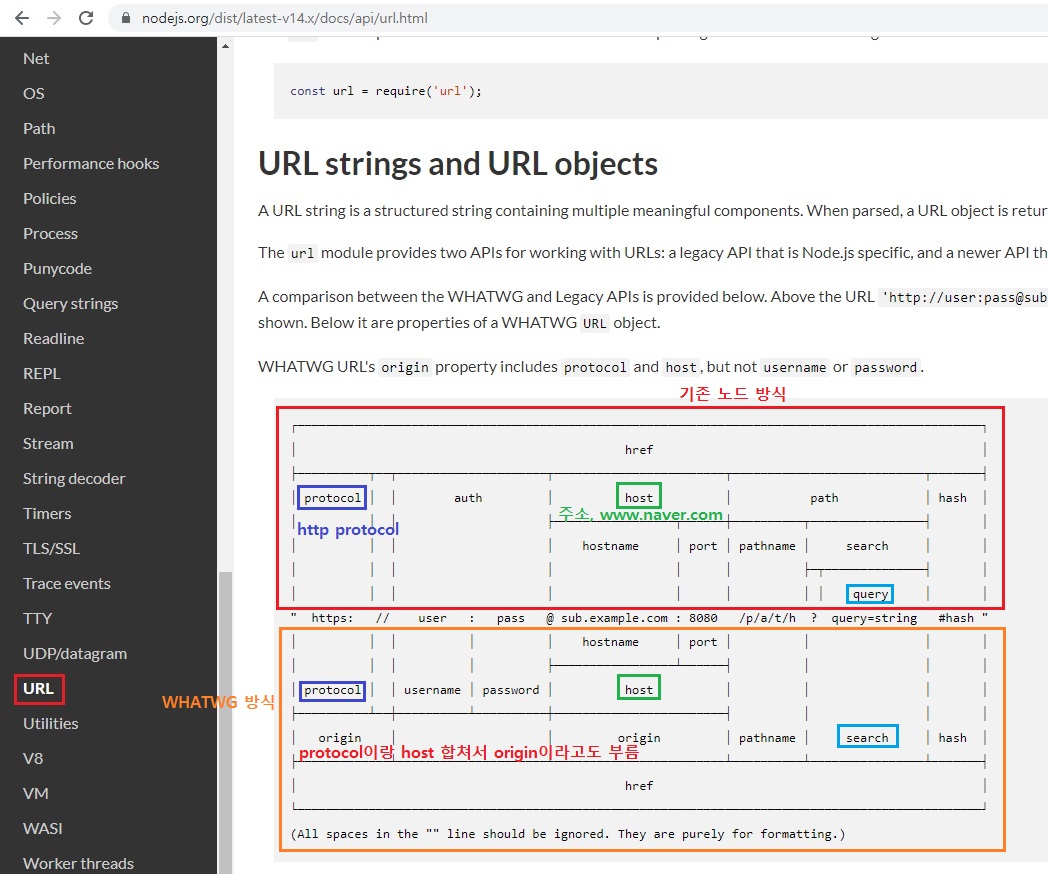
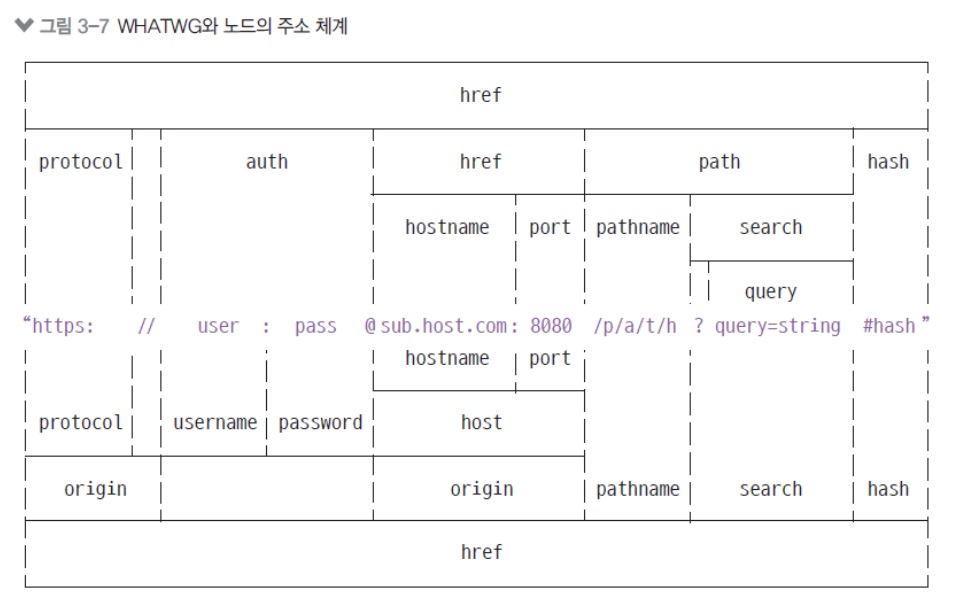
주소에 대한 명칭을 2가지 단체에서 다르게 부르는데 위에는 노드에서 부르는 방식, 밑에는 WHATWG에서 부르는 방식입니다.
보시면 약간 차이가 있습니다. -
인터넷 주소를 쉽게 조작하도록 도와주는 모듈
- url 처리에 크게 두 가지 방식이 있음(기존 노드 방식 vs WHATWG 방식)
-
아래 그림에서 가운데 주소를 기준으로 위쪽은 기존 노드 방식, 아래쪽은 WHATWG 방식
3.8.2 url 모듈 예제
// url.js
const url = require("url");
// WHATWG 방식
const { URL } = url;
const myURL = new URL("http://www.gilbut.co.kr/book/bookList.aspx?sercate1=001001000#anchor");
console.log("new URL():", myURL);
console.log("url.format():", url.format(myURL));
console.log("--------------------------------------");
// 기존 NODE 방식
const parsedUrl = url.parse("https://www.gilbut.co.kr/book/bookList.aspx?sercate1=001001000#anchor");
console.log("url.parse():", parsedUrl);
console.log("url.format():", url.format(parsedUrl));
-
url 모듈 안에 URL 생성자가 있습니다.
이 생성자에 주소를 넣어 객체로 만들면 주소가 부분별로 정리됩니다.
이 방식이 WHATWG의 url입니다.
WHATWG에만 있는 username, password, origin, searchParams 속성이 존재합니다.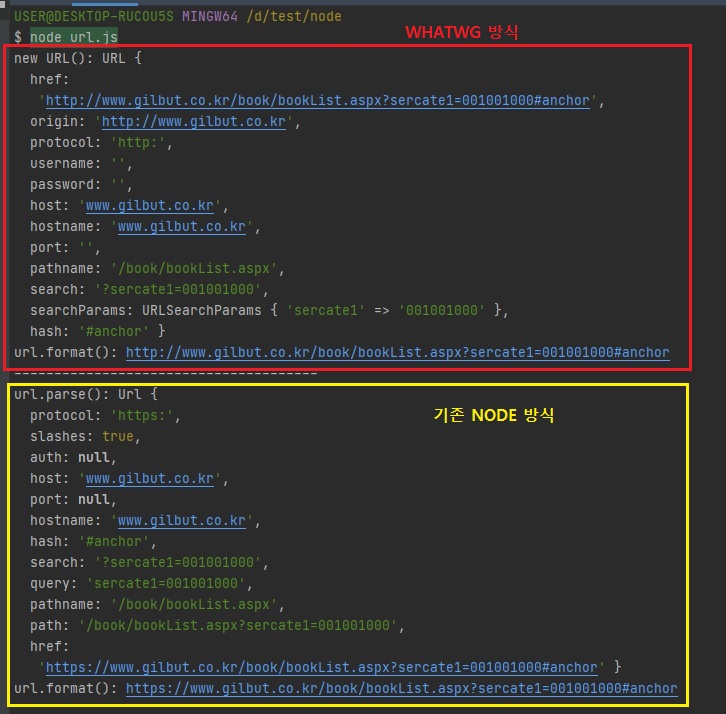
조금 더 최신이고 세련된 방식은 WHATWG 방식인데, 기존 NODE 방식도 사용되긴 합니다.
기존 방식이 쓰이는 이유는 주소가https:www.naver.com/login이렇게 오면 좋거든요?
그런데 가끔가다가 주소가/login이렇게만 올 때가 있습니다.
앞 부분은 생략을 하고 인터넷 주소가/login이렇게만 오는 경우에는 이게 WHATWG 방식으론 해석이 안돼서 기존 모듈을 사용합니다.
그래서 WHATWG와 기존 모듈이 공존하는 이유가 위 처럼 앞 주소가 생략되는 경우 때문에 그렇습니다.
3.8.3 url 모듈 메소드
-
기존 노드 방식 메소드
-
url.parse(주소): 주소를 분해합니다.
WHATWG 방식과 비교하면 username과 password 대신 auth 속성이 있고, searchParams 대신 query가 있습니다. -
url.format(객체): WHATWG 방식의 url과 기존 노드의 url 모두 사용할 수 있습니다.
분해되었던 url 객체를 다시 원래 상태로 조립합니다.
-
3.8.4 searchParams
-
WHATWG 방식에서 쿼리스트링(search) 부분 처리를 도와주는 객체
-
?page=3&limit=10&category=nodejs&category=javascript 부분
위와 같은 부분을 search(WHATWG 명칭) 또는 쿼리스트링(기존 노드 명칭) 부분이라고 합니다.
쿼리스트링은?에서부터 시작되는데, 문자열입니다.
이 부분에 정보들이 담겨있습니다.
이게 주소에다 데이터를 담는 방법인데, 위와 같이?뒤에 저런식으로 달린 주소를 많이 보셨을 거에요.
보통 쇼핑몰 사이트가면 많이 볼 수 있거든요? 게시판이나.위 쿼리스트링을 보면
page=3페이지는 3번이고,limit=10한번에 가져올 수 있는 게시글은 10개이고category=nodejs카테고리는 nodejs이고 그 다음category는 javascript라는 뜻.
즉, 이런식으로 주소에 데이터가 담겨져있는 겁니다.그런데 이게 문자열이라 자바스크립트에서 다루기 좀 불편하거든요?
그래서 이를 개체로 바꿔주는 것이 바로searchParams입니다.// searchParams.js const {URL} = require("url"); const myURL = new URL("http://www.gilbut.co.kr/?page=3&limit=10&category=nodejs&category=javascript"); console.log("searchParams:", myURL.searchParams); console.log("searchParams.getAll():", myURL.searchParams.getAll("category")); console.log("searchParams.get():", myURL.searchParams.get("limit")); console.log("searchParams.has():", myURL.searchParams.has("page")); console.log("searchParams.keys():", myURL.searchParams.keys()); console.log("searchParams.values():", myURL.searchParams.values()); myURL.searchParams.append("filter", "es3"); myURL.searchParams.append("filter", "es5"); console.log(myURL.searchParams.getAll("filter")); myURL.searchParams.set("filter", "es6"); console.log(myURL.searchParams.getAll("filter")); myURL.searchParams.delete("filter"); console.log(myURL.searchParams.getAll("filter")); console.log("searchParams.toString():", myURL.searchParams.toString()); myURL.search = myURL.searchParams.toString();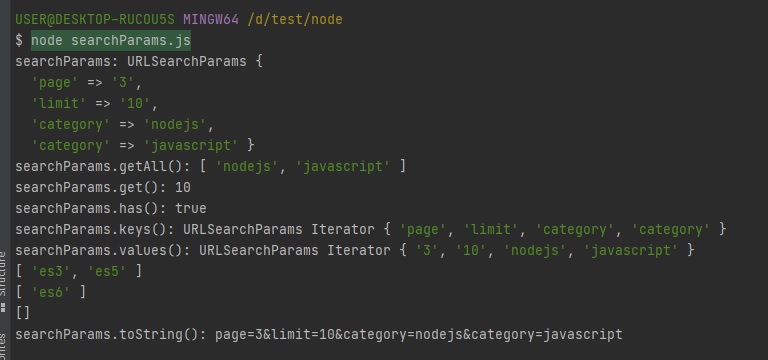
-
3.8.4 searchParams 예제 결과
getAll(키): 키에 해당하는 모든 값들을 가져옵니다. category에는 두 가지 값, 즉 nodejs와 javascript의 값이 들어있습니다.get(키): 키에 해당하는 첫번째 값만 가져옵니다.has(키): 해당 키가 있는지 없는지를 검사합니다.keys(): searchParams의 모든 키를 반복기(iterator, ES2015 문법) 객체로 가져옵니다.values(): searchParams의 모든 값을 반복기 객체로 가져옵니다.append(키, 값): 해당 키를 추가합니다. 같은 키의 값이 있다면 유지하고 하나 더 추가합니다.set(키, 값): append와 비슷하지만 같은 키의 값들을 모두 지우고 새로 추가합니다.delete(키): 해당 키를 제거합니다.toString(): 조작한 searchParams 객체를 다시 문자열로 만듭니다. 이 문자열을 search에 대입하면 주소 객체에 반영됩니다.
그리고 아까 URL에 WHATWG 방식과 기존 노드 방식이 있다고 했죠?
둘 다 쓰인다고 했죠?
searchParams도 마찬가지입니다.
WHATWG 방식이 searchParams이고 기존 노드는 querystring입니다.
3.8.5 querystring
똑같이 querystring를 처리 가능.
searchParams가 조금 더 기능이 많아서 편하긴 하지만 간단한걸 처리하신다 하시면 querystring 모듈로 parse 하시면 됩니다.
URL을 분석하는 부분도 나중에 예제로 다뤄보겠습니다.
-
기존 노드 방식에서는 url querystring을 querystring 모듈로 처리
- querystring.parse(쿼리): url의 query 부분을 자바스크립트 객체로 분해해줍니다.
-
querystring.stringify(객체): 분해된 query 객체를 문자열로 다시 조립해줍니다.
// querystring.js const url = require("url"); const querystring = require("querystring"); const parsedUrl = url.parse("http://www.gilbut.co.kr/?page=3&limit=10&category=nodejs&category=javascript"); const query = querystring.parse(parsedUrl.query); console.log("querystring.parse():", query); console.log("querystring.stringify():", querystring.stringify(query)); Note
Note3강은 알아두셔야될게 내장 객체/모듈이 많잖아요?
그런데 이런거 직접 안써보시면 와닿지가 않아요. 언제써야되는지.
그런데 나중에 9강부터 실제 예제를 하는데, 실제 예제에서 사용하시면 “아 이게 그래서 필요했구나.”라고 그때 와닿으실거니깐 지금은 그냥 이런게 있구나하고 넘어가시면 됩니다.
외울 필요 없습니다.
3.9 crypto와 util
3.9.1 단방향 암호화(crypto)
암호화하는 것은 멀티스레드로 돌아간다고 했습니다.
암호화하는 것은 워낙 CPU를 많이 잡아먹어서 멀티 스레드로 돌아갑니다.
-
암호화는 가능하지만 복호화는 불가능
- 암호화: 평문을 암호로 만듦
hyungju-lee(평문)라는 단어가 있으면 이를 암호로 만드는 것입니다. - 복호화: 암호를 평문으로 해독
- 암호화: 평문을 암호로 만듦
-
단방향 암호화의 대표 주자는 해시 기법
가장 오개념 중에 하나가 비밀번호를 암호화한다고 하는데 비밀번호는 암호화가 아닙니다.
비밀번호는 암호화가 아니라 해시라고하는데 편의상 이것도 암호화라고 말을 하지만, 엄밀하게 말하면 암호화는 아니고 해시라는 것입니다.
해시는 뭐냐면 평문을 어떤 암호같이 만듭니다.
그런데 그 암호를 다시 평문으로 되돌릴 수가 없습니다.
암호는 평문을 암호로 만들었다가 암호를 다시 평문으로 만들 수 있는데 해시는 평문을 해시로 만들었다가 해시를 다시 평문으로 되돌리기는 매우 어렵습니다.
보통 이런게 비밀번호에서 많이 쓰입니다. (해시함수)아니 그럼 제가 hyungju-lee라는 비밀번호를 저장했는데 그걸 다시 hyungju-lee로 몬돌리면 어떻게해요?라고 생각하실 수도 있는데 해시의 특징은 예를 들어,
abcdefgh이러한 특정한 비밀번호가 있다, 그러면 이게 해시화돼서qvew로 바뀌었다고 치면,abcdefgh얘는 언제나 해시화하면 항상 같은 결과가 나옵니다. (qvew)
그러면 서버에선 항상qvew이것을 들고있다가 나중에 제가abcdefgh를 입력하겠죠?
abcdefgh이것을 입력하면 서버에서 해시화했을 때qvew이게 되겠죠?
그럼qvew이거랑 이미 서버에 저장되어있던qvew이거랑 비교하는거지abcdefgh이런 단어는 서버에 어디에도 없습니다.
그러니깐 안전한겁니다.
만약에 서버나 데이터베이스에 제 암호가 실제로 저장되어있다면 해커들이 털어가면 제 암호가 털리는 거잖아요?
그런데 서버에는qvew라는 해시만 남아있습니다.
그래서 해커들이qvew이걸 가져가도abcdefgh이걸로 못돌리는 거거든요.돌릴 수 있는 방법이 아주 없는 것은 아닙니다.
레인보우 테이블이나 브루트포스 이런걸로하면 되는데, 매우 오래걸립니다. 몇십년 걸리거든요?
최신 해시로 하면 몇십년 걸리고 이러기 때문에 해커들이 안하죠. 해커들이 하다가 늙어 죽으니깐.
한 사람 비밀번호 해독하는데만 몇십년 거리는데, 몇백명꺼를 하면 몇천년 걸리겠죠?
그래서 해커들이 시도를 안합니다.그래서 이 해시 기법은 알고리즘만 잘 선택을 하면 매우 안전한 방법이라는 것.
- 문자열을 고정된 길이의 다른 문자열로 바꾸는 방식
-
abcdefgh 문자열 -> qvew

3.9.2 Hash 사용하기 (sha512)
-
createHash(알고리즘): 사용할 해시 알고리즘을 넣어줍니다.
비밀번호를 해시할 때createHash(알고리즘)를 해줍니다.- md5, sha1, sha256, sha512 등이 가능하지만, md5와 sha1은 이미 취약점이 발견되었습니다.
- 현재는 sha512 정도로 충분하지만, 나중에 sha512 마저도 취약해지면 더 강화된 알고리즘으로 바꿔야합니다.
컴퓨터가 발전할수록 기존에 있던 방법들이 점점 더 취약해집니다.
때문에 점점 더 복잡한 알고리즘이 나오고 복잡한 알고리즘을 통해 해시화를 합니다.
update(문자열): 변환할 문자열을 넣어줍니다.-
digest(인코딩): 인코딩할 알고리즘을 넣어줍니다.-
base64, hex, latin1이 주로 사용되는데, 그중 base64가 결과 문자열이 가장 짧아 애용됩니다.
결과물로 변환된 문자열을 반환합니다.// hash.js const crypto = require("crypto"); console.log("base64:", crypto.createHash("sha512").update("비밀번호").digest("base64")); console.log("hex:", crypto.createHash("sha512").update("비밀번호").digest("hex")); console.log("base64:", crypto.createHash("sha512").update("다른 비밀번호").digest("base64"));
여튼 위와 같은 식으로 해시화를 할 수 있습니다.
그런데 해시화를 하고나면 다시 못 되돌린다고 그랬죠?
위에createHash("sha512")알고리즘 먼저 넣어주고 비밀번호는update("비밀번호")에다가 넣어주고.digest("base64")를 넣어줍니다.
보통 base64 많이 쓰입니다.위 스크린샷을 보시면 "비밀번호"라는 단어가 엄청 복잡하게 바뀌죠?
그래서 되돌리기가 엄청 힘든겁니다.
위와 같이 복잡한 것들이 서버에 저장되는거고 "비밀번호"라는 단어는 저장이 안되는 겁니다.그래서 해커들이 이 해시를 보면 해시를 다시 해독하려고는 안하고 다른 방법을 찾습니다.
사람들이 자주하는 실수인데, 비밀번호가 해시화가 잘 되었는지를 확인하기위해console.log로 비밀번호를 찍어보는 분들이 계시거든요?
그럼console.log이런 기록들을 뒤져서 비밀번호를 찾아내거나 아니면 프론트단에서 키보드를 해킹해서 비밀번호를 찾아내지 아예 위처럼 해시화되면 해커들이 시도조차 안합니다.
어차피 복호화 안될 것을 알기 때문에.이런 암호나 정보보호 쪽은 책같은걸 읽어보시는게 더 좋습니다.
-
3.9.3 pbkdf2
비밀번호를 해시화할 때는 createHash를 사용하셔도되는데, pbkdf2라는 알고리즘도 있고 bcrypt라는 알고리즘도 있고 scrypt라는 알고리즘도 있습니다.
비밀번호를 해시화하는데 다양한 알고리즘이 있거든요?
이 중에서 선택을 하시면 되는데 저는 보통 bcrypt를 많이 씁니다.
이 bcrypt는 노드에서 지원을 안하기 때문에 bcrypt 사용 방법은 나중에 9강 때 알려드리도록 하겠습니다.
-
컴퓨터의 발달로 기존 암호화 알고리즘이 위협받고 있음
- sha512가 취약해지면 sha3으로 넘어가야함
- 현재는 pbkdf2나 bcrypt, scrypt 알고리즘으로 비밀본호를 암호화
-
Node는 pbkdf2와 scrypt 지원
3.9.4 pbkdf2 예제
-
컴퓨터의 발달로 기존 암호화 알고리즘이 위협받고 있음
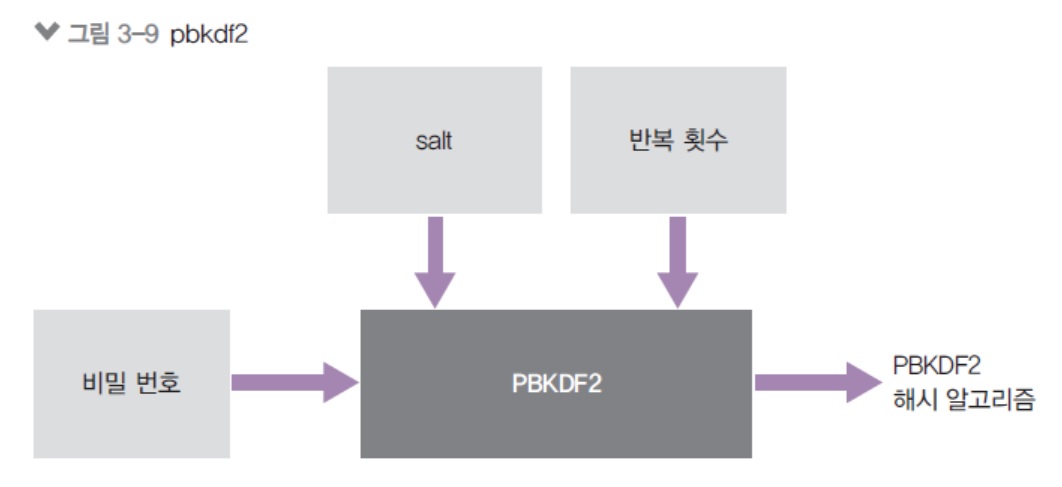
crypto.randomByptes로 64바이트 문자열 생성 -> salt 역할pbkdf2인수로 순서대로 비밀번호, salt, 반복 횟수, 출력 바이트, 알고리즘-
반복 횟수를 조정해 암호화하는데 1초 정도 걸리게 맞추는 것이 권장됨
// pbkdf2.js const crypto = require("crypto"); crypto.randomBytes(64, (err, buf) => { const salt = buf.toString("base64"); console.log("salt:", salt); crypto.pbkdf2("비밀번호", salt, 100000, 64, "sha512", (err, key) => { console.log("password:", key.toString("base64")); }) })
pbkdf2에는
salt(소금)이라는게 있는데, 위와 같이 비밀번호와salt를 같이 넣어서 돌리면 해시화가 됩니다.
pbkdf2를 할 때는salt와password(비밀번호)를 둘 다 DB에 저장을 해둬야됩니다.
salt가 달라지면password(비밀번호)도 달라지기 때문에.
salt는 해독을 더 어렵게 하기위해서 추가되는 거라고 보시면 되고pbkdf2쓰실 분들은 위 코드 참조하시면 되는데, 저는 보통 쓰진 않습니다.지금까지는 해시를 알아봤고 이제 반대로 해시 말고 암호화와 복호화를 알아보도록 하겠습니다.
3.9.5 양방향 암호화
암호화와 복호화, 원래 문장으로 되돌려야하는 경우도 있죠?
예를 들어 제가 어떤 사람에게 "바보"라는 문자를 암호화해서 보냈어요.
받은사람은 그 암호화된 문자를 풀어서 "바보"라는 문자를 확인해야겠죠?
그 방법 중 하나가 createCipheriv입니다.
-
대칭형 암호화(암호문 복호화 가능)
대칭형 암호화가 있으면 비대칭형 암호화도 있겠죠?
대칭형 암호화는 예를 들어, "바보"라는게 있고 그걸 암호화하기 위해서 "hyungju-lee"라는 키를 사용했어요. 그럼 상대방도 "hyungju-lee"라는 키를 사용해야지 암호문을 "바보"로 다시 되돌릴 수 있어요.
즉, 저랑 상대방이랑 같은 키를 사용해야됩니다.
어찌보면 당연한거죠?
그런데 이게 생각보다 취약합니다.
암호화 자체가 취약한 것은 아닌데, 둘이 같은 키를 갖고있어야되면, 해커들이 암호를 해독하려고 안하고 키를 훔치려고 하거든요?
그래서 그 키가 훔쳐질 가능성이 많습니다.
즉, 대칭형 암호화는 키 관리를 잘 하셔야됩니다.그리고 이거는 프론트랑 서버 관계에서는 사용할 수가 없는게 프론트에 쓰이는 코드들은 다 노출되거든요?
HTML, CSS, JAVASCRIPT 이런거 다 공개되어있습니다.
개발자 도구 들어가면 다 보이잖아요?
그런데 만약 서버에서 무언가를 암호화해서 보내줬는데 그걸 프론트에서 해독하려면, 서버의 키와 프론트의 키가 같아야되죠?
그런데 프론트에 키를 두면 그 키는 개발자 도구로 볼 수가 있습니다.
그러면 해커들이 옳다구나 하고 가져가겠죠. 그래서 프론트와 서버 관계에선, 특히 한쪽이 공개적일 때는 같은 키를 사용하는 이런 알고리즘을 사용하면 안되겠죠.
대칭형 암호화는 이때는 사용하면 안되는겁니다.- Key가 사용됨
-
암호화할 때와 복호화할 때 같은 Key를 사용해야 함
// cipher.js const crypto = require("crypto"); const algorithm = "aes-256-cbc"; const key = "abcdefghijklmnopqrstuvwxyz123456"; const iv = "1234567890123456"; const cipher = crypto.createCipheriv(algorithm, key, iv); let result = cipher.update("암호화할 문장", "utf8", "base64"); result += cipher.final("base64"); console.log("암호화:", result); const decipher = crypto.createDecipheriv(algorithm, key, iv); let result2 = decipher.update(result, "base64", "utf8"); result2 += decipher.final("utf8"); console.log("복호화:", result2);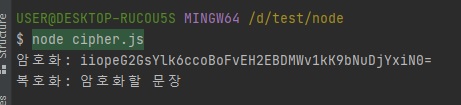
위의 코드가 노드 예전 버전에 비해 복잡해진건데 예전에는
createDecipher뒤에iv가 안 붙었거든요?
그런데 그냥createDecipher할 때 취약점이 발견돼서.. 초기화 백터 공격이란게 있습니다.
이 암호화 자체가 배경지식이 없으시면, 노드만 하셔서는 이해하실 수가 없는 분야라서 간단히 말씀드릴게요.
초기화 백터 공격이란게 발생해서 기존의createDecipher간단한 암호화가 사라지고createDecipheriv라는게 추가되었거든요.createDecipheriv는 제약이 많습니다.
key는 32바이트,iv는 16바이트 문자열을 써야돼고algorithm도 하나 고르셔야됩니다.그런데 위 코드 개념을 이해하시기는 너무 어려울겁니다.
이거는 암호학 수업을 안들으시면 왜 저렇게 처리를 해야되는지 이해하기 어렵습니다.그래서 저는 대칭형 암호화하실 때 위 코드를 쓰시기보다는 나중에 5강에서 설명하겠지만 "남이만든 암호화"라는게 있거든요?
crypto-js라고 남이 만들어둔 코드들이 있는데, 그걸로 암호화를 하시는 걸 추천드립니다.
그냥 기본 노드의crypto는 암호학 지식이 있어야만 원활하게 사용하실 수 있고, 물론 위의crypto-js도 그렇긴한데, 그나마crypto-js가 조금 더 쉽습니다.
그래서 제가 추천을 드리자면 단방향 암호화(해시)는
sha512, 256까지도 지금은 괜찮긴한데 그래도 512를 더 추천드리고 대칭형 암호화는 위에 AES있죠?
같은 키로 암호화했다가 복호화했다가 하는건 AES를 추천드립니다.
비대칭인 경우, 즉, 프론트와 서버랑 다른 키를 갖고있으면서 암호화했다가 복호화했다가 할 수 있는 비대칭 암호화가 있거든요?
https같은게 비대칭 암호화입니다.
비대칭 암호화인 경우는 RSA(?맞나이거?) 방식을 추천드립니다.
3.9.6 양방향 암호화 메소드
-
crypto.createCipheriv(알고리즘, 키, iv): 암호화 알고리즘과 키, 초기화 벡터를 넣어줍니다.- 암호화 알고리즘은
aes-256-cbc를 사용했습니다. 다른 알고리즘을 사용해도 됩니다. - 사용 가능한 알고리즘 목록은
crypto.getCiphers()를 하면 볼 수 있습니다. - 키는 32바이트, 초기화벡터(iv)는 16바이트로 고정입니다.
- 암호화 알고리즘은
-
cipher.update(문자열, 인코딩, 출력 인코딩): 암호화할 대상과 대상의 인코딩, 출력 결과물의 인코딩을 넣어줍니다.- 보통 문자열은 utf8 인코딩을, 암호는 base64를 많이 사용합니다.
cipher.final(출력 인코딩): 출력 결과물의 인코딩을 넣어주면 암호화가 완료됩니다.crypto.createDecipheriv(알고리즘, 키, iv): 복호화할 때 사용합니다. 암호화할 때 사용했던 알고리즘과 키, iv를 그대로 넣어주어야 합니다.-
decipher.update(문자열, 인코딩, 출력 인코딩): 암호화된 문장, 그 문장의 인코딩, 복호화할 인코딩을 넣어줍니다.- createCipher의 update()에서 utf8, base64 순으로 넣었다면 createDecipher의 update()에서는 base64, utf8 순으로 넣으면 됩니다.
decipher.final(출력 인코딩): 복호화 결과물의 인코딩을 넣어줍니다.
더 깊게 들어가면 노드 강좌가 아닙니다.
현업에서 이렇게 비밀번호나 salt 관리할 때는 git 같은데는 올리시면 안됩니다.
이게 정말 애매한데, 현업에서 키, 비밀번호 관리하는거는 모든 회사에서 좀 애를 먹고있거든요?
이게 AWS KMS라는게 있는데, 이런거 쓰는 경우도 많고..
비밀번호 관리하는 것도 전략이 다양해가지고 주기적으로 바꿔준다던가 자동화해주는 이런 서비스들이 있습니다.
작은 회사들은.. AWS 비밀번호가 있을 수도 있고 배포를 위한 비밀번호도 있을 수도 있고, 작은 회사들은 그런 것들을 카톡으로 공유하기도 하고 슬렉으로 공유하기도 하고 그렇게도 하는데, 항상 회사들은 리스크가 있어요.
어떤 리스크냐면, 개발자들도 직급이 나뉘잖아요?
좀 높은 직급인 사람들한테는 키 같은거 접근 권한을 주고 낮은 직급의 사람들한테는 안 주거나 권한이 낮은 키를 주거나, 그런식으로 하는데 높은 직급의 사람들이 가끔씩 이직을 하는 경우가 있어요.
그때 키를 들고 나가버릴 수가 있거든요?
그래서 그런 경우도 좀 다 고려를 하셔서 해야됩니다.
한 사람이 퇴사를 하면, 키를 들고 있는 사람이 퇴사를하면 그 키들을 전부 다 수정을 해야되는데, 만약에 키들이 너무 많다싶으면 힘들기 때문에 위와 같은 AWS KMS 같은 걸 사용하기도 합니다.
그런데 이 문제가 정답이 딱히 있다기 보다는 엄청 어렵습니다.
이 문제 자체가.
암호화는 솔직히 노드에서 다룰게 아닙니다.
나중에 제가 비밀번호 암호화하는 것 정도는 보여드리거든요?
실제 서비스 만들 때 필요한 암호화 정도만 제가 보여드리도록 하겠습니다.
대부분 다 암호화 알고리즘에서 뚫리는게 아니라 사람 실수에서 뚫립니다.
비밀번호를 쉬운걸 한다던지 실수로 console에다가 찍거나 로그에다 남기거나 그런거에서 다 뚫립니다.
3.9.7 util
-
각종 편의 기능을 모아둔 모듈
-
deprecated와promisify가 자주 쓰임.
callbackify도 있는데callbackify는 제가 쓰는걸 한번도 못봤습니다.
예를들어 여러분이 노드로 어떤 프로그램을 만들었고 그 프로그램을 남들이 쓰기를 원합니다.
그런데 어떤 코드를 만들었는데 그 코드를 잘못 만들었다는걸 깨닫게됩니다.
그럼 수정을 해야겠죠?
그런데 그렇다고 기존 코드를 지울 수 있느냐.
못 지웁니다.
왜냐하면 그 코드를 함부로 지워버리면 그 코드를 쓰고있었던 사람들의 프로그램들은 다 고장나버리기 때문입니다.앞서 모듈 시스템할 때 자바스크립트에서는 ES2015+ 모듈이 나왔는데, 노드는 CommonJS 모듈이라고
require,module,exports쓰는거, 그거를 계속 고수할 수밖에 없다고 했잖아요?
왜냐하면 CommonJS 모듈을 자바스크립트 모듈 시스템(import,export)으로 바꿔버리면, 그동안 CommonJS 사용했던 사람들의 프로그램들이 전부 다 망가져버리니깐.
그래서 한번 만든거는 잘못 만들었더라도 그대로 계속 유지되어야합니다. 웬만하면.그런데 잘못만들었다면 잘못만든건 알려주긴 해야되잖아요?
그럴 때util모듈의deprecated로 함수를 감싸줍니다.
그러면deprecated된 함수를 사용할 때마다 경고창이 뜹니다.
경고가 출력되기 때문에 이걸 본 사람들은 다른 함수로 넘어가겠죠.물론 다 수정하진 않을거에요.
그렇지만 충분히 다른 함수를 사용하게 하고, 나중에 버전을 올릴 때deprecated된 함수를 없애는 것.
버전 관련 내용은 5강에서 다룹니다.
여튼 그래서 기존 코드, 특히 남이 쓰고있는 코드는 함부로 지우시면 안돼고 먼저util.deprecate로 감싸서 경고를 띄워준 다음에 조금 시간이 지나서 사람들이 안 쓰는 거 같다고 하면 버전을 올리면서 삭제를 하셔야됩니다.여튼
deprecated- 라이브러리 만드실 때 많이 사용하실겁니다.promisify- 자바스크립트가 콜백에서 프로미스로 많이 넘어가고 있다고 제가 앞서 말씀드렸잖아요?
그런데 옛날 함수들은 콜백으로 많이 되어있거든요.
그리고 그런 옛날 함수들, 못없앤다고 했죠?
방금 말씀드렸죠. 콜백으로 되어있는거 없애면 지금까지 해당 콜백함수 사용했던 사람들의 프로그램이 다 고장난다고 했습니다.그래서 기존 코드를 유지하고 새로 프로미스 기반으로 함수를 만들던가 그러거든요?
그런데 노드에서는 아직 프로미스를 지원 안하는 애들이 많아요.
그냥 콜백으로 남아있는 애들이 많은데, 걔네들을 프로미스랑 같이 쓸 때, 콜백함수는 async/await 문법을 못 써서 엄청 불편하거든요.
그럴 때util.promisify()로 콜백함수를 감싸주면, 마법처럼.then()을 붙일 수 있게 됩니다.
즉,util.promisify()로 감싸주면 프로미스가 되는 겁니다.그럼 아래 코드에서
randomBytesPromise앞에await를 붙일 수 있겠죠?
.then()대신에await를 붙이면 되니깐.
그런식으로 콜백함수들을 프로미스로 바꿔주는데 한가지 조건이 있습니다.한가지 조건은 콜백이
(error, data) => {}형식이어야 합니다.
콜백 함수가 첫번째 매개변수가error이고 두번째 매개변수가data그런 형식이어야지만 콜백을 프로미스로 바꿀 수 있고, 만약에 이게 안 지켜진 콜백함수라면 못 바꿉니다.
그런데 노드에서는 다행히 콜백들이 다(error, data) => {}이렇게 되어있습니다.
그래서 대부분의 콜백을util.promisify()로 감싸면 프로미스로 바꿀 수 있습니다.그리고 반대로 프로미스를 콜백함수로 바꾸는
util.callbackify()도 있지만 이걸 사용하는 사람은 한번도 못봤습니다.// util.js const util = require("util"); const crypto = require("crypto"); const dontUseMe = util.deprecate((x, y) => { console.log(x + y); }, "dontUseMe 함수는 deprecated 되었으니 더 이상 사용하지 마세요!"); dontUseMe(1, 2); const randomBytesPromise = util.promisify(crypto.randomBytes); randomBytesPromise(64) .then((buf) => { console.log(buf.toString("base64")); }) .catch((error) => { console.error(error); })
-
3.9.8 util의 메소드
-
util.deprecate: 함수가 deprecated 처리되었음을 알려줍니다.- 첫번째 인자로 넣은 함수를 사용했을 때 경고 메시지가 출력됩니다.
- 두번째 인자로 경고 메시지 내용을 넣으면 됩니다.
함수가 조만간 사라지거나 변경될 때 알려줄 수 있어 유용합니다.
-
util.promisify: 콜백 패턴을 프로미스 패턴으로 바꿔줍니다.-
바꿀 함수를 인자로 제공하면 됩니다.
이렇게 바꿔두면 async/await 패턴까지 사용할 수 있어 좋습니다.
단, 콜백이(error, data) => {}형식이어야 합니다. -
3.5.5.1 절의 randomBytes와 비교해보세요.
프로미스를 콜백으로 바꾸는util.callbackify도 있지만 자주 사용되지는 않습니다.
-
deprecated란?
deprecated는 프로그래밍 용어로, “중요도가 떨어져 더 이상 사용되지 않고 앞으로는 사라지게 될” 것이라는 뜻입니다.
새로운 기능이 나와서 기존 기능보다 더 좋을 때, 기존 기능을 deprecated 처리하곤 합니다.
이전 사용자를 위해 기능을 제거하지는 않지만 곧 없앨 예정이므로 더 이상 사용하지 말라는 의미입니다.
3.10 worker_threads
-
노드에서 멀티 스레드 방식으로 작업할 수 있음
worker_threads모듈은 노드에서 멀티 스레드 방식으로 작업할 수 있게 지원해주는 모듈
제가 누누히 말씀드리지만 노드에서 멀티 스레드를 사용하는 방식은 극히 드뭅니다.
CPU를 많이 써야하는 암호화, 압축 이런 작업을 직접 구현하실 때, 그럴 때나 쓰셔야되고 대부분의 경우는 싱글스레드라고 생각하시면 됩니다.
노드에서 멀티 스레드 기능이 원래 안됐던 거를 할 수는 있게 지원을 해주는거지 이게 메인이 되어서는 안됩니다.worker_threads사용하는거는 상당히 복잡하거든요?
이전에도 말씀드렸지만 멀티 스레드로 프로그래밍하는게 쉬운 일이 아닙니다.isMainThread: 현재 코드가 메인 스레드에서 실행되는지, 워커 스레드에서 실행되는지 구분- 메인 스레드에서는
new Worker를 통해 현재 파일(__filename)을 워커 스레드에서 실행시킴 worker.postMessage로 부모에서 워커로 데이터를 보냄-
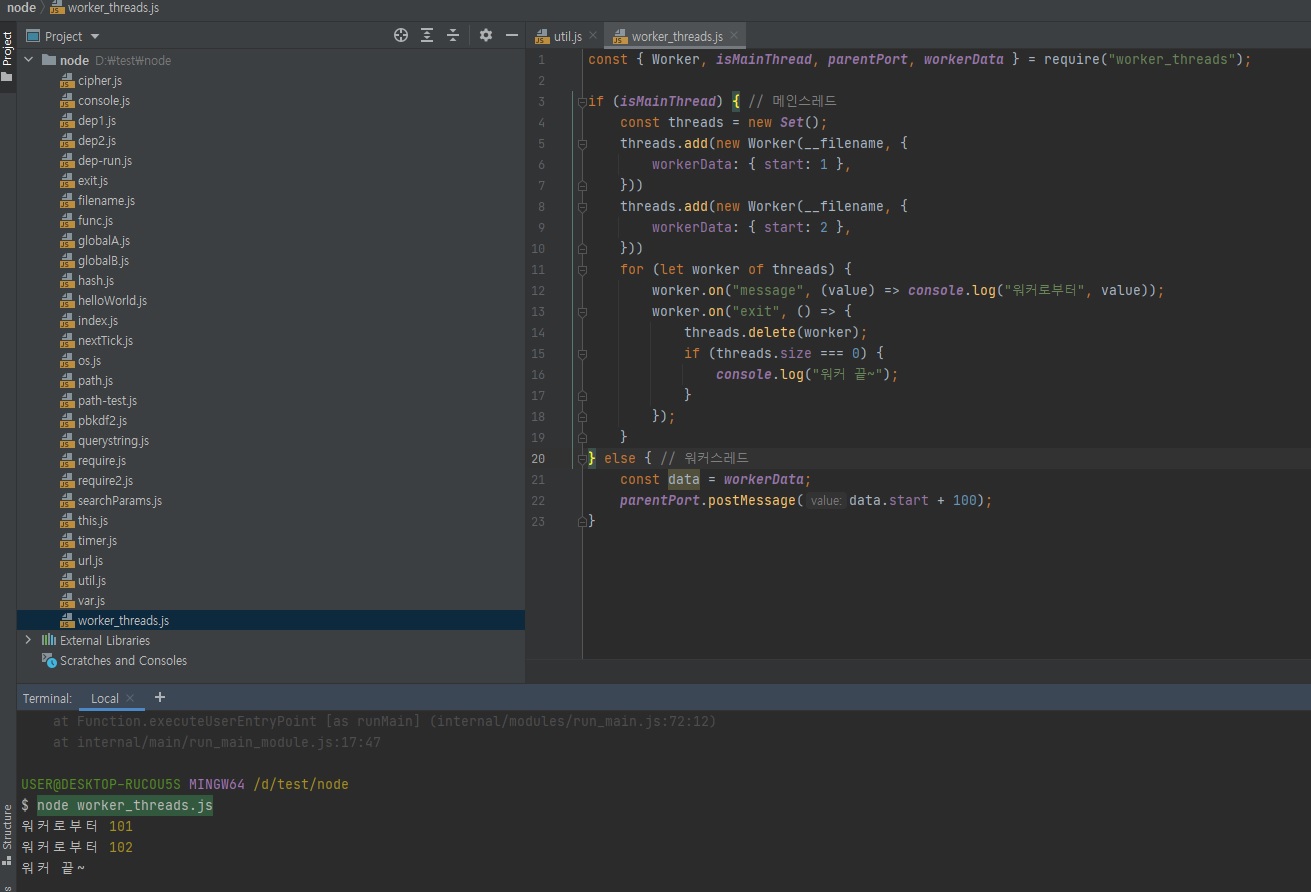
parentPort.on("message")로 부모로부터 데이터를 받고,postMessage로 데이터를 보냄// worker_threads.js // 원리는 부모에서 일을 분배를 해서 워커로 보내주고 워커는 그걸로부터 계산을 해서 부모로 다시 보내고 종료하고 const { Worker, isMainThread, parentPort, } = require("worker_threads"); if (isMainThread) { // 부모일 때(메인 스레드일 때) const worker = new Worker(__filename); // 이렇게 한다는 것은 다른 파일도 할 수 있다는 거겠죠? // 아래 else 부분을 메인 스레드와 같이 쓰고싶지 않다면 다른 파일에 작성해서 다른 파일 경로를.. path.join()으로 수정을 해주면 되겠죠. // 그리고 그 경로에 워커스레드용 파일을 만들어주시고. // 그런데 굳이 그렇게까지 할 필요는 없고 이렇게 한 파일에서 작성하면 알아서 isMainThread에 따라서 if - else로 알아서 분기처리가 되기 때문에 이렇게만 하셔도 되긴 합니다. // 현재는 new Worker()로 워커 스레드를 한개를 생성한 것입니다. worker.on("message", message => console.log("from worker", message)); // worker에 message 이벤트 핸들러를 달아줍니다. worker.on("exit", () => console.log("worker exit")); // worder에 exit(종료) 이벤트 핸들러를 달아줍니다. worker.postMessage("ping"); // 워커스레드한테 ping을 보낼 수 있습니다. } else { // 워커일 때(워커스레드일 때) // parentPort를 통해 부모로부터 메시지를 받아올 수 있습니다. // 위에서 워커스레드한테 ping이란 메시지를 보냈는데 이 ping이란 메시지가 아래 value로 들어옵니다. parentPort.on("message", (value) => { console.log("from parent", value); parentPort.postMessage("pong"); parentPort.close(); // 워커스레드가 할 일을 다 했으면 close 메소드로 종료합니다. }) }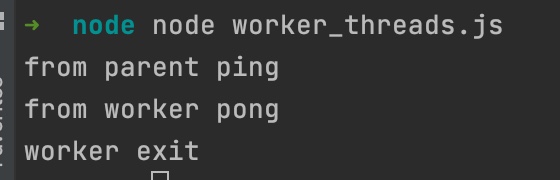
위 코드처럼 노드 14버전부터
worker_threads모듈을 불러올 수 있고, 위 코드 보시면 해당 모듈 안에isMainThread가 있어서isMainThread이걸로 분기처리를 해주셔야됩니다.
같은 파일을 메인스레드이냐 워커스레드이냐에 따라 다르게 처리를 하거든요?
위 코드에서 메인스레드는 if 문의 윗 블록{}에서 처리를 하고 워커스레드는 else 쪽의 블록{}에서 처리를 하는거죠.이게 처음에는 메인 스레드가 실행돼서 메인 스레드 안에서 워커 스레드들을 생성하고 워커스레드들에게 일을 분배를 해줍니다.
분배를 해준다음에 워커스레드들이 일을 마치면 그걸 다시 메인 스레드로 보내서 메인 스레드에서 워커 스레드들의 일을 합쳐서 최종적인 결과물로 리턴하는 그런 방식을 갖고 있습니다.
즉, 처음부터 워커 스레드가 일을 알아서 나눠갖는 것이 아니라 메인스레드에서 일을 직접 분배..
분배하는 것도 저희 개발자들이 직접 프로그래밍해서 분배를 해줘야돼고 나중에 합쳐서 결과물 리턴하는 것도 개발자가 다 코딩을 해야됩니다.
다만 워커 스레드에서는 동시에 분배했던 코드들이 돌아간다. 그 이점이 있는 겁니다.
위 코드의 설명을 집중해서 읽어보십시오.worker.postMessage("ping");: 위 코드 부모(메인)스레드에서ping을 워커스레드로 보내고console.log("from parent", value);: 워커스레드에서 그걸 받아서 처리한 다음에parentPort.postMessage("pong");: 워커스레드에서pong을 부모(메인)스레드로 보내고worker.on("message", 함수): 부모(메인)스레드로pong을 보내면 message 이벤트가 발생하면서 함수를 처리하고parentPort.close();: 워커스레드를 종료하면worker.on("exit", 함수)exit 이벤트가 발생하면서 함수 처리
위의 예제가 가장 간단한 예제이고 얘를 조금 더 복잡하게 만들려면 여러개의 워커를 사용해봐야겠죠?
위의 예제에선 워커를 1개밖에 안 만들었는데 실제 사용할 땐 여러개를 만들어야 실제 멀티 스레드의 효과를 볼 수 있잖아요?
물론 위의 코드도 메인스레드, 워커스레드 - 멀티스레드이긴합니다.
그런데 저희가 원하는건 진짜 일을 나눠서 처리하는 것을 보고싶은 거니깐, 워커를 여러개 생성해서 처리하는 것, 그거를 보여드리도록 하겠습니다.
3.10.1 여러 워커스레드 사용하기
-
new Worker호출하는 수만큼 워커 스레드가 생성됨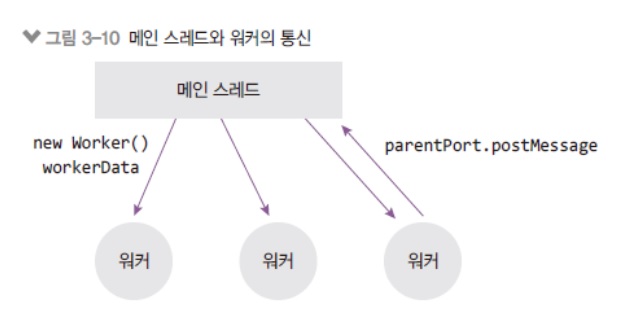
// worker_data.js const {Worker, isMainThread, parentPort, workerData} = require("worker_threads"); if (isMainThread) { // 부모(메인)스레드일 때 const threads = new Set(); threads.add(new Worker(__filename, { workerData: {start: 1}, })) threads.add(new Worker(__filename, { workerData: {start: 2}, })) for (let worker of threads) { worker.on("message", message => console.log("from worker", message)); worker.on("exit", () => { threads.delete(worker); if (threads.size === 0) { console.log("job done"); } }) } } else { // 워커스레드일 때 const data = workerData; parentPort.postMessage(data.start + 100); }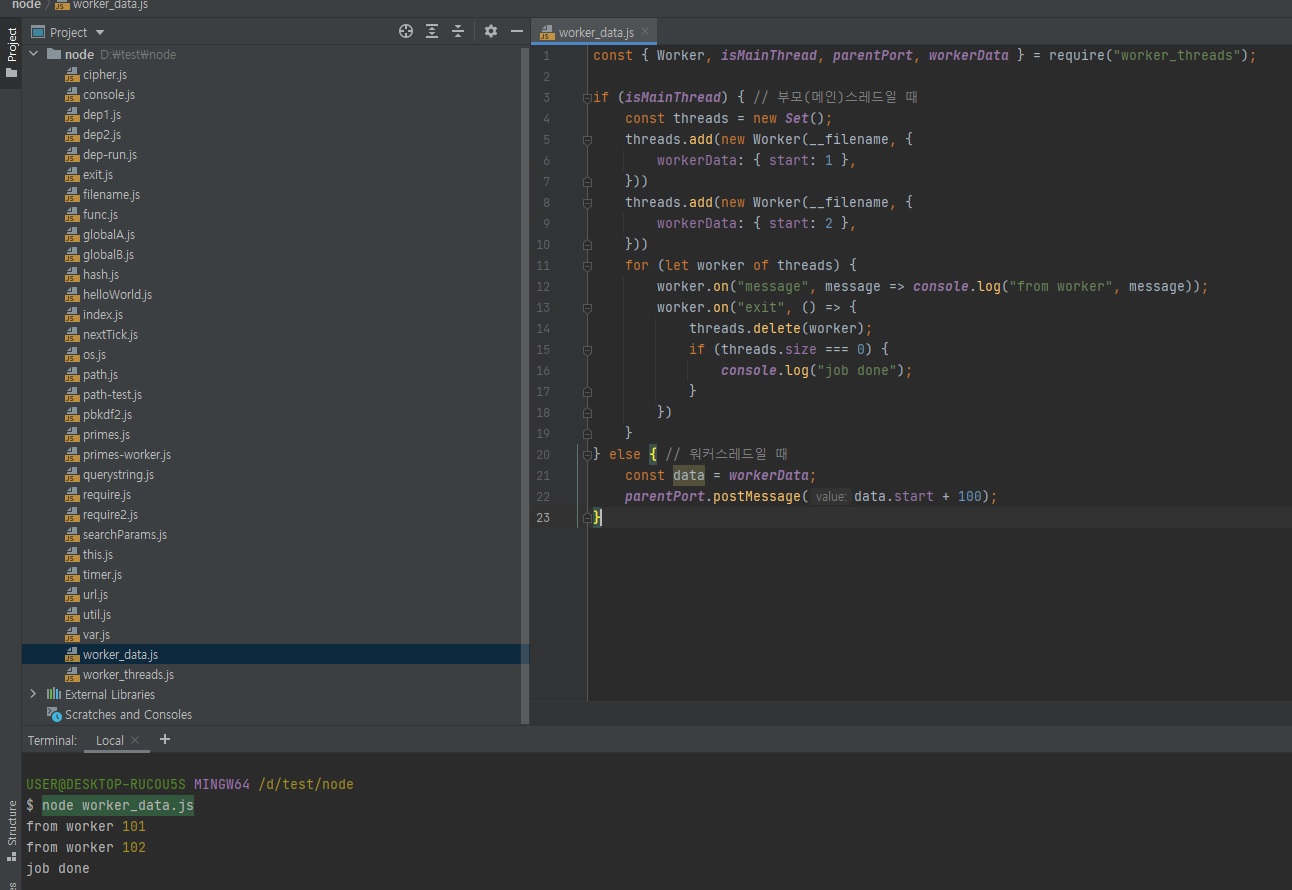
3.10.2 소수 찾기 예제
-
워커 스레드를 사용하지 않을 때 (싱글 스레드일 때)
// prime.js const min = 2; const max = 10000000; const primes = []; function generatePrimes(start, range) { let isPrime = true; const end = start + range; for (let i = start; i < end; i++) { for (let j = min; Math.sqrt(end); j++) { if (i !== j && i % j === 0) { isPrime = false; break; } } if (isPrime) { primes.push(i); } isPrime = true; } } console.time("prime"); generatePrimes(min, max); console.timeEnd("prime"); console.log(primes.length); -
워커스레드를 사용할 때
const {Worker, isMainThread, parentPort, workerData} = require("worker_threads"); const min = 2; let primes = []; function findPrimes(start, range) { let isPrime = true; let end = start + range; for (let i = start; i < end; i++) { for (let j = min; j < Math.sqrt(end); j++) { if (i !== j && i % j === 0) { isPrime = false; break; } } if (isPrime) { primes.push(i); } isPrime = true; } } if (isMainThread) { const max = 10000000; const threadCount = 8; const threads = new Set(); const range = Math.ceil((max - min) / threadCount); let start = min; console.time("prime"); for (let i = 0; i < threadCount - 1; i++) { const wStart = start; threads.add(new Worker(__filename, {workerData: {start: wStart, range}})); start += range; } threads.add(new Worker(__filename, {workerData: {start, range: range + ((max - min) + 1) % threadCount}})); for (let worker of threads) { worker.on("error", (err) => { throw err; }) worker.on("exit", () => { threads.delete(worker); if (threads.size === 0) { console.timeEnd("prime"); console.log(primes.length); } }) worker.on("message", (msg) => { primes = primes.concat(msg); }) } } else { findPrimes(workerData.start, workerData.range); parentPort.postMessage(primes); }
const { Worker, isMainThread, parentPort } = require("worker_threads");
if (isMainThread) { // 메인스레드
const worker = new Worker(__filename);
const worker1 = new Worker(__filename);
const worker2 = new Worker(__filename);
const worker3 = new Worker(__filename);
worker.on("message", (value) => console.log("워커로부터", value));
worker.on("exit", () => console.log("워커 끝~"));
worker.postMessage("ping");
} else { // 워커스레드
parentPort.on("message", (value) => {
console.log("부모로부터", value);
parentPort.postMessage("pong");
parentPort.close();
})
}
사실 만드는거는 위와 같이 new 연산자로 Worker 객체를 여러개 생성하면 여러개의 스레드가 만들어지거든요?
그런데 보통 위와 같이 하면 관리하기가 어려우니까 아래와 같이 const threads = new Set();을 사용하도록 하겠습니다.
Set은 배열인데 중복되지 않는 배열입니다.
const { Worker, isMainThread, parentPort, workerData } = require("worker_threads");
if (isMainThread) { // 메인스레드
const threads = new Set();
// 아래처럼 초기 데이터를 넣어줄 수 있습니다.
// worker.postMessage하지말고 어차피 초기 데이터가 있다면 초기 데이터를 아래처럼 넣어주세요.
// 그리고 저희가 원하는만큼 worker들을 늘려주면됩니다. 일단 아래처럼 2개만 만들어보겠습니다.
threads.add(new Worker(__filename, {
workerData: { start: 1 },
}))
threads.add(new Worker(__filename, {
workerData: { start: 2 },
}))
// Set인 threads를 아래처럼 반복시킵니다.
for (let worker of threads) {
// 이벤트 리스너를 아래와 같이 연결
worker.on("message", (value) => console.log("워커로부터", value));
worker.on("exit", () => {
// 워커가 끝났을 때는 스레드에서 삭제를 해줍니다.
// 끝난 스레드는 threads Set에서 제거를하고 나중에 새로 생성하면 다시 추가하고
threads.delete(worker);
// 모든 워커들이 종료되었으면 여기서 일이 마무리되었다는 걸 알 수 있음
// 워커들이 다 끝나서 사라졌는지 아닌지도 저희가 스스로 판단해줘야함, 워커스레드에서 이런걸 직접 해주고 그런게 없기 때문에 저희가 직접 해야된다는 것
// 노드 14버전부턴 멀티 스레드의 가능성을 열어준거지 저희가 거의 다 수동으로 작성을 해줘야되기 때문에
// 그리고 일을 나누는 것이 얼마나 복잡한지는 이 다음 예제에서 보시게 될겁니다.
if (threads.size === 0) {
console.log("워커 끝~");
}
});
}
} else { // 워커스레드
// 위에서 설정한 workerData: { ... } 초기 데이터는 아래와 같이 받아올 수 있다.
const data = workerData;
// { ... } 객체를 초기데이터로 설정했기 때문에 객체를 받아옴
// 아래와 같이 설정하면 1, 2를 워커 초기데이터로 보냈으므로, 워커스레드이므로 "동시"에 101, 102 만들어서 위의 메인 스레드로 보내주겠죠.
parentPort.postMessage(data.start + 100);
}
즉 if (threads.size === 0) { ... } 이 부분에서 나중에 101, 102를 받아서 더한다던가 그런식으로 처리를 해줄 수 있겠죠?
여기서 대표적인 예제가 "소수 찾는 예제"가 있거든요?
이 예제를 보시고나면 worker_threads 사용하는 게 쉬운게 아니구나 라고 느껴지실 겁니다.
2 ~ 천만 숫자에서 소수를 찾는 것을 보여드리겠습니다.
우선 멀티 스레드를 사용 안하는 방법입니다.
// prime.js
const min = 2;
const max = 10_000_000; // 최신 문법에선 자릿수 확인을 편하게하기위해 왼쪽과 같은 언더바 기능을 지원합니다.
const primes = [];
// 에라토스테네스의 체 알고리즘으로 소수 찾기
function generatePrimes(start, range) {
let isPrime = true;
const end = start + range;
for (let i = start; i < end; i++) {
for (let j = min; j < Math.sqrt(end); j++) {
if (i !== j && i % j === 0) {
isPrime = false;
break;
}
}
if (isPrime) {
primes.push(i);
}
isPrime = true;
}
}
console.time("prime");
generatePrimes(min, max);
console.timeEnd("prime");
console.log(primes.length);
위의 연산은 보기만해도 되게 헤비한 연산처럼 보입니다.
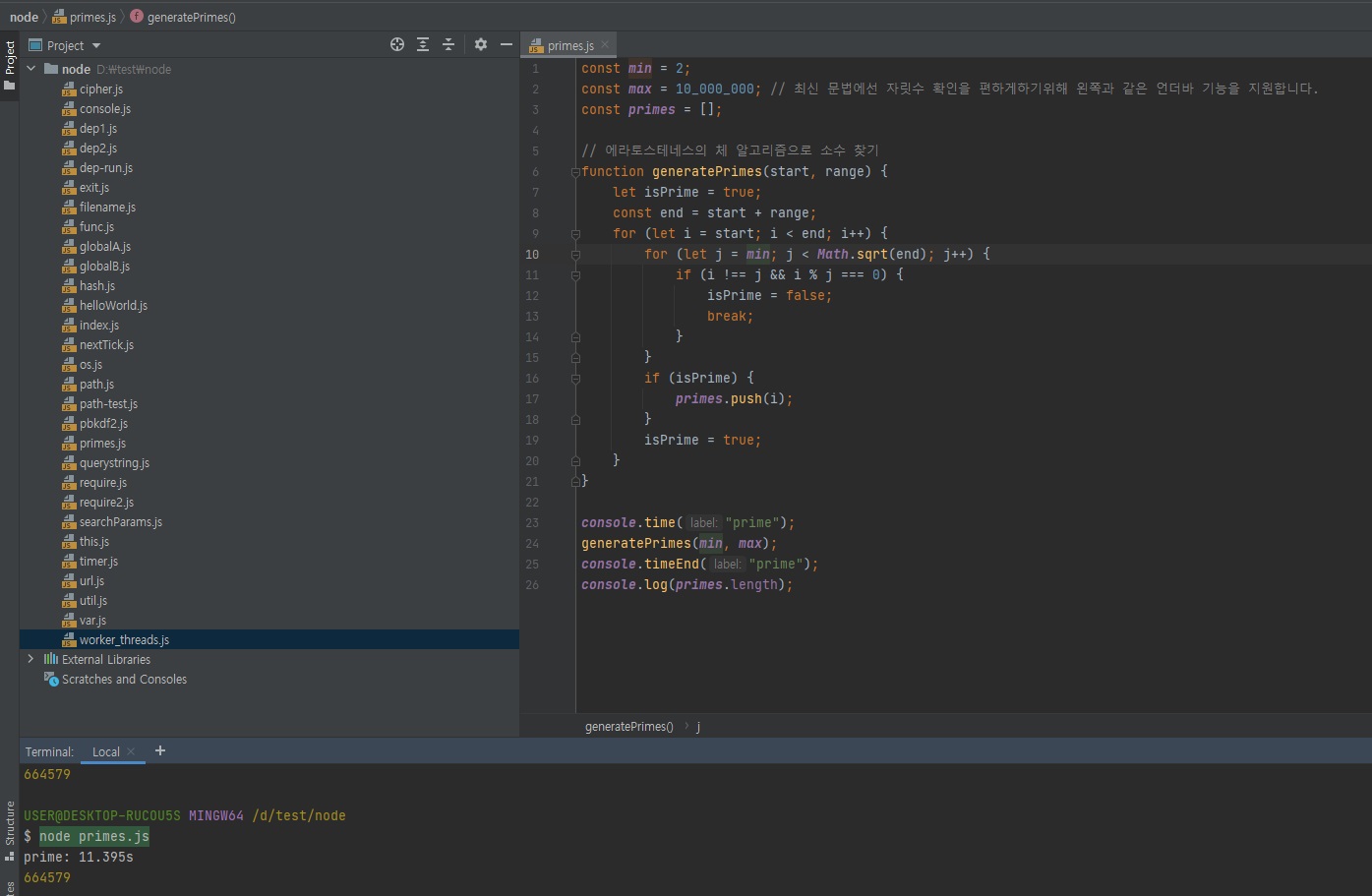
위에 함수가 걸린 시간을 체크해보면 11.395초가 걸린 것을 확인하실 수 있습니다.
이 코드가 있는 프로그래밍이 싱글 스레드로 짜여져있다면 해당 프로그램은 11초동안 멈춰있는 상태가 된다는 뜻입니다.
예를 들어 소수를 찾아주는 웹 사이트가 있을 때, 이렇게 11초 동안 소수를 찾는 코드가 스레드 하나를 잡아먹으면, 다른 작업들은 11초를 기다려야됩니다.
작업이 100개가 있다고 했을 때 100번째 작업은 1100초를 기다려야됩니다.
사실상 이렇게되면 서비스가 불가능합니다.
위 작업을 멀티스레드로 구성하면 얼마나 효율적이게 되는지 보여드리겠습니다.
다만, 멀티스레드 코딩이기 때문에 상당히 복잡합니다.
// prime-worker.js
const { Worker, isMainThread, parentPort, workerData } = require("worker_threads");
const min = 2;
let primes = [];
// 에라토스테네스의 체 알고리즘으로 소수 찾기
function findPrimes(start, range) {
let isPrime = true;
const end = start + range;
for (let i = start; i < end; i++) {
for (let j = min; j < Math.sqrt(end); j++) {
if (i !== j && i % j === 0) {
isPrime = false;
break;
}
}
if (isPrime) {
primes.push(i);
}
isPrime = true;
}
}
// 아래와 같이 워커 스레드들에게 일을 분배하는 것을 직접 짜셔야됩니다.
// 아래 코드에서 워커를 8개 만들었으므로 2 ~ 10000000 숫자를 알아서 서로 나눠가져가는 것이 아니라
// 첫번재 워커는 2 ~ 1250000, 두번째 워커는 1250000 ~ 2500000 ... 이렇게 8개한테 저희가 일을 각각 분배를 해주고
if (isMainThread) {
const max = 10_000_000;
// 8개의 스레드로 돌려보도록 하겠습니다.
const threadCount = 8;
const threads = new Set();
// 2 ~ 10000000 까지 8개의 구간으로 나눕니다.
const range = Math.ceil((max - min) / threadCount);
let start = min;
console.time("prime");
for (let i = 0; i < threadCount - 1; i++) { // 7개로 만든 이유는 8번째 워커스레드는 모양이 조금 독특해서입니다.
const wStart = start;
threads.add(new Worker(__filename, { workerData: { start: wStart, range } })); // 워커스레드마다 시작(wStart)과 끝(range - 범위)이 들어갑니다.
start += range;
}
// 8번째 워커 스레드
threads.add(new Worker(__filename, {
workerData: {
start,
range: range + ((max - min + 1) % threadCount)
}
}))
for (let worker of threads) {
worker.on("error", (err) => { // 실무에선 워커스레드 오류가 나는 경우를 대비해.. 복구로직까지 작성해주면 좋습니다.
// 워커에서 에러났을 경우 어떻게 대처할지를 적어줍니다.
// 여기까지 적어주려면 훨씬 더 복잡해지긴 하겠죠?
throw err;
})
worker.on("exit", () => {
threads.delete(worker);
if (threads.size === 0) {
console.timeEnd("prime");
console.log(primes.length);
}
})
worker.on("message", (msg) => { // msg엔 워커스레드에서 보낸 소수들(primes)이 담기겠죠?
primes = primes.concat(msg); // 8개의 워커스레드에서 구한 결과를 합쳐줍니다. 그런데.. 이렇게하면 중복 체크는 안돼지않나..?
})
}
} else { // 위에서 8개의 워커스레드로 일을 분배를 했으면
findPrimes(workerData.start, workerData.range);
// 위 함수에서 나온 결괏값이 primes 배열에 담기므로 이 걸 부모(메인) 스레드로 다시 보냄
parentPort.postMessage(primes);
}
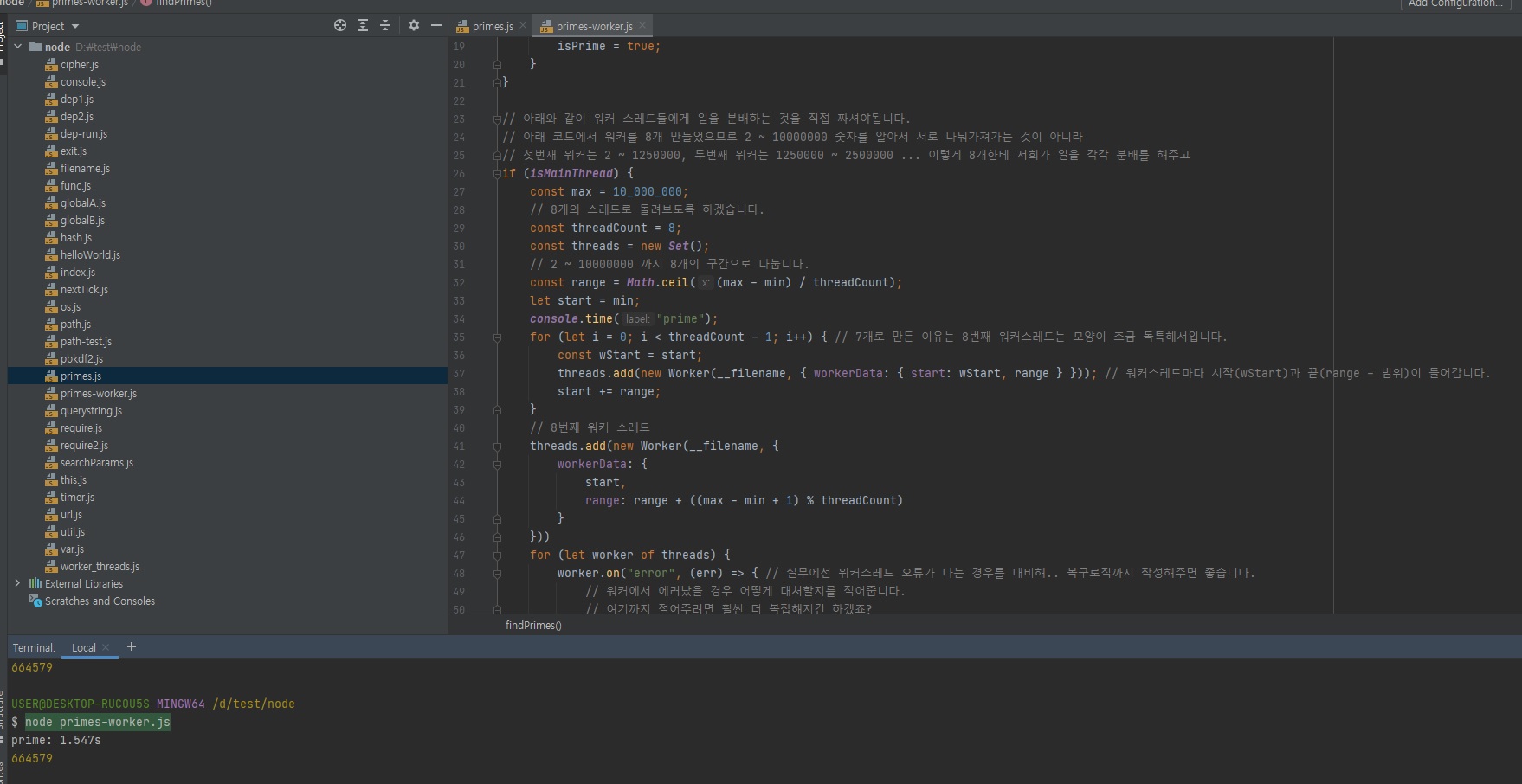
아까 11초 걸렸는데 위에 보시면 지금은 1.5초 걸리죠?
7.3배 정도 빨라졌습니다.
시간 초 테스트를 하실 땐 여러번해서 평균을 내시는 것이 좋습니다.
그런데 여기서 의문이 워커 스레드를 8개를 생성했는데, 왜 시간이 1/8로 줄어든게 아니라 1/7로 줄어들었어요?라고 생각하실 수도 있습니다.
이게 워커스레드를 많이 늘린다고해서 시간이 정비례해서 줄어들진 않습니다.
컴퓨터가 워커스레드를 만드는데도 시간이걸리고 워커스레드에서 메인스레드로 데이터를 보내는데도 시간이 걸리고 제 PC가 코어가 6개인데 워커스레드가 8개면, 실제로 동시에 돌아가는 것은 6개이고 그리고 남는거 2개는 6개가 끝난 다음에 2개가 들어가거든요?
즉, 여러분들 PC의 코어 갯수에 따라서도 다릅니다.
그렇기 때문에 몇개의 스레드가 빠른지는 위 코드의 threadCount를 한번 수정을 해보시면서 찾아보시는게 좋습니다.
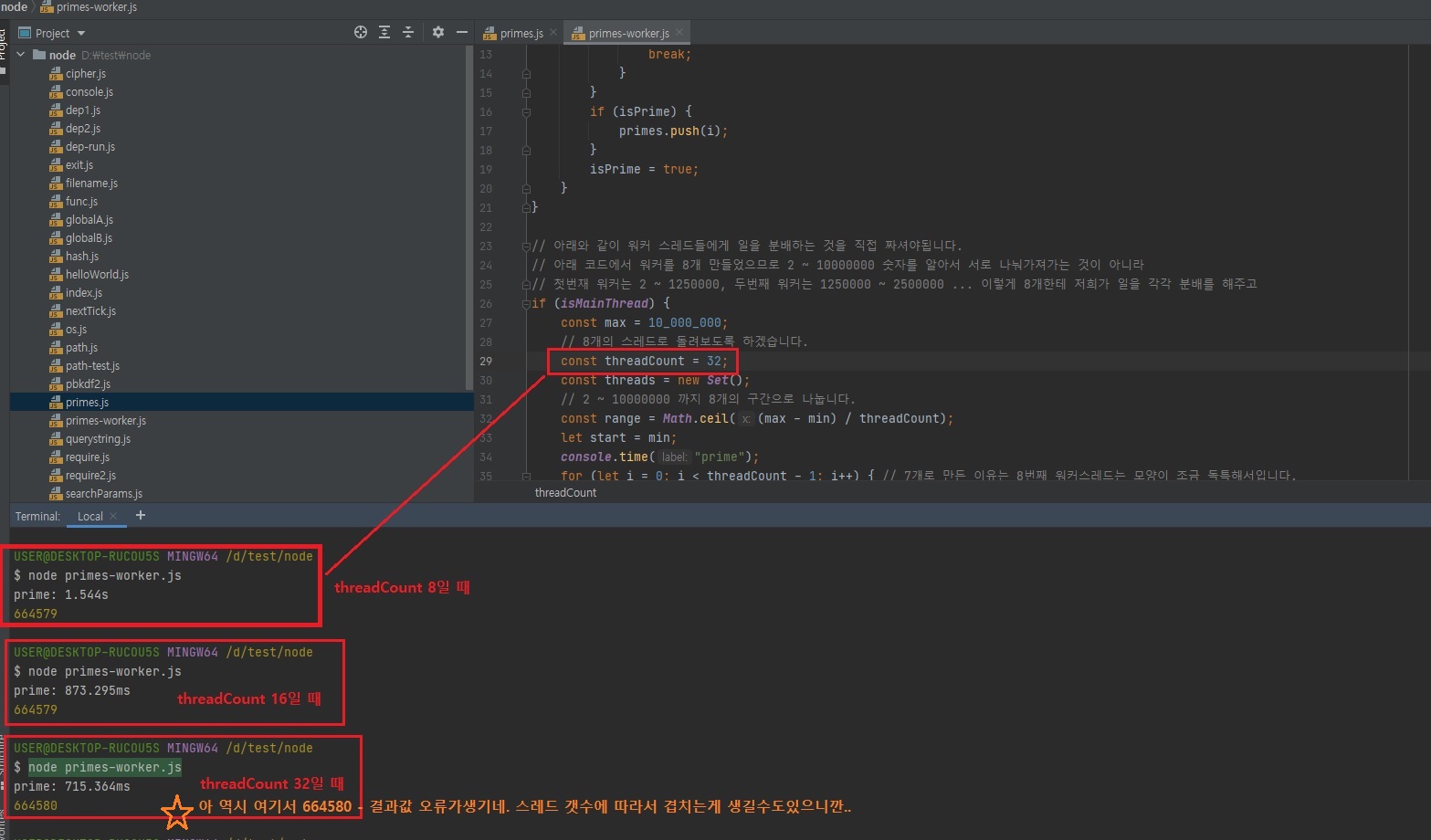
즉, 여러 테스트를 통해 적절한 스레드 갯수를 구하셔야됩니다.
이는 여러분들의 PC의 코어 갯수, 사양에 따라서 다릅니다.
그래서 PC마다 이를 찾는 것도 중요합니다.
그런데 확실히 멀티 스레드를 쓰는 것이 좋긴 하겠죠?
멀티 스레드를 지원하는 코어가 여러개있는 컴퓨터라면 11초보단 1.5초가 훨씬 나으니깐.
다만, 스레드에게 일 분배하고 그 분배한 일의 결과물들을 회수해서 결과를 도출하고 하는 것이 어렵다는 거.
위의 소수찾기 예제가 그나마 간단한 예제라고 보시면 됩니다.
솔직히 제 개인적인 의견은 멀티 스레드를 잘 쓰시면 좋긴한데 노드로는 멀티스레드를 굳이 안하시는게 좋고 다른 언어로 하시는게 좋을거 같습니다.
그럼 다른 언어로는 어떻게 하느냐.
나는 노드를 쓰는데 다른 언어를 배워야되느냐.
노드를 포기하고 다른 언어로 서버를 만들어야되는거냐.
하실 수도 있는데 다른 언어를 호출할 수가 있거든요?
이번에 보여드릴 child_process.
3.11 child_process
-
노드에서 다른 프로그램을 실행하고 싶거나 명령어를 수행하고 싶을 때 사용
- 현재 노드 프로세스 외에 새로운 프로세스를 띄워서 명령을 수행함
-
명령 프롬프트의 명령어인
dir을 노드를 통해 실행(리눅스라면ls를 대신 적을 것)// exec.js const exec = require("child_process").exec; var process = exec("dir"); process.stdout.on("data", function (data) { console.log(data.toString()); }) // 실행 결과 process.stderr.on("data", function (data) { console.error(data.toString()); }) // 실행 에러
-
파이썬 프로그램 실행하기
-
파이썬 3이 설치되어 있어야 함
// spawn.js const spawn = require("child_process").spawn; var process = spawn("python", ["text.py"]); process.stdout.on("data", function (data) { console.log(data.toString()); }) // 실행 결과 process.stderr.on("data", function (data) { console.log(data.toString()); }) // 실행 에러// text.py print("hello python")
-
const exec = require("child_process").exec;
위와 같이 쓰셔도 돼고
const { exec } = require("child_process");
위와 같이 쓰셔도 됩니다.
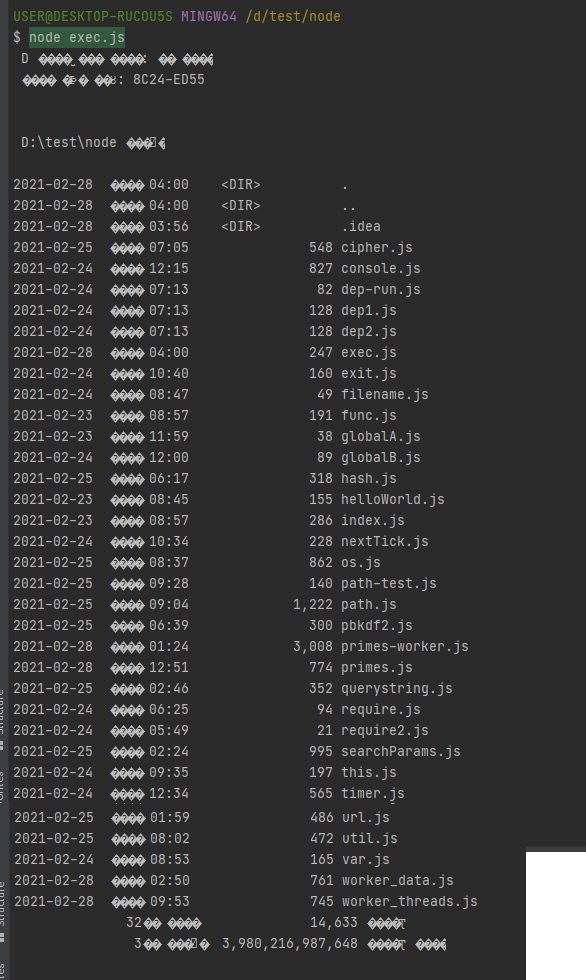
위와 같이 dir 명령어를 실행하면 현재 폴더의 파일 목록들을 보여줍니다.
이거를 노드에서도 명령어를 실행할 수 있게 만들어줍니다.
대신에 이 코드를 작성할 땐 결과물을 저희가 직접 받아줘야합니다.
// exec.js
const exec = require("child_process").exec;
// dir 명령어 실행
// 명령어를 실행하면 실행한 명령어에 대한 결과물이 있겠죠? 위 스크린샷처럼
var process = exec("dir");
// 해당 결과물을 저희가 아래처럼 직접 받아줄 수 있습니다.
// process.stdout(콘솔이라고 생각하면됨)에 data 이벤트가 발생하면 콜백함수를 실행하도록 했습니다.
process.stdout.on("data", function (data) {
// toString은 반드시해줘야합니다.
// 안그러면 0, 1로 이루어진 컴퓨터 데이터있죠? 그런식으로 나오기 때문에 toString까지 해주셔야지 콘솔에 기록을 할 수 있습니다.
console.log(data.toString());
})
// 에러날 경우도 대비해줍니다.
process.stderr.on("data", function (data) {
console.error(data.toString());
})
child_process는 노드 프로세스말고 다른 프로세스를 하나 띄웁니다.
즉, 다른 프로그램을 하나 더 실행하는 것과 비슷합니다.
.exec을 하면 터미널과 같은 효과입니다.
.exec을 통해 터미널을 실행하고 var process = exec("dir"); 이렇게 dir 명령어를 실행하는 겁니다.
저희가 직접 터미널에 dir 명령어를 입력할 수도 있지만, 노드 자바스크립트 코드 안에서도 프로그램 하나 띄워서 dir 명령어 치고 그 명령어로인해 나오는 데이터를 처리할 수 있게, 그리고 에러가난 경우에는 그것도 콘솔로 출력할 수 있게 위와 같은 식으로도 할 수 있습니다.
제가 위와 같은 것을 알려드린 이유가 있습니다.
앞서 멀티 스레드를 할거면 다른 언어로 하는게 좋다고 말씀드렸잖아요?
그 부분만 다른 언어로 짜놓고.. 예를 들어, 아래와 같이 파이썬을 노드로 실행할 수가 있습니다.
새로운 프로세스를 띄워서 파이썬을 실행을 하는 겁니다.
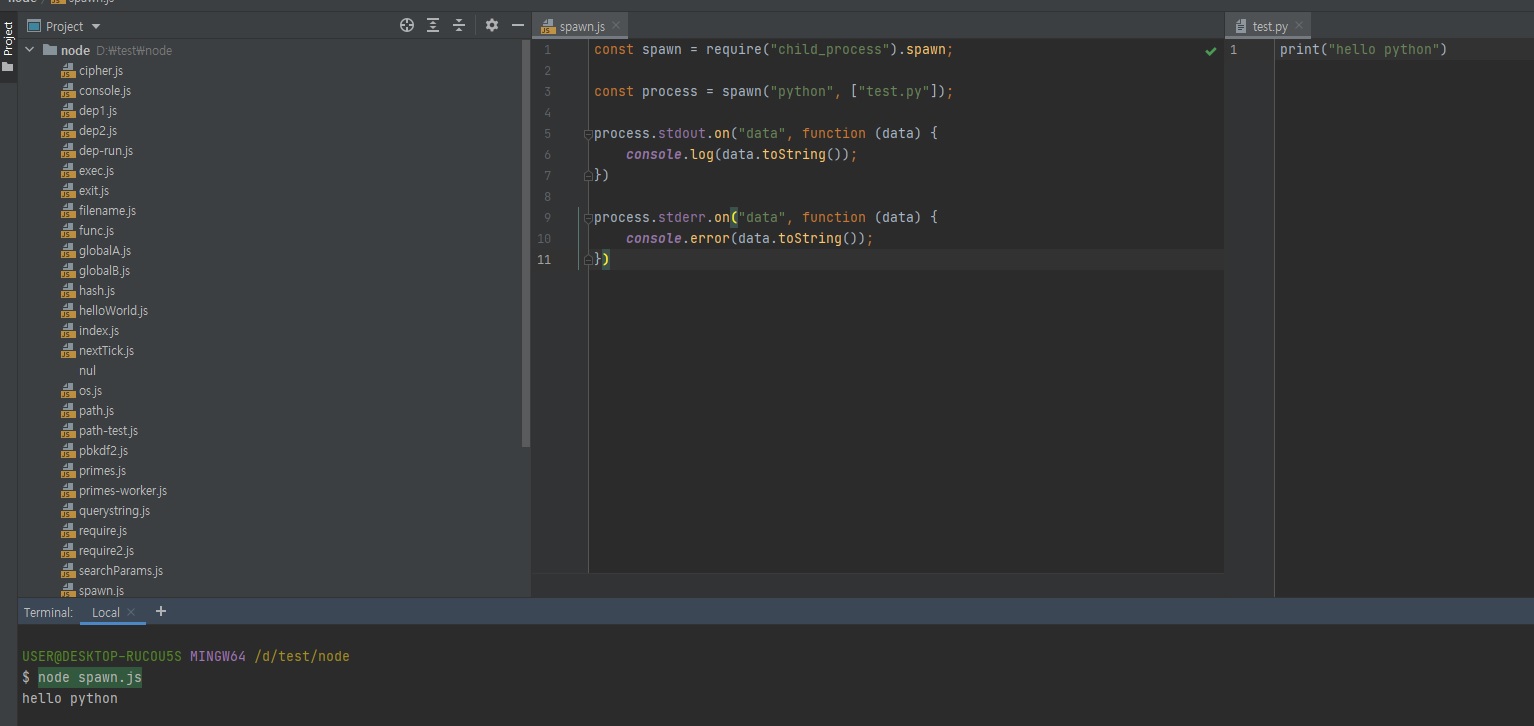
// spawn.js
const spawn = require("child_process").spawn;
const process = spawn("python", ["test.py"]);
process.stdout.on("data", function (data) {
console.log(data.toString());
})
process.stderr.on("data", function (data) {
console.error(data.toString());
})
// test.py
print("hello python")
파이썬이나 C++로 멀티 스레드를 하는 것이 좀 더 편리합니다.
그렇게 했다면 child_process의 spawn을 활용해서 노드에서 호출을 할 수 있습니다.
단, 파이썬이 설치가 되어있어야겠죠?
마찬가지로 C++을 실행하시려면 C++이 설치되어있어야 됩니다.
노드가 파이썬과 C++을 대신 실행을 해주는 것이 아니라 파이썬과 C++에게 이것좀 대신 실행해줘 라고 말을 하는 것이기 때문에 파이썬과 C++이 설치가 되어있어야합니다.
노드는 파이썬이나 C++ 자체를 실행할 수는 없고 실행을 해달라고 요청만 할 수 있는겁니다.
이와 같이 멀티 스레드는 child_process를 통해 하는 것이 더 나으실 겁니다.
노드 자체로 멀티 스레드를 하는 것이 그렇게 효율이 좋아고는 말씀드리진 못할 것 같습니다.
하지만 할 수는 있게 되었다는 점, 그것만 알아두시면 될 것 같습니다.
3.11.1 기타 모듈들
이렇게 내장 모듈들을 알아봤는데, 아래와 같은 모듈들도 있습니다.
아래 모듈들은 그렇게 많이 사용되는 모듈들은 아니라서 강좌에서는 뺐고, 혹시나 아래 모듈들이 필요하시다면 공식문서 들어가셔서 그때그때 찾아보시면 됩니다.
이 강좌에서 소개하는 모듈들은 자주 쓰이는 모듈들이라는 것.
assert: 값을 비교하여 프로그램이 제대로 동작하는지 테스트하는 데 사용합니다.dns: 도메인 이름에 대한 IP 주소를 얻어내는 데 사용합니다.net: HTTP보다 로우 레벨인 TCP나 IPC 통신을 할 때 사용합니다.string_decode: 버퍼 데이터를 문자열로 바꾸는 데 사용합니다.tls: TLS와 SSL에 관련된 작업을 할 때 사용합니다.tty: 터미널과 관련된 작업을 할 때 사용합니다.dgram: UDP와 관련된 작업을 할 때 사용합니다.v8: V8 엔진에 직접 접근할 때 사용합니다.vm: 가상 머신에 직접 접근할 때 사용합니다.
3.12 파일 시스템 사용하기
fs 모듈도 노드 내장 모듈입니다.
하지만 중요한 모듈이라 따로 다룹니다.
-
파일 시스템에 접근하는 모듈
브라우저에서는 파일 시스템에 접근할 수 없는데 노드에서는 여러분들의 파일시스템에 접근할 수 있어서,
예를 들어 파일을 생성하거나 삭제하거나 폴더를 생성/삭제, 폴더나 파일이 존재하는지 체크, 이런 것들이 다 가능합니다.
그래서 보안상 조금 조심해야된다고도 말씀드렸죠?
악성 자바스크립트를 노드로 실행하게되면 여러분의 파일을 읽어서 전송을 해버릴수도 있고, 그래서 그런걸 조심하셔야되는데 일단 파일시스템 모듈 사용 방법은 알려드리겠습니다.- 파일/폴더 생성, 삭제, 읽기, 쓰기 가능
- 웹 브라우저에서는 제한적이었으나 노드는 권한을 가지고 있음
-
파일 읽기 예제(결과의 버퍼는 뒤에서 설명함)
/* 파일명: readme.txt */ 저를 읽어주세요.위와 같이
.txt파일을 만들어주시고.. 보통.txt파일이나csv,excel,pdf이런 파일들을 주로 읽겠죠?
word나 한글 파일을 읽을 수도 있습니다.
그런 파일들도 다 가능합니다.// readfile.js const fs = require("fs"); fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log(data); console.log(data.toString()); })fs모듈 메소드는 콜백 함수 형태를 띄고 있습니다.
그리고 노드에선 콜백함수의 첫번째 인자가error, 두번째 인자가data라고 그랬죠?
대부분은 다 그렇습니다.
그래서 나중에util.promisify로 프로미스로 바꿀 수도 있다고 그랬죠?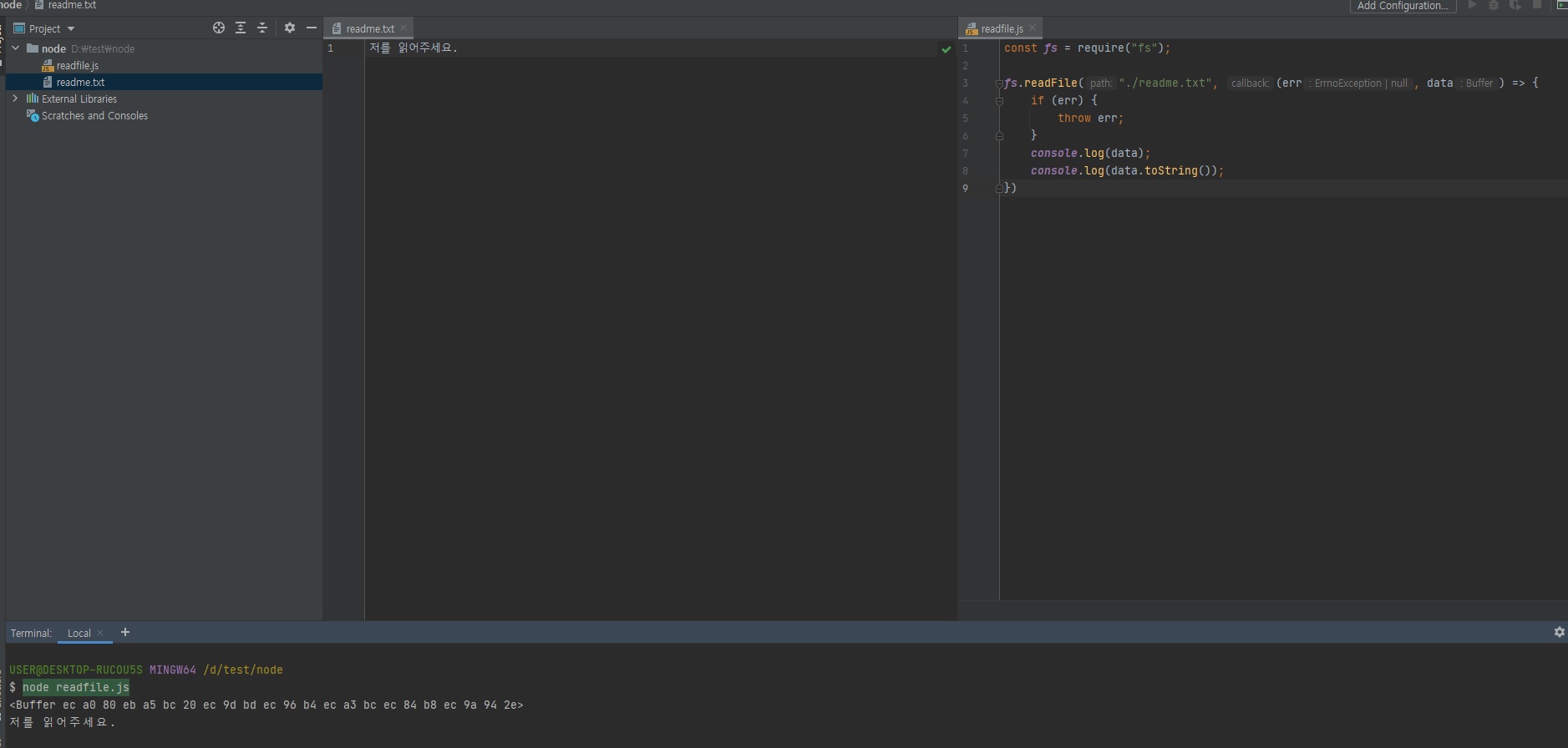
console.log(data)를 찍으면 아까 제가 말씀드렸던 0과 1로 이루어진 데이터, 컴퓨터가 다루는 2지넙 바이너리 데이터가 나옵니다.
어 그런데 0, 1이 아닌데요? 알파벳인데요? 라고 말씀하실 수도 있는데 위 알파벳이 2진법을 16진법으로 바꾼겁니다.
2진법이나 16진법이나 어차피 사람이 못 읽는 것은 똑같습니다.
위의 콘솔창에 뜬 결과처럼 앞에 Buffer or Binary라고 되어있으면 아 컴퓨터가 다루는 0, 1로 표현된 데이터구나 라고 보시면 됩니다.
이를 사람이 읽을 수 있게 하려면console.log(data.toString())으로 해주셔야겠죠?이렇게 노드를 통해서 컴퓨터에 있는 파일을 읽을 수 있습니다.
이게 경로만 잘 지정하면 C 드라이브 안에programfile폴더나windows폴더 같이 중요한 폴더들의 내용도 읽을 수가 있습니다.
그래서 이런 스크립트 조심하시지 않으면 여러분의 중요한 파일을 읽어가버릴 수도 있으니까 그런점은 조심하셔야됩니다.
-
콜백 방식 대신 프로미스 방식으로 사용 가능
- require("fs").promises
-
사용하기 훨씬 더 편해서 프로미스 방식을 추천함
여기서 fs promise가 나오는데 위 코드에서
fs.readFile(파일경로, 콜백)콜백으로 되어있어서 콜백 헬과 같은 문제가 발생하거든요?
그래서 이를 Promise를 지원하게 하고 싶으면, 위 코드 자체로 Promise화 하시려면 위fs.readFile(파일경로, 콜백)코드를util.promisify()함수로 감싸셔야됩니다.
하지만fs에선 더 좋은 방법을 제공합니다.
워낙fs를 프로미스로 만들어달라는 요청이 많았기 때문에 아래와 같이 뒤에.promises만 붙이면 알아서fs가 프로미스를 지원하도록 바뀝니다.
그래서 아래와 같이.then()과.catch()를 사용할 수 있습니다.const fs = require("fs").promises; fs.readFile("./readme.txt") .then((data) => { console.log(data); console.log(data.toString()); }) .catch((err) => { throw err; })위와 같이 사용할 수 있다는 말은
async/await도 쓸 수 있다는 뜻이 되겠죠?
저는 그래서require("fs").promises를 많이 씁니다.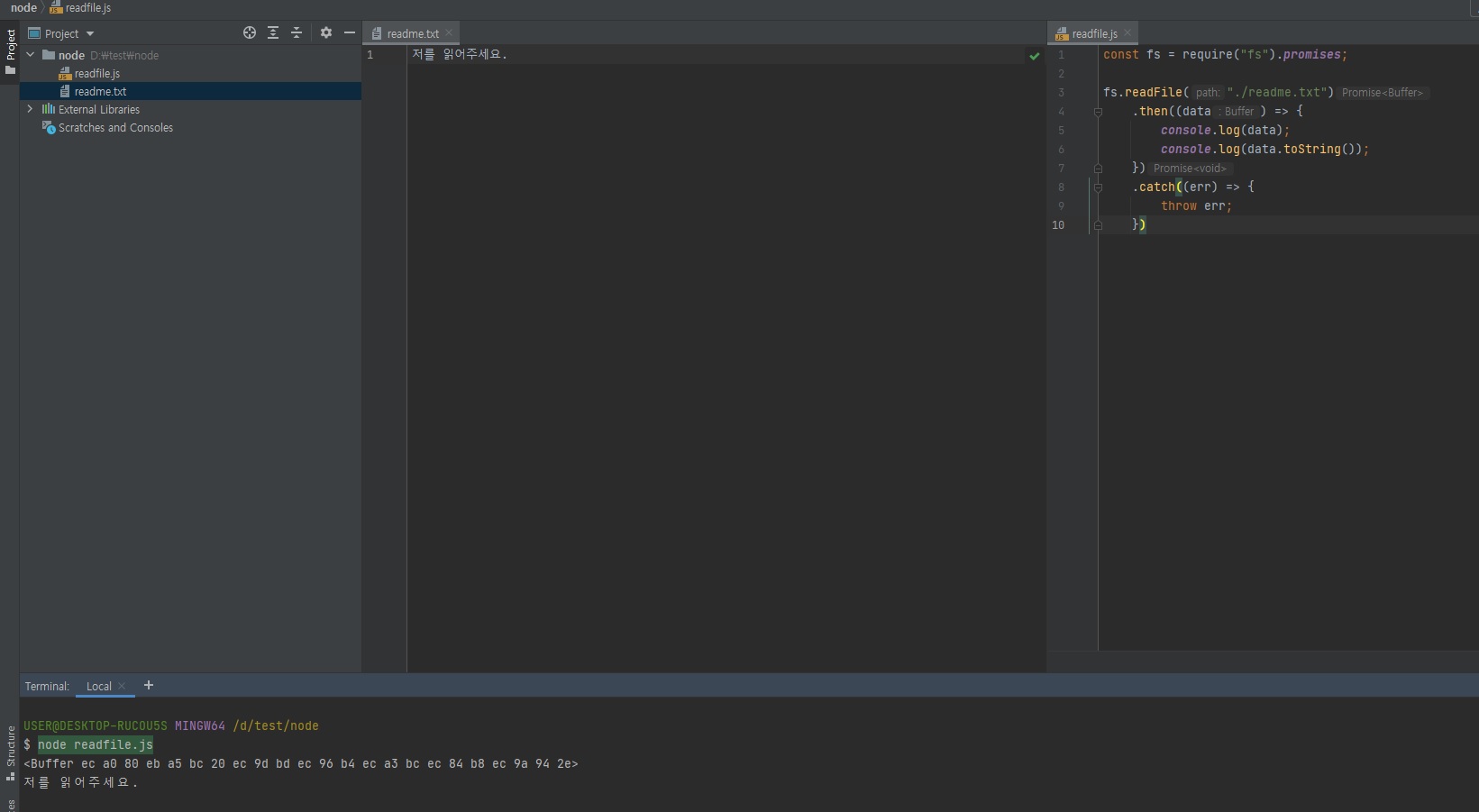
결과는 똑같습니다.
위 코드를async/await로 바꾸면 아래처럼 되려나..? 잘은 모르겠지만..const fs = require("fs").promises; (async () => { try { const data = await fs.readFile("./readme.txt"); console.log(data); console.log(data.toString()); } catch (err) { throw err; } })()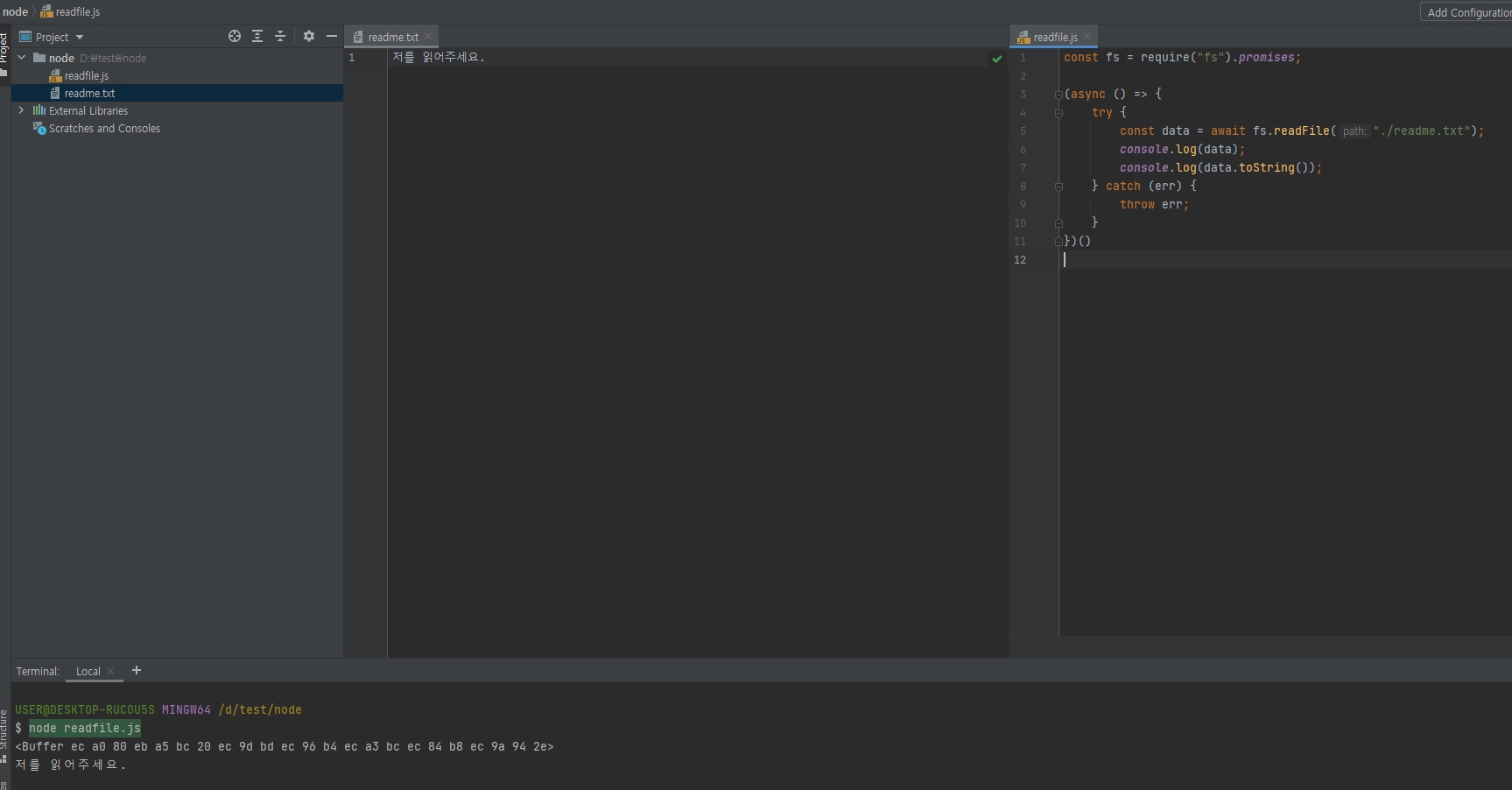
앞으로는 위 코드들처럼
.pomises를 붙여서 사용하도록 하겠습니다.
3.12.1 fs로 파일 만들기
-
파일을 만드는 예제
프로미스를 이용해 프로미스 체이닝으로 아래와 같이 작성할 수 있습니다.// writeFile.js const fs = require("fs").promises; fs.writeFile("./writeme.txt", "글이 입력됩니다") .then(() => { return fs.readFile("./writeme.txt"); }) .then((data) => { console.log(data.toString()); }) .catch((err) => { console.error(err); })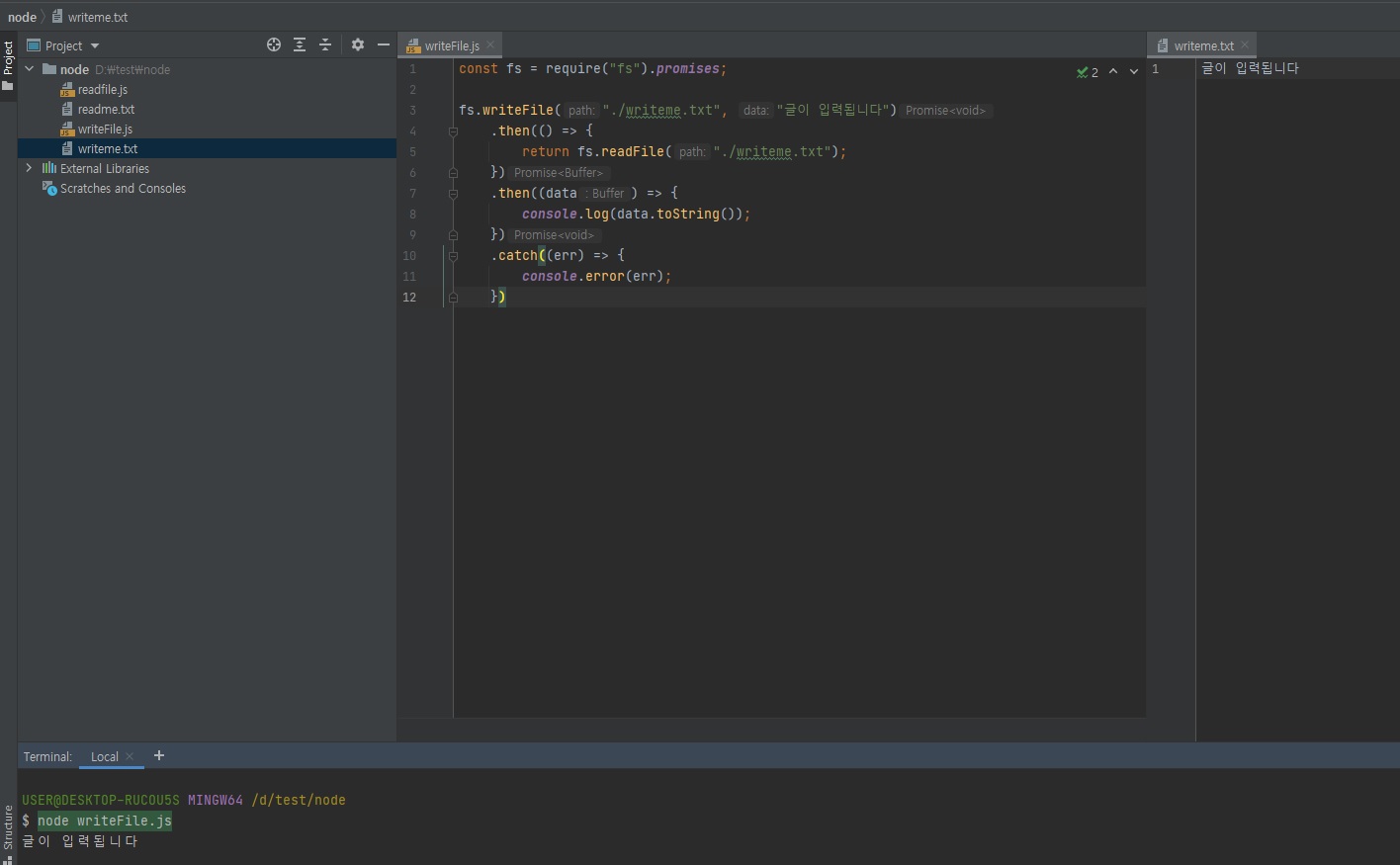
프로미스나 콜백 함수는 둘 다 비동기 방식이죠?
.promises를 붙이지 않은 방식도 콜백 함수로 비동기 방식입니다.
비동기면 순서대로 실행되지 않는다고 했죠?
그래서 그 현상을 직접 확인을 해볼겁니다.
3.12.2 동기 메소드와 비동기 메소드
-
노드는 대부분의 내장 모듈 메소드를 비동기 방식으로 처리
- 비동기는 코드의 순서와 실행순서가 일치하지 않는 것을 의미
- 일부는 동기 방식으로 사용 가능
-
아래 코드 콘솔 예측해보기
// async.js const fs = require("fs"); fs.readFile("./readme.txt", (err, data) => { // 에러는 꼭 처리 권장 // 에러 처리 관련은 뒤에 좀 더 설명을 드리겠습니다. if (err) { throw err; } console.log("1번", data.toString()); }) fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("2번", data.toString()); }) fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("3번", data.toString()); }) fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("4번", data.toString()); })
비동기/동기, 논블로킹/블로킹
노드에선 비동기면 논블로킹이고 동기이면 블로킹이다. 라고 보셔도 된다고 말씀드렸었습니다.
-
콜백 방식
// async.js const fs = require("fs"); fs.readFile("./readme.txt", (err, data) => { // 에러는 꼭 처리 권장 // 에러 처리 관련은 뒤에 좀 더 설명을 드리겠습니다. if (err) { throw err; } console.log("1번", data.toString()); }) fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("2번", data.toString()); }) fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("3번", data.toString()); }) fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("4번", data.toString()); })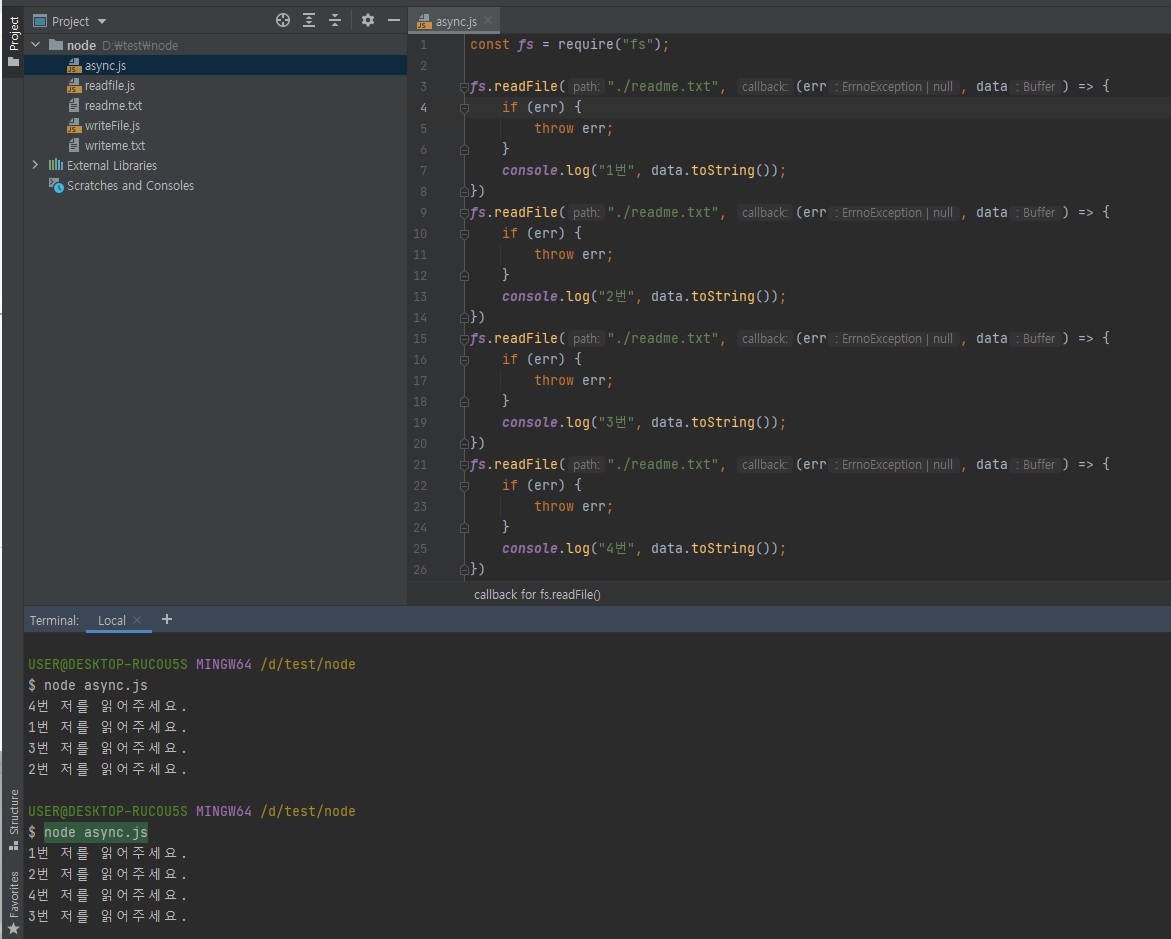
위 실행 결과를 보시면 실행 순서가 랜덤이란걸 확인하실 수 있습니다.
이렇게 랜덤이라면 프로그램을 개발할 때 에로사항이 많겠죠?
어떤게 먼저 실행될지를 모르기 때문입니다.위의
readFile메소드는 비동기 함수이기 때문에 비동기 함수는 콜백함수를 백그라운드로 보내주거든요?백그라운드로 넘어가면 동시에 실행된다고 했습니다.
그래서 위의 콜백함수 4개가 동시에 실행이됩니다.
그런데 동시에 실행되면 누가 먼저 끝날지는 운영체제만 알거든요?
아무도 모릅니다. 사람이 판단할 수 없습니다.
운영체제에서 먼저 끝나는대로 테스크 큐로 넣어주는 거기 때문에, 운이 좋으면 1, 2, 3, 4번 순서대로 실행될 수도 있지만 반대로 4, 3, 2, 1 이렇게 될 수도 있습니다.
이는 아무도 모릅니다.
순서 보장이 안된다는 것!
3.12.3 동기 메소드와 비동기 메소드
-
위의 예제를 여러 번 실행해보기
- 매번 순서가 다르게 실행됨
-
순서에 맞게 실행하려면?
두가지 방법이 있습니다.- 비동기를 유지한 채로 순서대로 실행하게 하는 방법
-
함수를 동기적으로 실행
동기적으로 실행되면 코드가 위에서 아래로, 왼쪽에서 오른쪽으로 순서대로 실행된다고 했죠?
동기가 왜 순서대로 실행되냐면, 첫번째 코드가 실행되는 동안에 다른 코드는 아예 실행조차 되지 못하기 때문입니다.
반면 비동기는 첫번째 코드가 실행돼면, 바로 다음 코드로 넘어갑니다.
해당 첫번째 코드는 백그라운드로 보내고말입니다.
비동기는 코드는 일단 순서대로 실행하지만 백그라운드로 보낸 코드들이 완료되는 순간 테스크 큐를 거쳐서 호출스택으로 오는 것은 랜덤입니다.
당연히 웬만한 경우엔 비동기 논블로킹이 효율적입니다.
다만, 비동기 논블로킹은 순서가 문제이므로 순서를 어떻게 맞출건지에 대해서 알아두셔야합니다.그런데 동기 메소드를 아예 안 쓰는 것은 아닙니다.
동기는 물론 앞에 코드가 끝나야 다음 코드가 실행되고, 다음 코드가 끝나야 그 다음 코드가 실행되고 이러니까 동시 실행이 안돼서 느릴 수도 있는데,
특히 아까 위에서 보여드렸던 소수 찾기 예제 있죠?
그걸 동기적으로 실행한다면 엄청 오래 기달려야되잖아요?
이럴 땐 안좋은데 딱 한번만 실행한다거나 초기화 작업을 할 때는 동기 메소드를 사용하곤 합니다.딱 한번만 실행해야될 때는 동기나 비동기나 어차피 한번만 실행되는 거기 때문에 성능적으로 크게 문제가 없는 경우가 많고, 서버같은 경우 특히 동기로하면 대부분의 경우에 클린하거든요?
예를 들어 100명의 사람이 요청을 보냈는데 그 100명의 작업을 동시에 처리를 못하고 한명한명 순차적으로 처리를 해준다면, 100번째 사람은 엄청 오래 기다려야겠죠?
그런데 그런 서버가 아니라 서버를 시작하기 전에 초기화를 할 때, 서버 시작하기 전에 파일을 만들어 놓거나 중요한 비밀번호 파일을 삭제하거나 그런 작업을 할 때는 아직 서버 시작전이니까 그럴땐 동기로 해도 큰 문제가 없습니다.서버가 시작된 후에는 동기는 웬만하면 안 쓰는 것이 좋고 서버 시작 전, 세팅 작업을 할 때는 동기를 쓰셔도 됩니다.
어쨌든fs는 특이하게 동기 메소드를 다 지원하긴 합니다.
- 동기와 비동기: 백그라운드 작업 완료 확인 여부
- 블로킹과 논 블로킹: 함수가 바로 return 되는지 여부
-
노드에서는 대부분 동기-블로킹 방식과 비동기-논블로킹 방식임
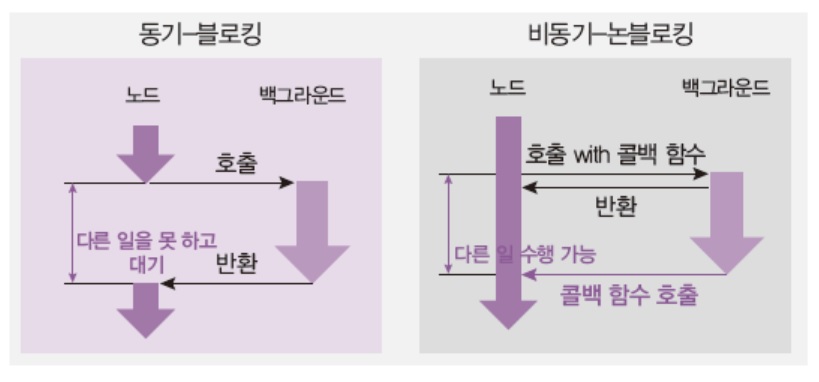
동기와 비동기, 블로킹과 논블로킹 정리
-
Blocking I/O와 NonBlocking I/O, Synchronous와 Asynchronous
동기(Synchronous)와 비동기(Asynchronous) 그리고 블로킹과 논블로킹의 차이를 알아보겠습니다.
-
Blocking I/O
호출된 함수가 바로 return을 하지 않음.
호출된 함수가 자신의 작업을 모두 끝낼 때까지 제어권을 가지고 있어 호출한 함수가 대기하도록 만듦 -
NonBlocking I/O
호출된 함수가 바로 return해서 호출한 함수에게 제어권을 주어 다른 일을 할 수 있게 함
호출된 함수가 바로 return 하느냐 마느냐가 중점
Synchronous / Asynchronous
-
Synchronous (동기)
-
동기는 함수를 호출하고 호출된 함수의 작업이 완료된 후의 return을 기다리거나 return을 받더라도 호출한 함수가 계속해서 작업완료 여부를 신경씀.
완료됐어? 라고 자꾸 물어보는거라고 생각하면 됨.// 동기적 코드 console.log("1"); console.log("2"); console.log("3"); // 1 // 2 // 3
-
-
Asynchronous (비동기)
-
동기는 함수를 호출할 때 callback 함수를 같이 전달해 작업이 완료되면 callback을 실행, 작업완료를 callback이 신경씀
// 비동기적 코드 function foo() { console.log("1"); } setTimeout(foo, 2000); console.log("2"); console.log("3"); // 2 // 3 // 1 -
호출되는 함수의 작업 완료 여부를 누가 신경쓰느냐가 중점
-
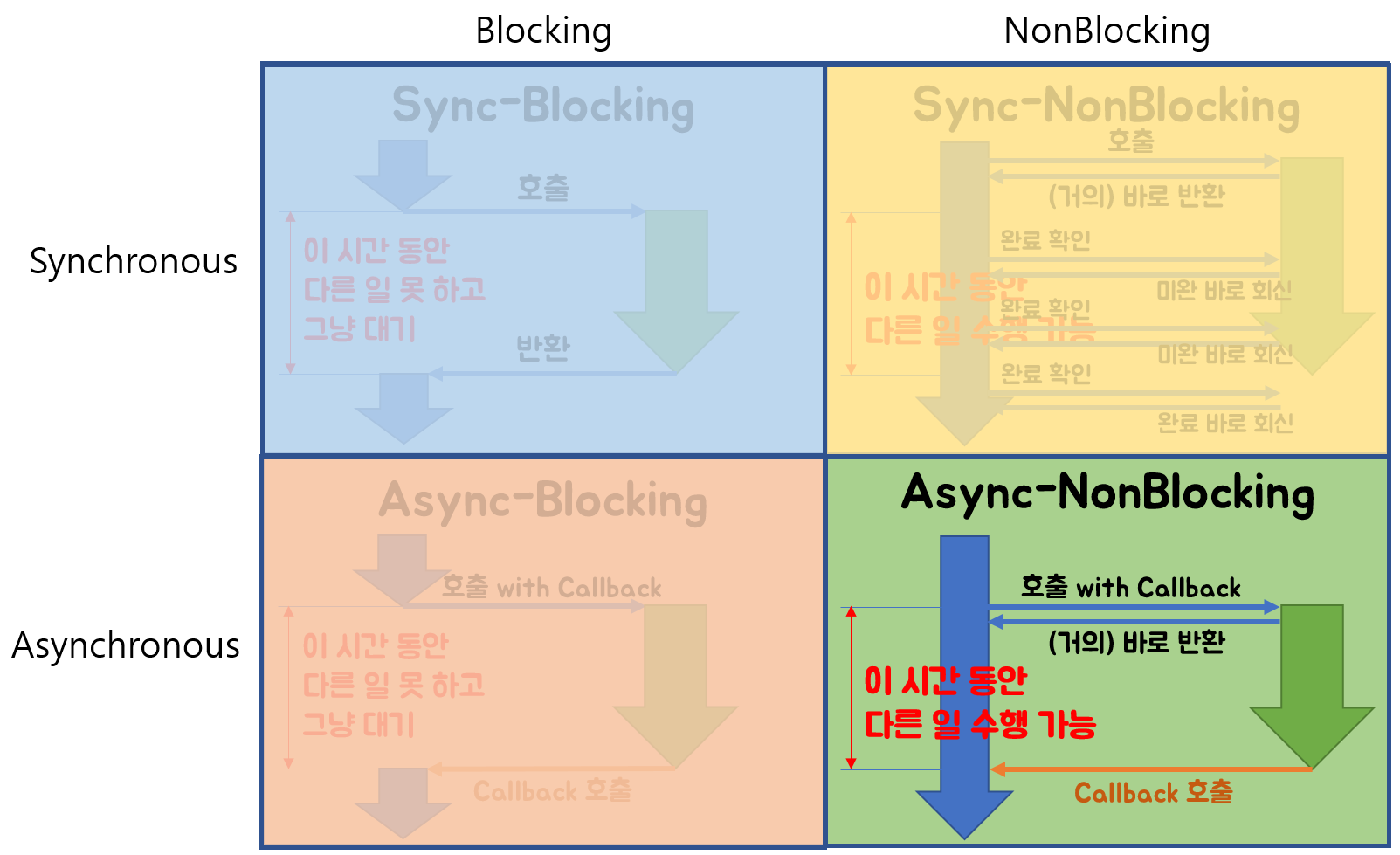
여기서 조합을 살펴보면 Blocking & Sync와 NonBlocking & Async는 쉽게 이해가 된다.
하지만 NonBlocking & Sync와 Blocking & Async는 조금 설명이 필요하다.
-
NonBlocking & Sync를 알아보자
- NonBlocking은 바로 return을 해서 제어권을 준다고 했고,
Sync는 작업 완료 여부를 호출한 쪽에서 신경을 쓴다고 했다.
이후에 작업이 완료되었는지 계속 물어보는 일을 추가로 수행하는 것이 NonBlocking & Sync이다.
- NonBlocking은 바로 return을 해서 제어권을 준다고 했고,
-
Blocking & Async를 알아보자
- 우선 Blocking은 작업이 완료될 때까지 제어권을 호출된 쪽에서 가지고 있고,
return을 안해준다는 뜻이다!
Async는 작업 완료 여부를 호출된 쪽에서 신경을 쓴다.
어차피 제어권이 없는 상태에서 결과만 기다리는 Blocking & Sync와 별 차이가 없는 것 같다. (Blocking & Sync : return 바로 안해주고.. 완료되었는지 계속확인)
이 방식은 특별한 장점이 없어 일부로 사용할 필요는 없다고 한다.
보통 NonBlocking & Async 방식을 쓰는데 그 과정중 하나라도 Blocking이 포함이되면 의도치않게 Blocking & Async로 작동한다고 한다.
- 우선 Blocking은 작업이 완료될 때까지 제어권을 호출된 쪽에서 가지고 있고,
-
마치며
- 동기와 비동기, 블로킹 논블로킹을 이해할 때 위의 참고문서를 많이 봤다.
- 정말 정리가 잘 되어있어 이해하는데 도움이 되었다.
- 개념을 일단 알아둔 후에 실제로 무언가를 만들 때 참고하면 좋을 것 같다.
- 추가적으로 자바스크립트와 이벤트 루프의 글도 읽어보는게 도움이 된다.
3.12.4 동기 메소드 사용하기
아래츠럼 readFileSync 동기 메소드로 작성해주면 콜백함수는 지웁니다.
콜백이나 프로미스는 비동기라고 그랬죠?
// sync.js
const fs = require("fs");
let data = fs.readFileSync("./readme.txt");
console.log("1번", data.toString());
data = fs.readFileSync("./readme.txt");
console.log("2번", data.toString());
data = fs.readFileSync("./readme.txt");
console.log("3번", data.toString());
data = fs.readFileSync("./readme.txt");
console.log("4번", data.toString());
위와 같이 동기적으로 작성해줄 수 있습니다.
콜백을 안써도되므로 코드가 좀 더 깔끔하죠?
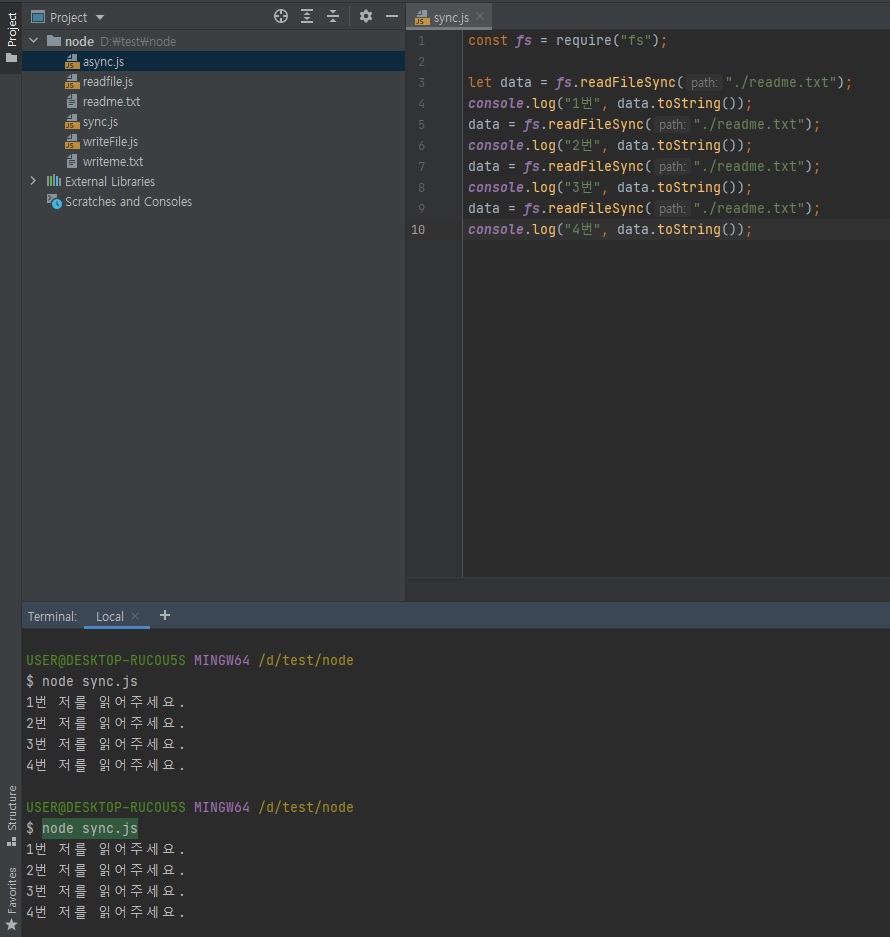
여러번 실행해서 테스트해봐도 항상 1, 2, 3, 4 순서대로 실행이 됩니다.
동기로 작성하면 이렇게 순서대로 실행되는 것이 좋습니다.
하지만 사람이 이해하기엔 좋지만 실제로 프로그래밍 상으론 동시에 돌릴 수가 없어서 매우 비효율적인 방식입니다.
그래서 위 코드 방식은 딱 한번 실행하거나 서버 같은거를 실행하기 전에 서버 초기화 작업을 할 때 그럴 때나 사용하지 서버가 실행된 후에도 위와 같이 동기 코드를 쓰면 사람들이 기다려야된다는 것.
특히 사용자가 많을 수록 마지막 사용자는 엄청 오래 기다려야된다는 것.
동기 작업은 사용하실 때 항상 주의를 하셔야됩니다.
대부분은 비동기 작업을 하면서 순서를 유지하시는 것을 추천드립니다.
3.12.5 비동기 메소드로 순서 유지하기
-
콜백 형식 유지
-
코드가 우측으로 너무 들어가는 현상 발생(콜백 헬)
// asyncOrder.js const fs = require("fs"); console.log("시작"); fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("1번", data.toString()); fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("2번", data.toString()); fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("3번", data.toString()); fs.readFile("./readme.txt", (err, data) => { if (err) { throw err; } console.log("4번", data.toString()); }) }) }) })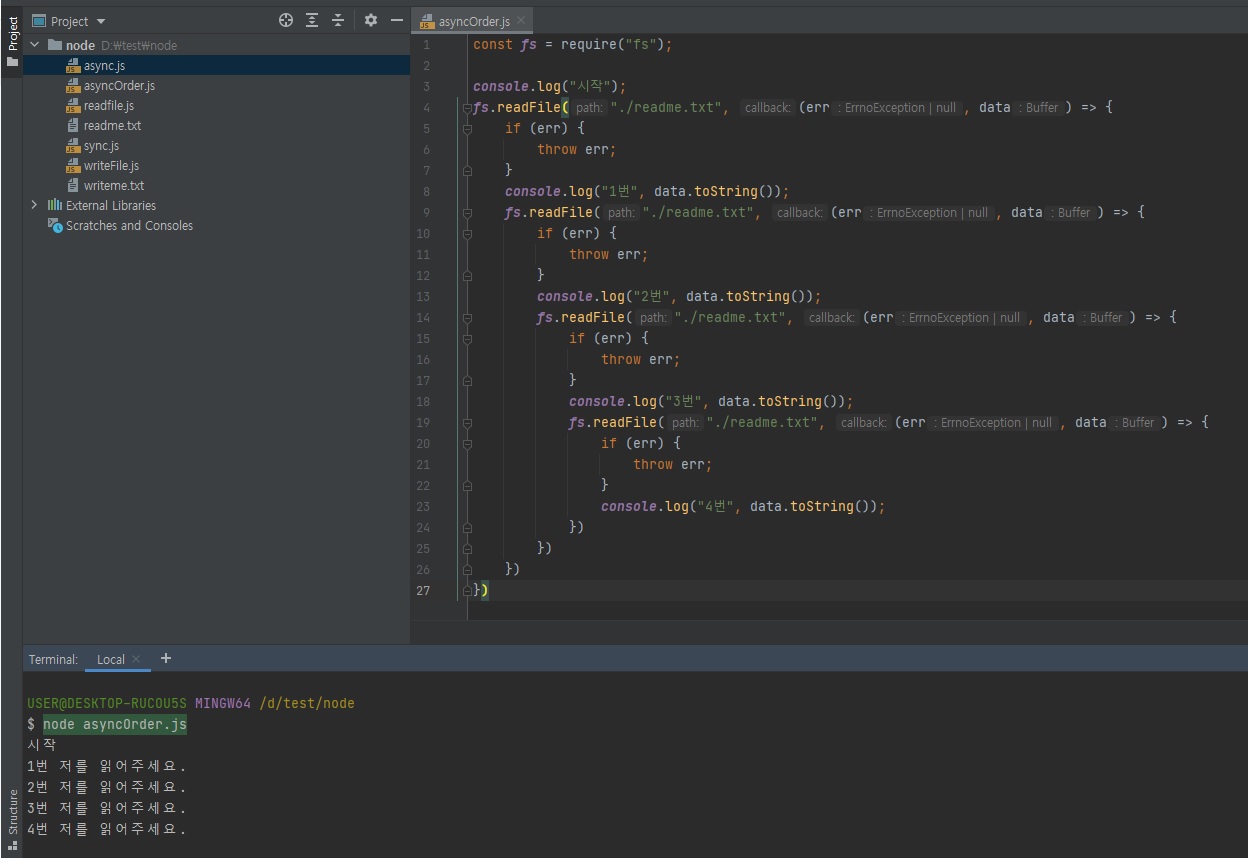
콜백지옥이긴 해도 코드가 순서대로 실행되긴 합니다.
어, 그러면 위 코드는 동기랑 무슨 차이가 있죠?라고 하실 수도 있지만,
위asyncOrder.js파일 같은 것을 여러개 실행하는 경우, 위 코드의 콜백 함수들이 다 백그라운드로 넘어가기 때문에asyncOrder.js파일을 여러개 실행하는 경우엔 그 코드들이 다 같이 백그라운드로 들어가서 다 동시에 실행이 됩니다.그런데 앞서 보여드린
sync.js같은걸 여러개 동시 실행하는 경우는 그 파일들이 실행된 순서대로 실행되거든요?
만약sync.js파일 10개를 동시에 실행한다면 40개의 코드(1, 2, 3, 4번)가 순서대로 실행되지만,
asyncOrder.js파일을 10개를 동시에 실행한다면 10개 묶음의 코드가 백그라운드로 넘어가서 동시에 실행됩니다.
asyncOrder.js는 코드 순서도 지키면서 동시에 파일을 여러개 실행했을 때 다 같이 백그라운드로 들어간다 라고 보시면 됩니다.그래서 위와 같이 콜백으로 작성하면 동시성도 살릴 수 있다.라는 것.
다만 위와 같이 작성하면 콜백헬이 발생하니까 위와 같은 것은 프로미스로 깔끔하게 만들어주면 좋겠죠?
-
-
프로미스로 극복
// asyncOrderPromise.js const fs = require("fs").promises; console.log("시작"); fs.readFile("./readme.txt") .then((data) => { console.log("1번", data.toString()); return fs.readFile("./readme.txt"); }) .then((data) => { console.log("2번", data.toString()); return fs.readFile("./readme.txt"); }) .then((data) => { console.log("3번", data.toString()); return fs.readFile("./readme.txt"); }) .then((data) => { console.log("4번", data.toString()); }) .catch((err) => { throw err; })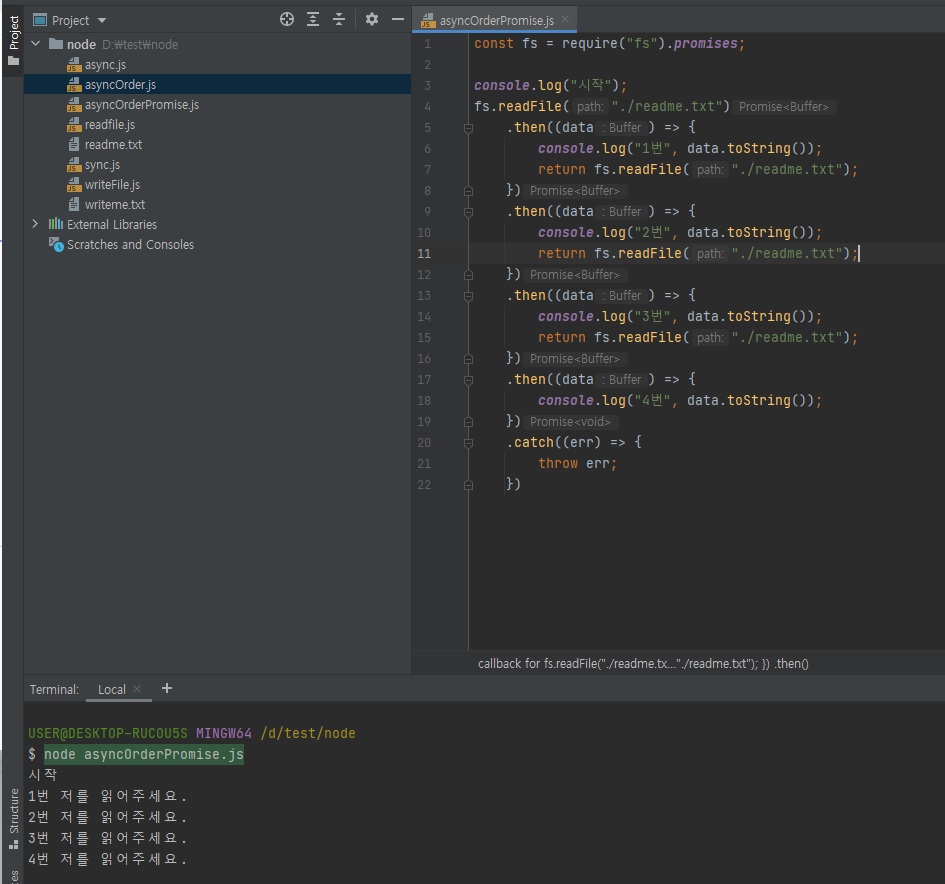
const fs = require("fs").promises; async function main() { let data = await fs.readFile("./readme.txt"); console.log("1번", data.toString()); data = await fs.readFile("./readme.txt"); console.log("2번", data.toString()); data = await fs.readFile("./readme.txt"); console.log("3번", data.toString()); data = await fs.readFile("./readme.txt"); console.log("4번", data.toString()); } main();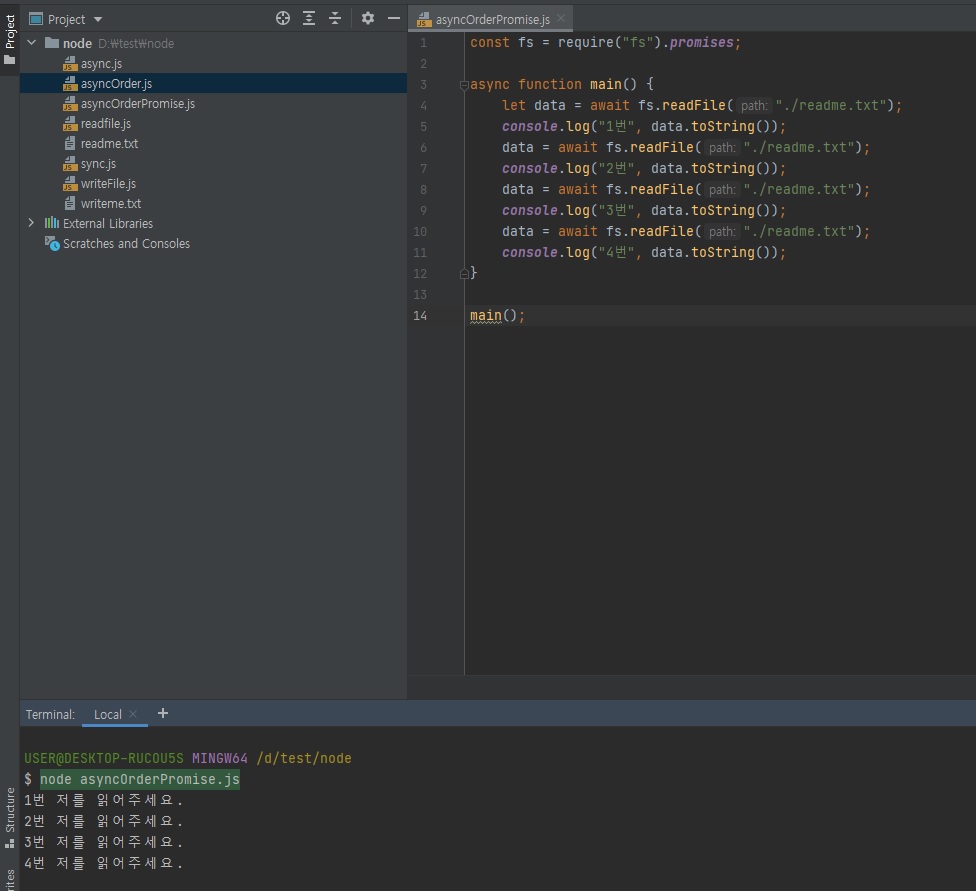
비동기로하되 순서를 지키는게 동시성도 살리고 순서도 지키는 좋은 방법이라는 것!
sync는 편하긴 하지만 실제 서버에서 사용하면 문제가 많이 발생한다는 것!
3.13 버퍼와 스트림 이해하기
파일 시스템을 하면서 버퍼와 스트림도 많이 나오는 개념입니다.
아까 위에서 버퍼는 잠깐 보셨죠? 0과 1로 되어있는 데이터.
-
버퍼: 일정한 크기로 모아두는 데이터
- 일정한 크기가 되면 한 번에 처리
- 버퍼링: 버퍼에 데이터가 찰 때까지 모으는 작업
버퍼링이란 단어는 요즘에는 잘 안보이는데 예전에는 많이 쓰던 단어였음.
하지만 요즘도 버퍼링이 있습니다.
동영상 재생하다가 인터넷 상황이 안좋으면 로딩스피너 나오다가 다시 동영상 재생되고 다시 또 인터넷 안좋으면 로딩 돌다가 다시 재생되고.
이런 식으로 되잖아요?
이게 버퍼링인데 버퍼는 데이터를 일정 크기로 모으고 난 후, 그 크기가 되면 전송해주는 거거든요?
예를 들어 16kb라고 치면 16kb가 될 때까지 데이터를 조금씩 모으다가 16kb가 되면 전송해주는, 그걸 버퍼라고 보시면 됩니다.
-
스트림: 데이터의 흐름
스트림은 버퍼들이 계속 전달되는 것을 뜻합니다.
스트리밍이라고 많이 들어보셨잖아요?
스트리밍은 버퍼들이 계속해서 전달되는 것을 뜻한다고 보시면 됩니다.- 일정한 크기로 나눠서 여러 번에 걸쳐서 처리
- 버퍼(또는 청크)의 크기를 작게 만들어서 주기적으로 데이터를 전달
-
스트리밍: 일정한 크기의 데이터를 지속적으로 전달하는 작업

-
그럼 버퍼가 스트림의 부분 집합이냐
-
그렇게 생각하실 수도 있는데, 그런 접근 보다는 버퍼 방식으로 하는거랑 스트림 방식으로 하는 거랑 이 두 가지를 비교해보려고 하거든요?
예를 들어 100mb 짜리 파일이 있습니다.
버퍼를 만약에 100mb로 뒀다고하면 서버에서 100mb가 다 찰 때까지 기다린 다음에 100mb가 다 차면 보내주겠죠? 클라이언트로?
그런데 스트림 형식인데 스트림의 버퍼를 1mb로 설정을 했다면 1mb씩 채워질 때마다 보내주는 겁니다.
그럼 1mb씩 100번 받아서 보내주면 100mb가 돼서 다 보내지는거겠죠.보통 파일 다운로드할 때 조금씩 %가 차면서 100%되면 다운로드 완료로 나오잖아요?
이런게 스트리밍이죠.
그런게 스트리밍이고 한번에 다 보내는 것은 버퍼.. 사실 이게 버퍼 방식이라고 말하기 보다는 그냥 버퍼가 파일 사이즈랑 똑같은 거에요.
버퍼가 파일 사이즈랑 똑같으면 그걸 통째로 보내는 거고 버퍼를 파일 사이즈의 1/100로 줄였다면 100번 스트리밍해서 보내는 거고.
-
3.13.1 버퍼 사용하기
노드에선 버퍼와 스트림을 다룰 수가 있는데, 대부분의 경우 스트림이 효율적이겠죠?
실제로 스트림 방식으로 해야지 서버의 메모리를 적게 차지하면서 효율적으로 데이터를 보낼 수가 있습니다.
그리고 요청 응답 할 때도 대부분 다 기본적으로 스트림 방식이 적용되어 있거든요?
버퍼 통째로 보내는 거와 스트림 방식으로 보내는 거랑 메모리 차이를 한번 비교를 해보겠습니다.
-
노드에서는 Buffer 객체 사용
버퍼의 형식은 0, 1을 16진법으로 표현한 거라고 했죠?// buffer.js const buffer = Buffer.from("저를 버퍼로 바꿔보세요"); console.log("from():", buffer); // 버퍼 데이터로 변환, 컴퓨터만 알아볼 수 있는 0, 1 데이터로 바뀝니다. console.log("length:", buffer.length); // 버퍼의 크기 console.log("toString():", buffer.toString()); // 버퍼 데이터를 다시 문자열 데이터로 변환 // 물론 거의 대부분의 프로그램은 이렇게 문자열이 있으면 알아서 Buffer로 바꿔서 전송하고 // 전송받은 다음엔 알아서 문자열로 바꿔주긴하는데 이렇게 수동으로도 할 수 있다는 것 // 버퍼는 아래와 같이 조각조각 나는 경우가 많음, 어떨때 조각조각이 날까? // 방금 예시로 들어드렸던 스트리밍할 때, 100mb짜리 파일을 1mb씩 조각조각내서 보낸다고 했죠? // 그럼 받는 쪽에서는 그 100번 나눠받은 것을 다시 하나로 합쳐줘야겠죠? // 그런걸 보여드리도록 하겠습니다. const array = [Buffer.from("띄엄 "), Buffer.from("띄엄 "), Buffer.from("띄어쓰기")]; // 버퍼 여러개가 위와 같이 배열에 들어있다면 Buffer.concat()으로 합칠 수 있습니다. const buffer2 = Buffer.concat(array); // 합친 버퍼를 문자열로 변환 console.log("concat():", buffer2.toString()); // 가끔씩 데이터는 없는데 빈 버퍼를 만들어야 할 때가 있습니다. const buffer3 = Buffer.alloc(5); // 빈 5바이트 짜리 버퍼 만들기 console.log("alloc():", buffer3);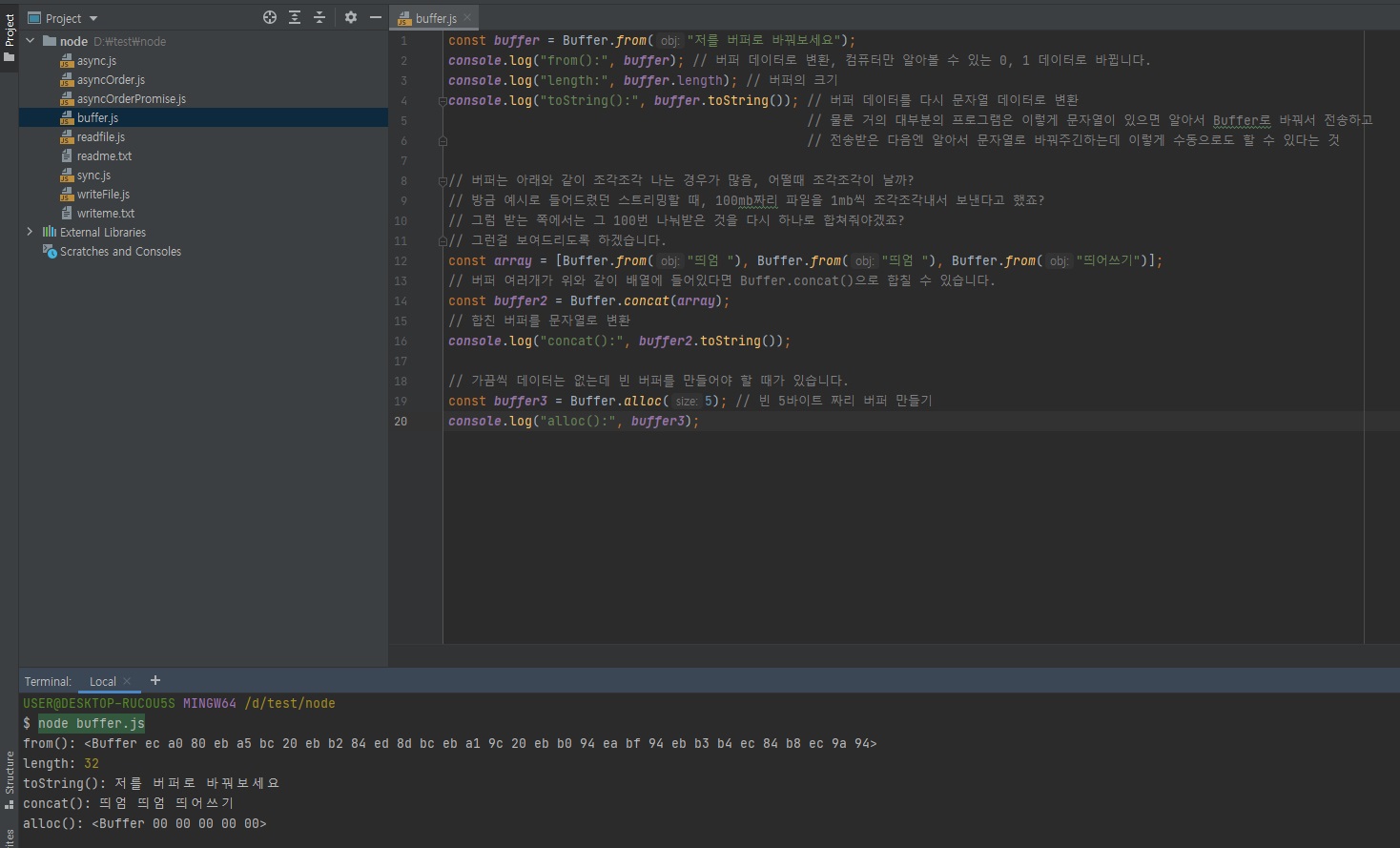
3.13.2 Buffer의 메소드
-
노드에서는 Buffer 객체 사용
from(문자열): 문자열을 버퍼로 바꿀 수 있습니다. length 속성은 버퍼의 크기를 알려줍니다. 바이트 단위입니다.toString(버퍼): 버퍼를 다시 문자열로 바꿀 수 있습니다. 이때 base64나 hex를 인자로 넣으면 해당 인코딩으로도 변환할 수 있습니다.concat(배열): 배열 안에 든 버퍼들을 하나로 합칩니다.alloc(바이트): 빈 버퍼를 생성합니다. 바이트를 인자로 지정해주면 해당 크기의 버퍼가 생성됩니다.
-
파일시스템의
readFileconst fs = require("fs").promises; fs.readFile("./readme.txt") .then((data) => { console.log(data); console.log(data.toString()); }) .catch((err) => { throw err; })위 코드는
readFile메소드는readme.txt라는 파일을 통째로 읽은 겁니다.
즉, 버퍼가 파일 크기와 똑같은 겁니다.
그래서 딱 한번만에 읽는 거고..
그래서 저희가 스트림 방식으로 잘개잘개 쪼개서 여러번에 걸쳐서 전달을 해볼거거든요?
3.13.3 파일 읽는 스트림 사용하기
-
fs.createReadStream
- createReadStream에 인자로 파일 경로와 옵션 객체 전달
- highWaterMark 옵션은 버퍼의 크기(바이트 단위, 기본값 64KB)
-
data(chunk 전달), end(전달 완료), error(에러 발생) 이벤트 리스너와 같이 사용
/* readme3.txt 파일 */ 저는 조금씩 조금씩 나눠서 전달됩니다. 나눠진 조각을 chunk라고 부릅니다. 안녕하세요. 헬로 노드 헬로 스트림 헬로 버퍼위 텍스트 파일을 버퍼 = 파일사이즈로 읽으려면
readFile메소드를 사용하시면 되고,
스트림으로 읽으시려면createReadStream사용// createReadStream.js const fs = require("fs"); // 아래와 같이 하시면 readme3.txt 파일을 조각조각내서 조금씩 조금씩 전달해줍니다. // 대신에 조각냈으므로 받을 때는 다시 합쳐줘야겠죠? const readStream = fs.createReadStream("./readme3.txt"); // 빈배열 생성. readme3.txt 파일을 조금씩조금씩 조각내서 읽기 때문에, 조각난 데이터가 아래 코드의 chunk 인자로 오거든요? const data = []; // data가 오는 이벤트 핸들러를 등록해줍니다. readStream.on("data", (chunk) => { // chunk 데이터가 올 때마다 빈배열에 모아줍니다. data.push(chunk); console.log("data:", chunk, chunk.length); }) // data가 다 왔다 끝났다 이벤트 핸들러를 등록해줍니다. readStream.on("end", () => { // data가 다 오면 조각조각 났던 데이터를 모아줍니다. console.log("end:", Buffer.concat(data).toString()); }) // 스트림을 할 때는 항상 에러 처리를 해줍니다. // 노드에서 스트림도 비동기거든요? 비동기들은 항상 에러 처리를 해주셔야됩니다. // 에러가 나는 경우가 흔하진 않은데 나는 경우가 있기는 합니다. 에러 한번 났을 때 프로그램이 망가지기 때문에 항상 에러 처리를 해주셔야합니다. readStream.on("error", (err) => { console.log("error:", err); })어떻게 보면
worker_threads랑 비슷하죠?
나눠서 일처리 시킨다음에 나중에 최종적으로 모아주는, 다만 스트림은 순서대로 온다는 것.
조각조각내서 동시에 오는 것이 아니라, 1mb씩 100번 전송온다고 한다면 1mb씩 순서대로 보내줍니다.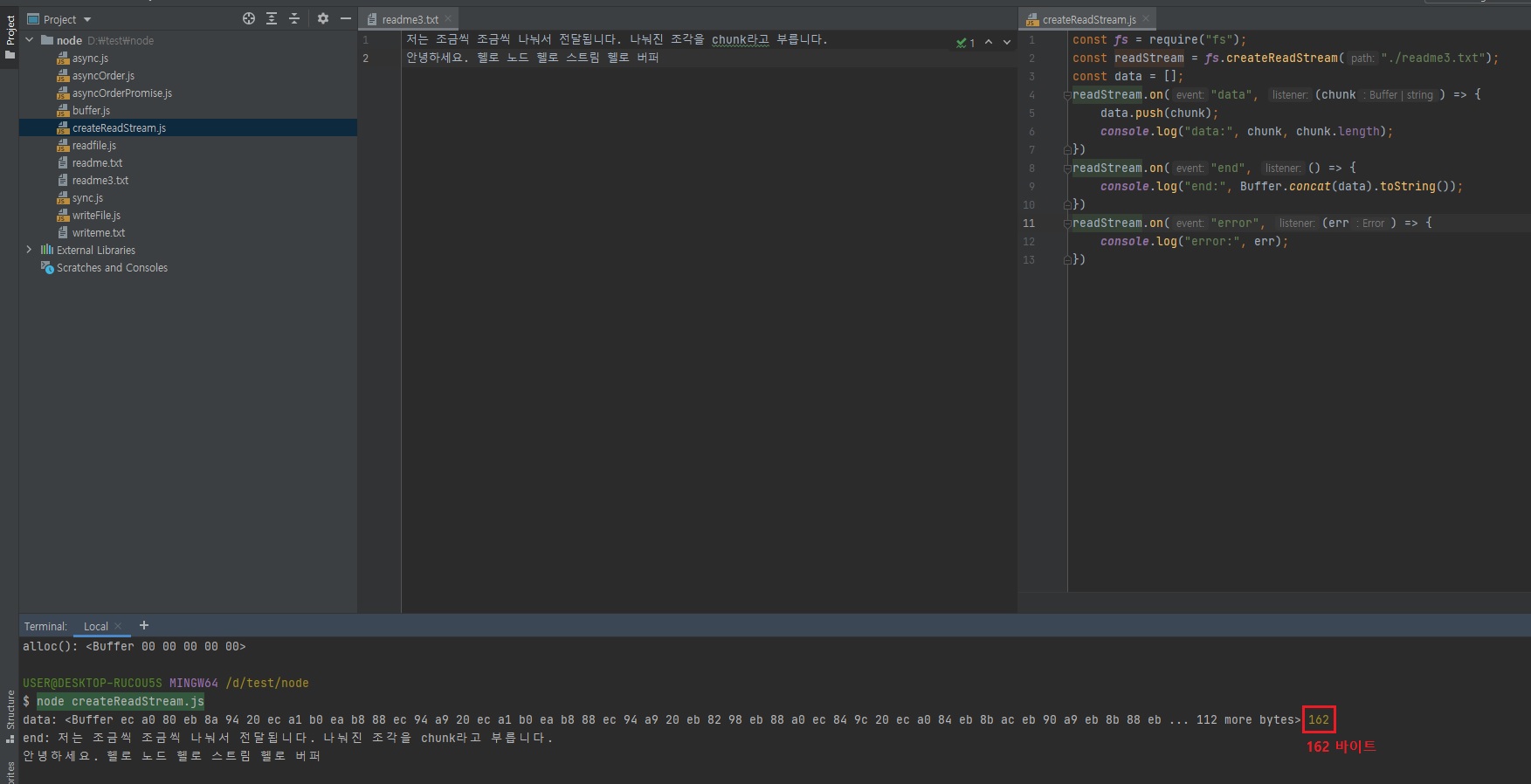
어? 그런데 조금 이상합니다.
분명 chunk 데이터로 조각조각 내서 보내라고했기 때문에 console로 찍히는게 위와 같이 한번에 찍히면 안될 것 같은데,
여러번 나뉘어서 찍혀야 될 것 같은데..? 라고 하실 수도 있는데, 위와 같이 한 번에 다 나와버리죠?
그리고 162 바이트라고 나옵니다.현재
readFile함수와createReadStream함수가 다른 점이 없습니다.
괜히 코드만 더 길어졌죠?
왜 이런 현상이 일어나는 거냐면createReadStream함수는 처음에 64KB를 읽거든요?
createReadStream이 한번에 읽는 버퍼 조각 크기가 64KB인데 저희가 작성한 텍스트 파일은 162Byte 밖에 안되기 때문에 한번에 읽어버린겁니다.
그래서 테스트를 위해 위 코드를 아래와 같이 수정해줍니다.// createReadStream.js const fs = require("fs"); // highWaterMark 옵션을 추가해줍니다. 기본값은 64000입니다. // 아래와 같이 16을 입력하면 16바이트라는 뜻입니다. const readStream = fs.createReadStream("./readme3.txt", {highWaterMark: 16}); const data = []; readStream.on("data", (chunk) => { data.push(chunk); console.log("data:", chunk, chunk.length); }) readStream.on("end", () => { console.log("end:", Buffer.concat(data).toString()); }) readStream.on("error", (err) => { console.log("error:", err); })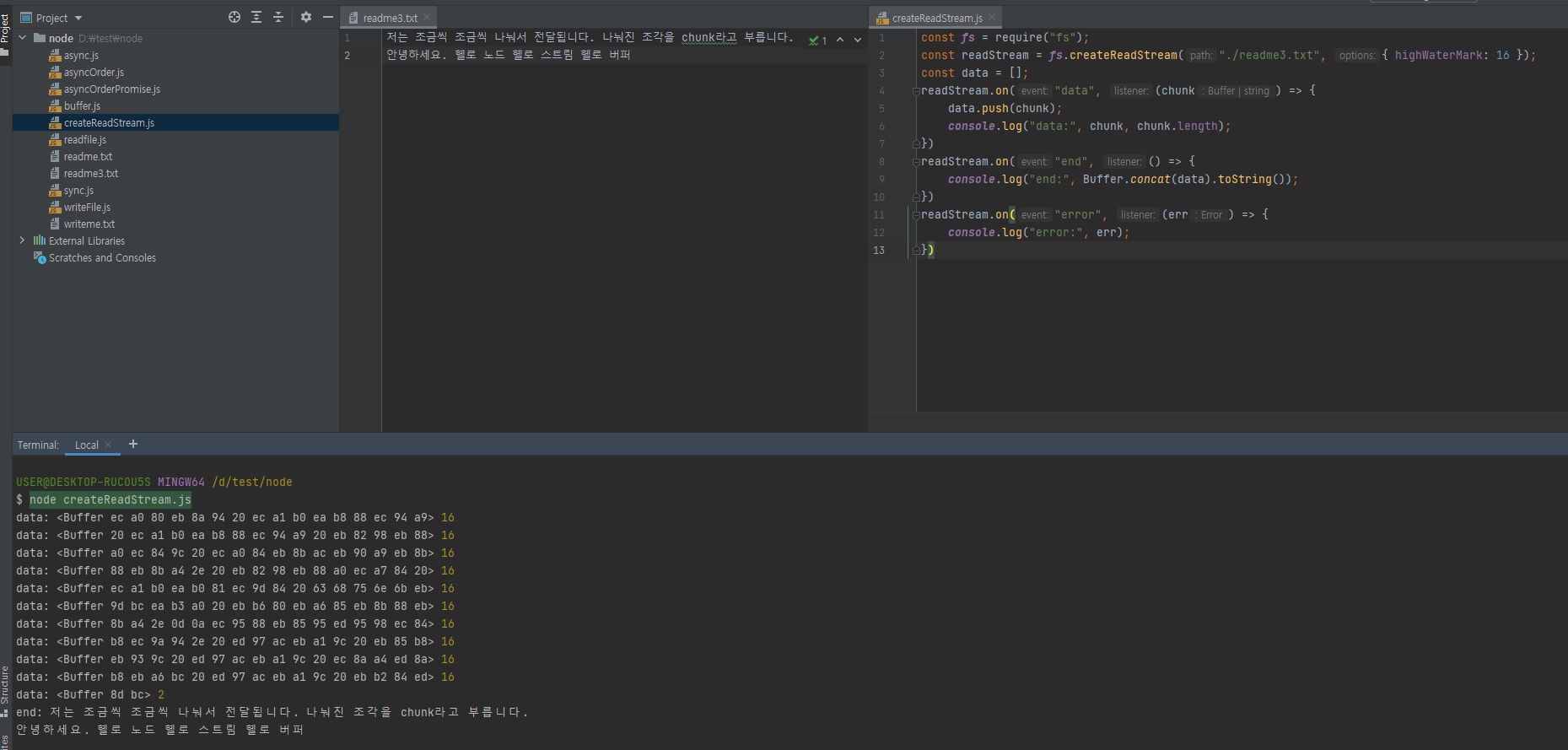
드디어 스트림의 정체를 알 수가 있죠?
위와 같이 16바이트씩 끊어서 데이터를 보내주는 겁니다.스트림 방식이 버퍼=파일사이즈 방식에 비해서 뭐가 좋냐면 메모리를 아낄 수 있다는 것입니다.
앞서
readme3.txt파일을 읽으면 162 바이트가 들잖아요?
그러면 한번에 읽어서 전달해주면 서버는 적어도 162 바이트의 메모리가 있어야지 한번에 읽어서 보내줄 수 있겠죠?
만약 서버의 메모리가 80바이트라고하면 162 바이트 못읽어서 메모리가 터져버리겠죠?
그런데 이 스트림 방식을하면 뭐가 좋냐면, 위 코드를 보면 162바이트 파일을 읽는데 메모리가 16바이트만 있으면 됩니다.
왜냐면 16바이트씩 잘라서 보내기 때문이죠.그래서 대용량 파일 서버를 할 때는 스트림 방식이 거의 필수입니다.
예를 들어 동영상 파일 서버라고 하면 고화질 동영상이면 몇GB 이상 되는 영상들이 많을 텐데, 만약 100GB 동영상을 버퍼=파일사이즈 방식으로 한번에 보내려면 서버 메모리가 100GB여야 되는 거거든요?
그런데 100GB 짜리 서버를 구축하는 사람은 진짜 부자 아니면 없습니다.
그럼 100GB 서버가 없다면 이런 동영상 서버를 못 만드느냐. 그게 아니라 스트리밍해주면 되는 겁니다.
위의highWaterMark를 예를 들어 1mb로 했다면, 1mb짜리 10만번 보내면 100GB 보낼 수 있는 거잖아요?
서버 메모리가 1mb여도 100GB 짜리 동영상을 전송을 해줄 수가 있는겁니다.스트림 방식이 메모리 관리면에서 엄청 효율적이죠?
이번엔 읽는거 말고 쓰는 것도 보여드리겠습니다.
3.13.4 파일 쓰는 스트림 사용하기
나중에 대용량 파일 읽는 것도 실제로 보여드리도록 하겠습니다.
-
fs.createWriteStream
- createWriteStream에 인자로 파일 경로 전달
- write로 chunk 입력, end로 스트림 종료
-
스트림 종료시 finish 이벤트 발생
// createWriteStream.js const fs = require("fs"); // 아까 createReadStream은 data랑 end가 있었죠? // createWriteStream은 write랑 end랑 finish가 있습니다. // finish는 이벤트 리스너이고 write랑 end는 메소드입니다. const writeStream = fs.createWriteStream("./writeme2.txt"); writeStream.on("finish", () => { console.log("파일 쓰기 완료"); }) // 이렇게 write로 파일에 글을 쓸 수 있는데 아래 write 하나당 하나의 버퍼가 됩니다. writeStream.write("이 글을 씁니다.\n"); writeStream.write("한 번 더 씁니다."); writeStream.end(); // 완료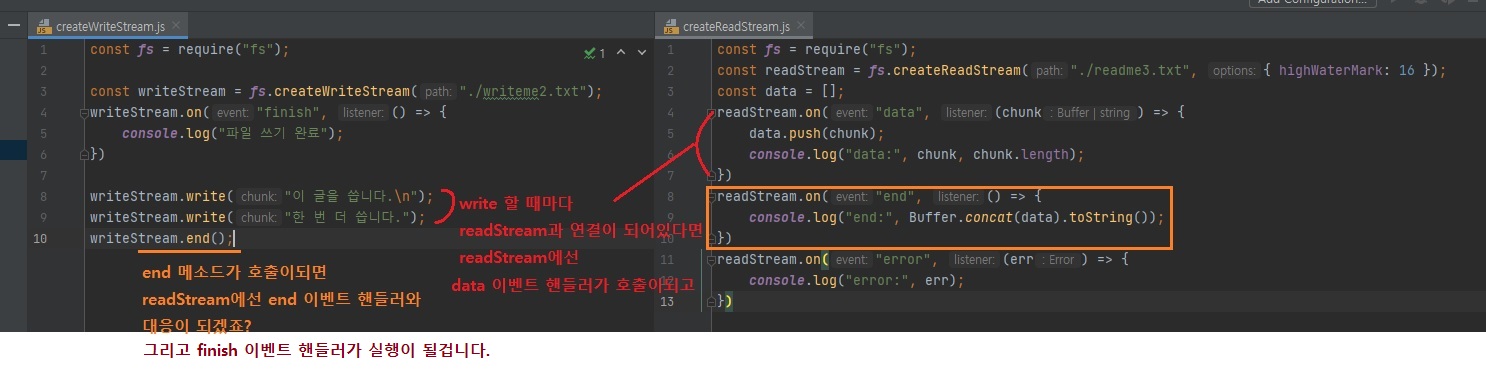
파일을 쓸 때도 1GB짜리 파일을 한 번에 다 쓰려면 서버의 메모리가 1GB가 있어야되는데, 이렇게
.write()메소드로 해놓으면 기본값이 64KB이니깐 메모리가 64KB만 있어도 1GB 짜리 파일을 쓸 수 있다는 것입니다.
쓸 때도 스트림을 활용하면 매우 효율적으로 메모리를 사용할 수 있습니다.
3.14 pipe와 스트림 메모리 효율 확인
스트림의 장점은, 예를 들어 1GB의 파일을 1mb씩 보내주잖아요?
그럼 받을 때도 1mb씩 받아서 나중에 1GB로 복구를 하는 형식이잖아요?
보낼 때도 1mb씩 잘라서 보내고 받을 때도 1mb씩 잘라서 받고, 이런 식이기 때문에, 스트림끼리 pipe()로 연결할 수가 있습니다.
1mb씩 보내면 1mb 데이터를 조작을 할 수가 있거든요?
그래서 그 .pipe() 메소드를 활용하는 것을 보여드리려고 합니다.
-
pipe로 여러 개의 스트림을 이을 수 있음
-
스트림으로 파일을 복사하는 예제
/* readme3.txt */ 저는 조금씩 조금씩 나눠서 전달됩니다. 나눠진 조각을 chunk라고 부릅니다. 안녕하세요. 헬로 노드 헬로 스트림 헬로 버퍼// pipe.js const fs = require("fs"); // 16바이트씩 나눠서 readme3.txt 파일을 읽습니다. const readStream = fs.createReadStream("./readme3.txt", { highWaterMark: 16 }); const writeStream = fs.createWriteStream("./writeme3.txt"); // 위에서 읽은 16바이트의 내용이 아래 pipe 메소드를 통햏 writeStream으로 들어갑니다. // readStream과 writeStream을 연결했으니까 16바이트씩 읽어서보내면 writeStream에서도 16바이트씩 읽어서 받을 겁니다. // 읽어서 받은거를 writeme3.txt로 16바이트씩 쓸겁니다. readStream.pipe(writeStream);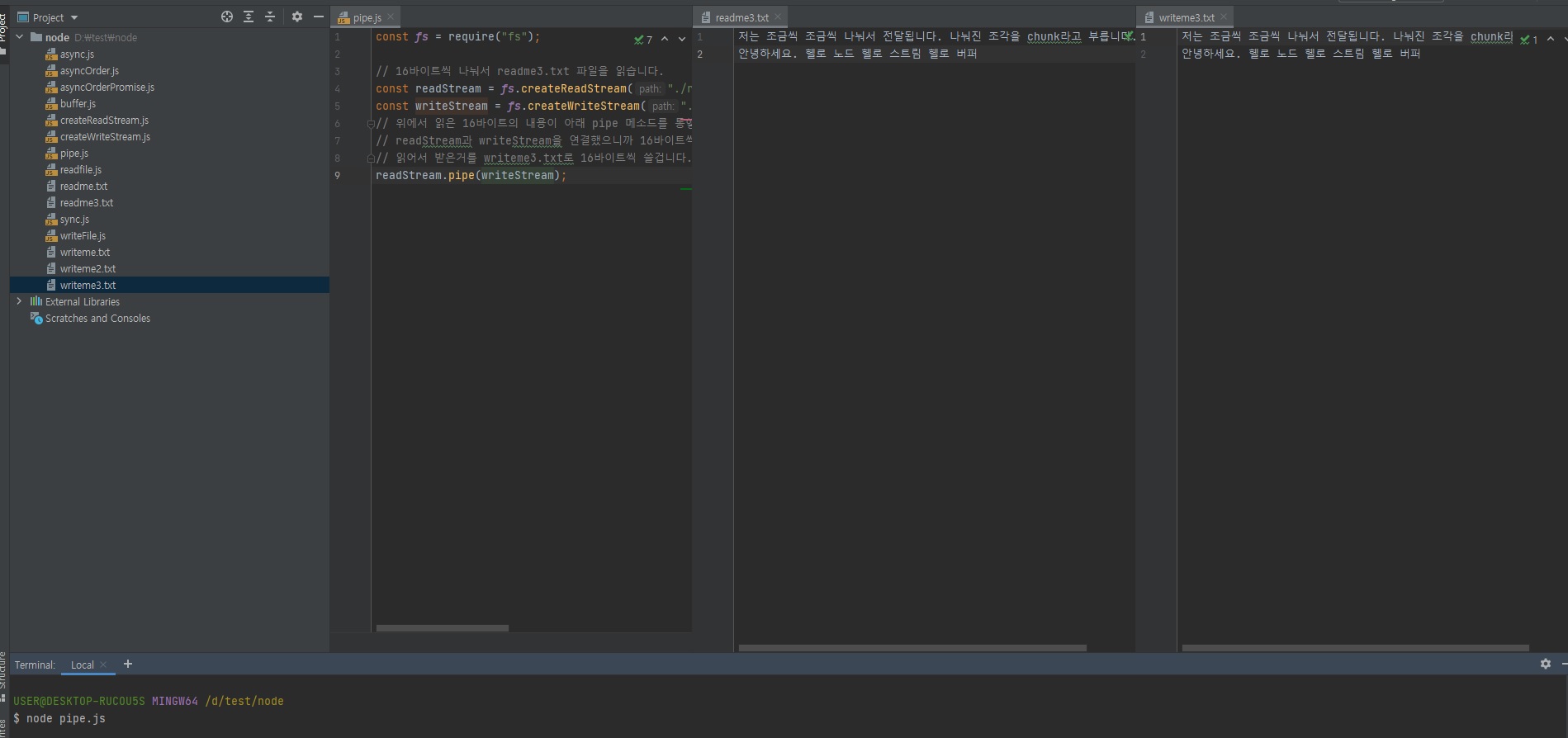
16바이트씩 읽어서 writeme3.txt 파일에 써주는 겁니다.
이렇게 파이핑이 가능합니다.
-
3.14.1 여러 개의 스트림 연결하기
이런 식으로 파이핑이 가능하면서 뭘 더 할 수 있냐면,
-
pipe로 여러 개의 스트림을 이을 수 있음
- 파일을 압축한 후 복사하는 예제
-
압축에는 zlib 내장 모듈 사용(createGzip으로
.gz파일 생성)// pipe.js const fs = require("fs"); // zlib이라는 모듈이 있거든요? // 지금 현재 코드는 파일 복사잖아요? 그런데 zlib을 활용해 파일을 압축해서 쓸 수도 있습니다. const zlib = require("zlib"); const readStream = fs.createReadStream("./readme3.txt", { highWaterMark: 16 }); // 아래가 압축하는 코드 const zlibStream = zlib.createGzip(); const writeStream = fs.createWriteStream("./writeme4.txt"); // 이렇게하면 readme3.txt 파일을 16바이트씩 스트리밍 해주면서 압축을 합니다. // 압축한 것을 writeme4.txt 파일에 작성합니다. readStream.pipe(zlibStream).pipe(writeStream);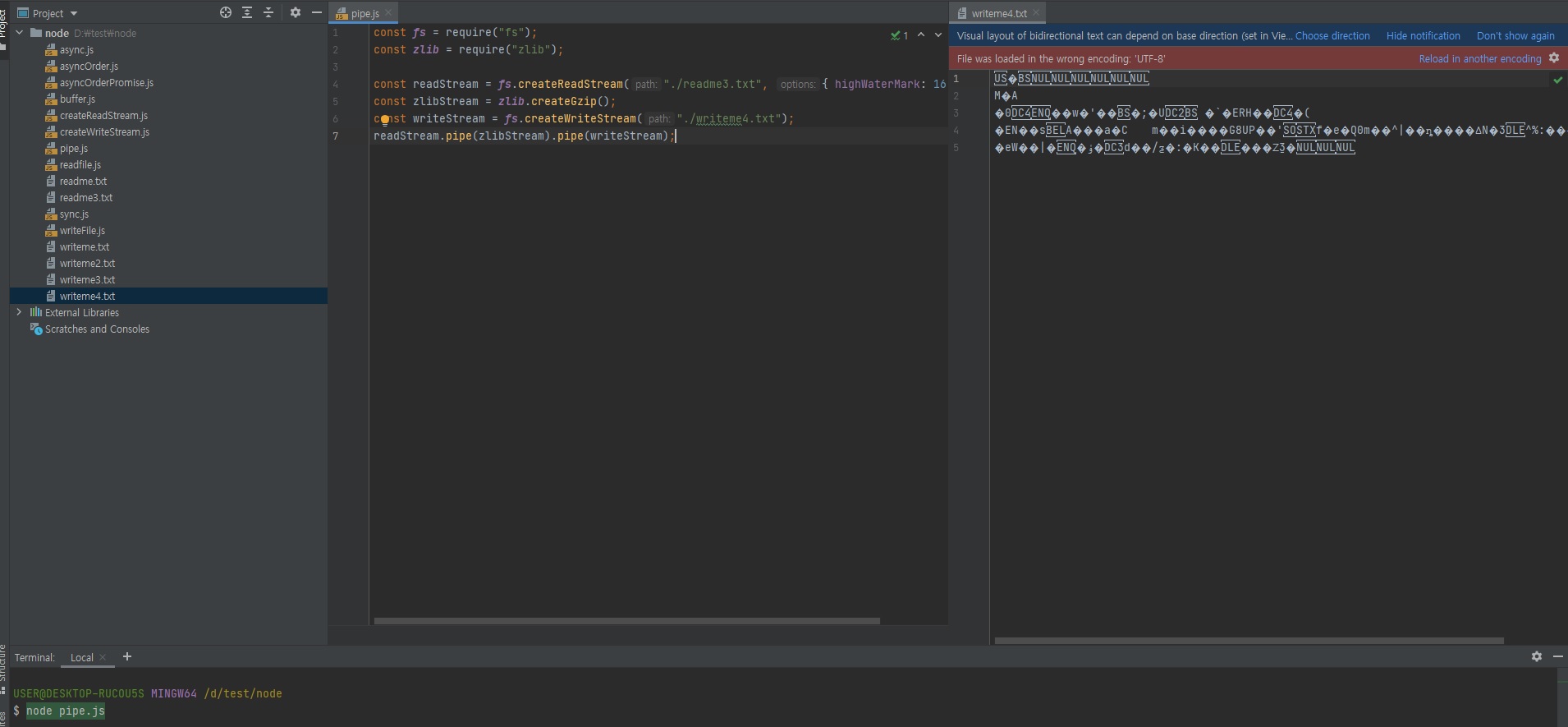
위와 같이 압축되어서 내용이 다 깨져보입니다.
// pipe.js const fs = require("fs"); const zlib = require("zlib"); const readStream = fs.createReadStream("./readme3.txt", { highWaterMark: 16 }); const zlibStream = zlib.createGzip(); // 아래처럼 .gz 확장자로 압축을 할 수가 있습니다. const writeStream = fs.createWriteStream("./writeme4.txt.gz"); readStream.pipe(zlibStream).pipe(writeStream);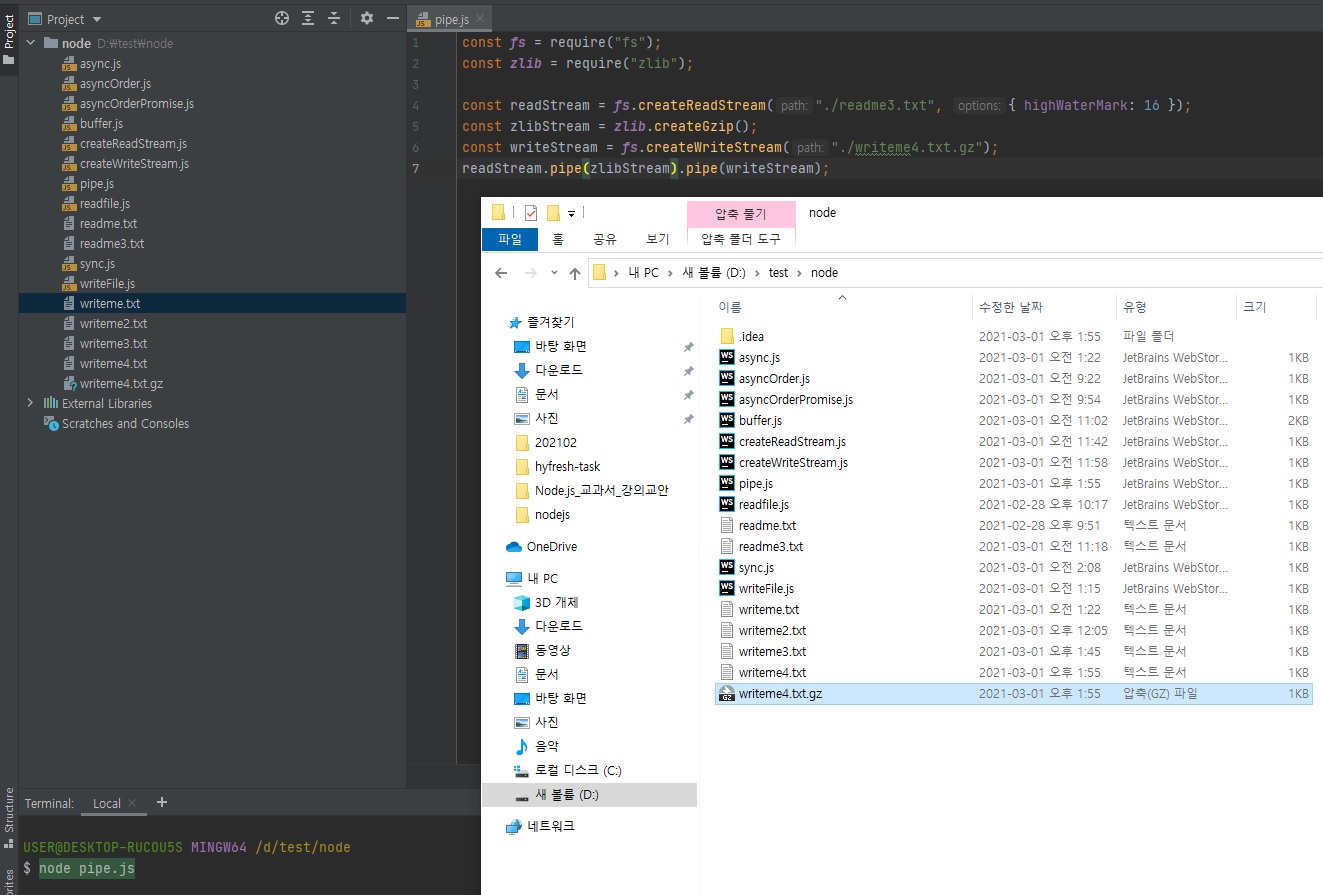
이렇게 스트림을 하면 압축도 할 수 있다는 점, 그리고 다양한
.pipe()끼리 연결을 할 수가 있다는 점.
그런데 이.pipe()가 모든거에 지원되는 것은 아니고 이.pipe()를 지원하는 애들, 스트림을 지원하는 애들끼리만 된다는 것은 알아두셔야합니다.이 강좌에선
.pipe()예제가 더 이상 나오진 않지만 가끔씩 이렇게 사용방법을 파이핑하세요 라고 나오는 애들이 있는데 그럴 때 위와 같이 사용하시면 됩니다.
3.14.2 큰 파일 만들기
제가 이 스트림과 버퍼에서 가장 보여드리고 싶었던 것은 큰 파일을 만드는 거입니다.
-
1GB 정도의 파일을 만들어 봄
-
createWriteStream으로 만들어야 메모리 문제가 생기지 않음
// createBigFile.js const fs = require("fs"); const file = fs.createWriteStream("./big.txt"); // 이렇게하면 용량이 한 1GB 정도 했던거 같아요. for (let i = 0; i <= 10000000; i++) { file.write("안녕하세요. 엄청나게 큰 파일을 만들어 볼 것입니다. 각오 단단히 하세요!\n"); } file.end();
-
3.14.3 메모리 체크하기
위의 코드를 돌리면서 메모리 체크를 해볼겁니다.
-
버퍼 방식과 스트림 방식 메모리 사용량을 비교해보기
// buffer-memory.js const fs = require("fs"); // 아래 코드로 메모리 체크를 할 수 있습니다. console.log("before: ", process.memoryUsage().rss); // 아래 readFileSync 함수는 버퍼 = 파일사이즈 방식으로 파일을 읽습니다. // 그럼 1GB의 big.txt 파일을 읽으려면 1GB의 서버 메모리가 필요하겠죠? const data1 = fs.readFileSync("./big.txt"); fs.writeFileSync("./big2.txt", data1); // 즉 아마 위의 메모리 체크와 아래 메모리 체크는 1GB 정도 차이가 날겁니다. console.log("buffer: ", process.memoryUsage().rss);즉 실제로 1GB 정도가 차이가 나는지 위
buffer-memory.js파일에서 체크해볼 것이고,
아래 코드로 스트림 방식으로 할 경우엔 메모리가 어느 정도가 소비가 되는지 체크해볼 것입니다.// stream-memory.js const fs = require("fs"); console.log("before: ", process.memoryUsage().rss); const readStream = fs.createReadStream("./big.txt"); const writeStream = fs.createWriteStream("./big3.txt"); readStream.pipe(writeStream); readStream.on("end", () => { console.log("stream: ", process.memoryUsage().rss); })제 예상으론 스트림 방식의 기본값이 64KB이니깐 메모리체크할시 차이가 64KB정도?
적어도 1GB 차이는 안 나겠죠?
그것을 한번 확인해보도록 하겠습니다.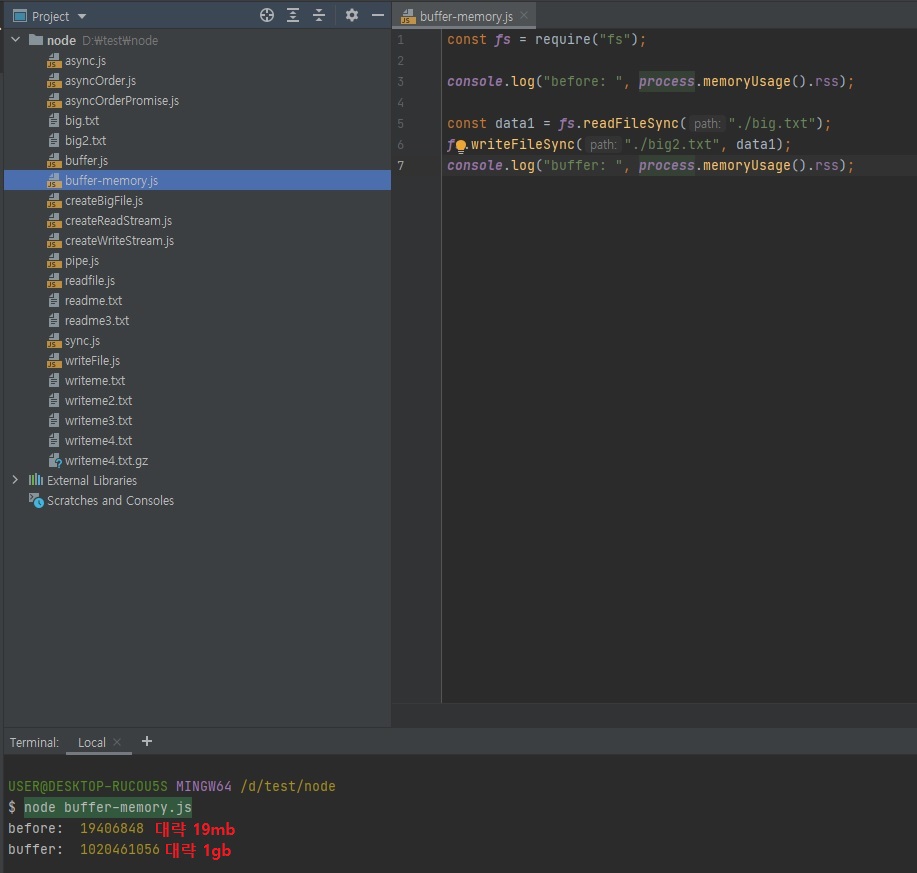
스트림을 사용하지 않았을 때는 메모리 사용량이 19MB 정도인게 1GB로 올랐죠?
이렇게되면 서버가 금방 터지겠죠.
8명만 동시 접속해도 8GB를 사용해야되니까 이러면 서버 메모리가 부족해서 금방 터지는 겁니다.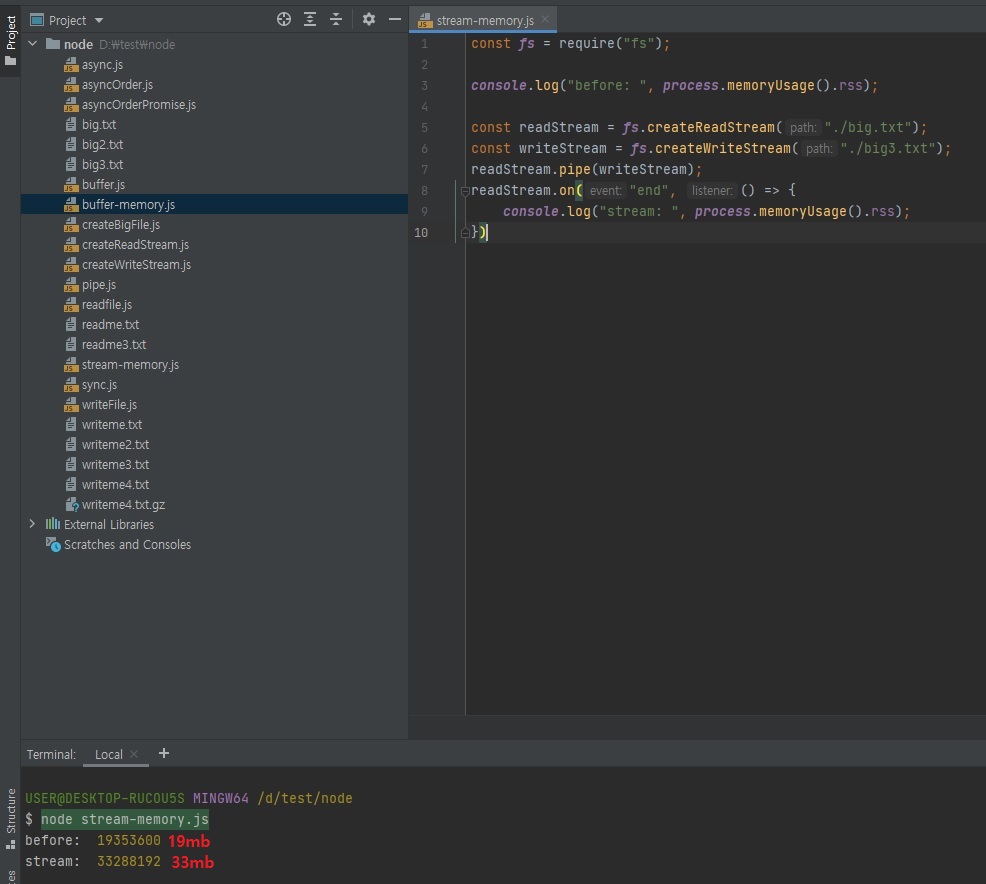
스트림을 사용하면 19MB였던게 33MB로 올랐습니다.
예상처럼 64KB만 사용하는 것은 아니지만 14MB 정도로 1GB 파일을 옮긴거죠?
메모리 관리가 아주 효율적입니다.버퍼 = 파일 사이즈, 이렇게 한 번에 옮기는 방식은 해당 파일 사이즈만큼 메모리를 잡아먹지만 스트림 방식은 1GB 짜리 옮기는데 14MB 메모리 정도밖에 안 들었다.
메모리가 그정도밖에 소요안됐다.
라는 것을 아실 수 있습니다.그리고 14MB도 사실상 스트림보다는 노드 서버를 실행하는데 들어간 메모리, 위 코드에서
readStream,writeStream이런 객체 같은 것들 있죠?
이런 객체같은 것들을 만드는데 들어간 메모리일 가능성이 더 높습니다.
즉, 실제로는 14MB보다도 더 적게 차지했을 겁니다.여튼 이렇게 파일 전송, 작성 등을 할 때는 스트림 방식을 활용하시는 것이 훨씬 좋다는 것!
3.14.4 기타 fs 메소드 1
-
파일 및 폴더 생성
// fsCreate.js const fs = require("fs").promises; const constants = require("fs").constants; // .access 함수를 활용합니다. // 두번 째 인자로 constants.F_OK | constants.W_OK | constants.R_OK 를 넣어줍니다. - 이 두번째 인자를 통해 폴더가 있는지 없는지를 판단할 수 있습니다. fs.access("./folder", constants.F_OK | constants.W_OK | constants.R_OK) .then(() => { // 폴더가 있으면 여기가 실행 return Promise.reject("이미 폴더 있음"); }) .catch((err) => { if (err.code === "ENOENT") { // 폴더가 없으면 여기가 실행 console.log("폴더 없음"); // 에러가 안나고 폴더가 없으면 mkdir 함수로 폴더 생성 return fs.mkdir("./folder"); } // 폴더가 있으면 위의 .then을 거쳐 여기가 실행 // 아래 err엔 위의 "이미 폴더 있음"이 담김 return Promise.reject(err); }) .then(() => { console.log("폴더 만들기 성공"); // 폴더 만들었으면 .open 함수로 두번째 인자에 w를 전달해 파일도 만들 수 있습니다. // 만약 w가 아니라 a가 있으면 기존 파일에다 글자를 추가하는 것도 됩니다. return fs.open("./folder/file.js", "w"); }) .then((fd) => { console.log("빈 파일 만들기 성공", fd); // rename으로 파일 이름을 바꿉니다. fs.rename("./folder/file.js", "./folder/newfile.js"); }) .then(() => { console.log("이름 바꾸기 성공"); }) .catch((err) => { // 폴더가 있으면 위의 .catch를 거쳐 여기가 실행 // 아래 err엔 위의 "이미 폴더 있음"이 담김 console.error(err); })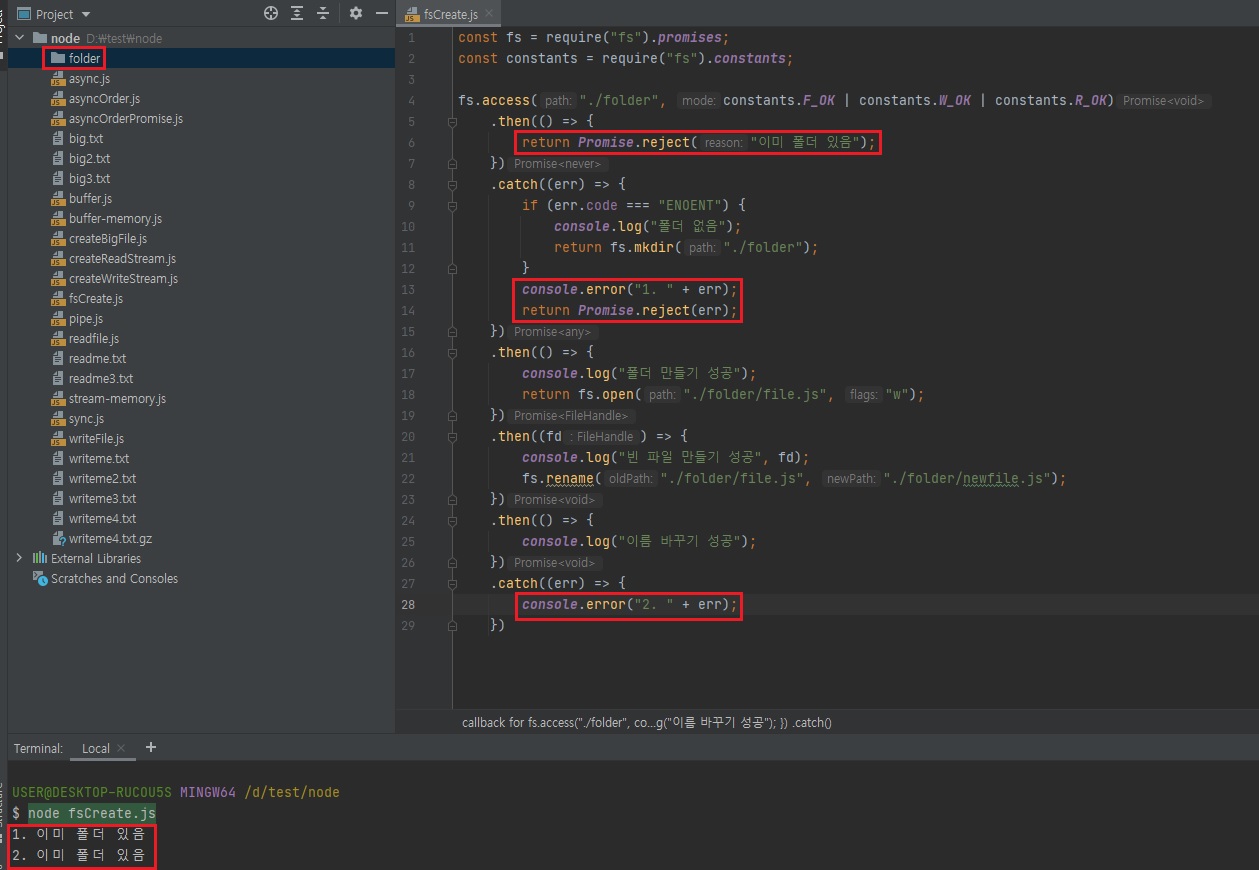
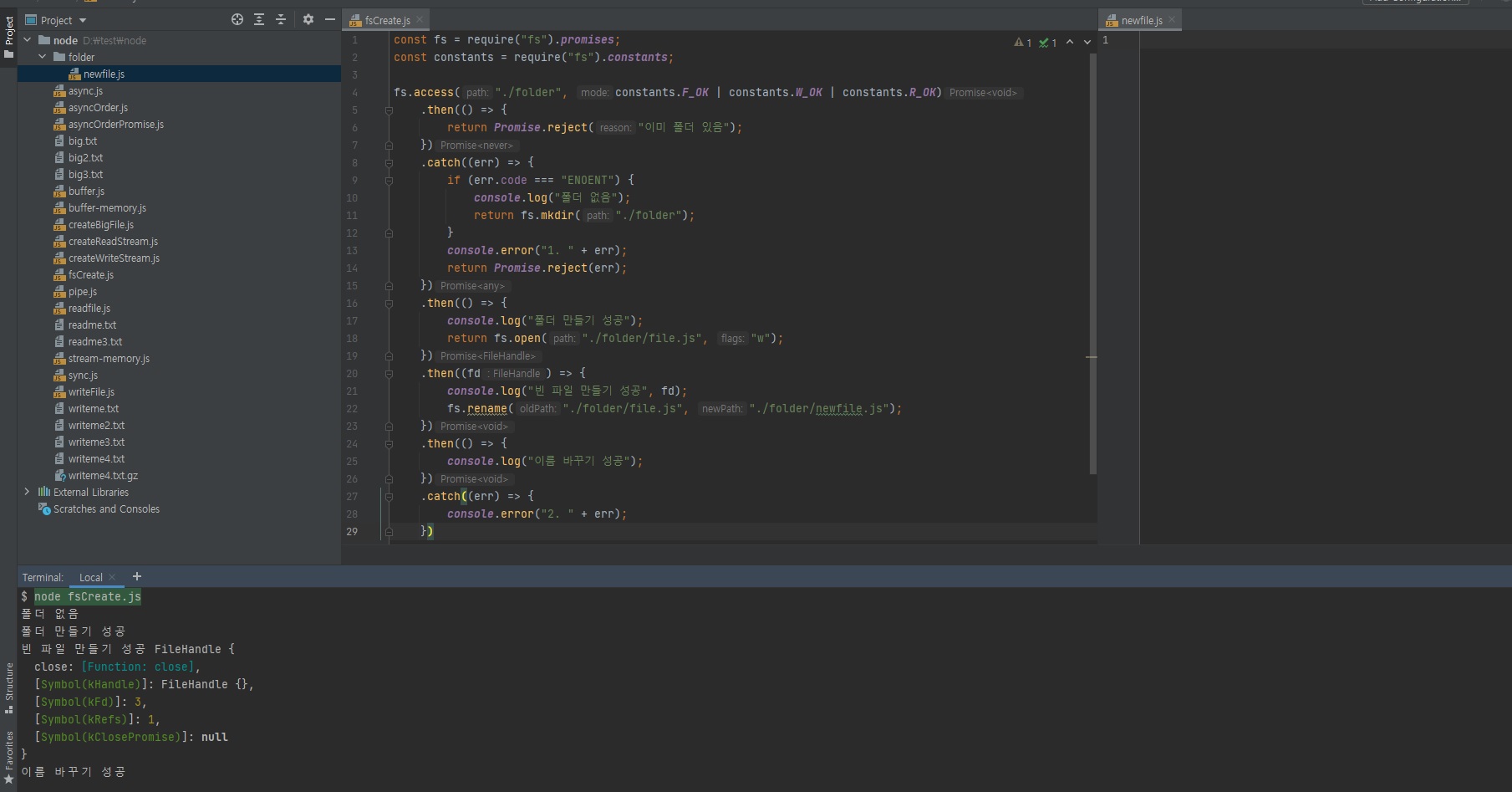
fs에 위와 같은 메소드들도 있다 정도로 보시면 됩니다.
- 위에서 살펴봤던
fs.access말고fs.existsSync도 있습니다.
얘는fs.exists는 없습니다. (그냥fs.exists는 삭제됐습니다.)fs.existsSync로 파일이 존재하는지 안하는지 찾아보는 방법도 있고 fs.stat이런 것도 있는데 해당 파일이 폴더인지 아니면 파일인지 Symbolic Link인지 바로가기인지 이런거를 알아낼 수도 있습니다.fs.appendFile같은 경우는 기존 파일이 있으면 그 파일에다 내용을 더 추가하는 것이고fs.chmod(path, mode, callback): 권한 바꾸는 함수fs.f~,fs.l~: 함수 앞에 f나 l 붙는 것들은 조금 다른 기능을 하는 것들
파일을 조작하는 함수는 엄청 많습니다.
공식문서를 항상 참고하시는 것이 좋습니다.
3.14.5 기타 fs 메소드 2
-
파일 및 폴더 생성, 삭제
-
fs.access(경로, 옵션, 콜백): 폴더나 파일에 접근할 수 있는지 체크합니다.
두번째 인자로 상수들을 넣었습니다.
F_OK는 파일 존재 여부,R_OK는 읽기 권한 여부,W_OK는 쓰기 권한 여부를 체크합니다.
파일/폴더나 권한이 없다면 에러가 발생하는데, 파일/폴더가 없을 때의 에러 코드는ENOENT입니다. -
fs.mkdir(경로, 콜백): 폴더를 만드는 메소드입니다.
이미 폴더가 있따면 에러가 발생하므로access()메소드를 호출해서 확인하는 것이 중요합니다. -
fs.open(경로, 옵션, 콜백): 파일의 아이디(fd 변수)를 가져오는 메소드입니다.
파일이 없다면 파일은 생성한 뒤 그 아이디를 가져옵니다.
가져온 아이디를 사용해fs.read()나fs.write()로 읽거나 쓸 수 있습니다.
두번째 인자로 어떤 동작을 할 것인지 설정할 수 있습니다.
쓰려면w, 읽으려면r, 기존 파일에 추가하려면a입니다.
예제에서는w로 설정했으므로 파일이 없을 때 새로 만들 수 있었습니다.
r이었다면 에러가 발생하였을 것입니다. -
fs.rename(기존 경로, 새 경로, 콜백): 파일의 이름을 바꾸는 메소드입니다.
기존 파일 위치와 새로운 파일 위치를 적어주면 됩니다.
반드시 같은 폴더를 지정할 필요는 없으므로 잘라내기 같은 기능을 할 수도 있습니다.
-
3.14.6 폴더 내용 확인 및 삭제
-
fs.readdir(경로, 콜백): 폴더 안의 내용물을 확인할 수 있습니다.
배열 안에 내부 파일과 폴더명이 나옵니다.
아까 위에서dir명령어를 터미널 창에 입력했었죠?
그게 바로fs.readdir()입니다. -
fs.unlink(경로, 콜백): 파일을 지울 수 있습니다.
파일이 없다면 에러가 발생하므로 먼저 파일이 있는지를 꼭 확인해야 합니다.
delete가 아니라unlink입니다. -
fs.rmdir(경로, 콜백): 폴더를 지울 수 있습니다.
폴더 안에 파일이 있다면 에러가 발생하므로 먼저 내부 파일을 모두 지우고 호출해야 합니다.
파일 삭제와 폴더 삭제 명령어가 다릅니다.// fsDelete.js const fs = require("fs").promises; fs.readdir("./folder") .then((dir) => { console.log("폴더 내용 확인", dir); return fs.unlink("./folder/newFile.js"); }) .then(() => { console.log("파일 삭제 성공"); return fs.rmdir("./folder"); }) .then(() => { console.log("폴더 삭제 성공"); }) .catch((err) => { console.error(err); })
3.14.7 기타 fs 메소드 3
-
파일을 복사하는 방법
// copyFile.js const fs = require("fs").promises; fs.copyFile("readme4.txt", "writeme4.txt") .then(() => { console.log("복사 완료"); }) .catch((error) => { console.error(error); })앞서
createReadStream이랑createWriteStream이랑 연결하면 파일 복사가 됐었죠?
그렇게 할 수도 있지만, 이 기능을 아예fs에서 만들어줬습니다.copyFile그런데
createReadStream,createWriteStream을 활용해 복사하는 것의 장점도 있죠?
어떨 때 장점이 있죠?
그 사이에zlib같은 모듈을 활용해pipe()로 스트림을 연결해 압축하고 그랬잖아요?
그래서 스트림 끼리 연결하면 더 다양한 작업을 할 수 있다 - 이런 장점도 있다는 것.
3.14.8 기타 fs 메소드 4
-
파일을 감시하는 방법(변경 사항 발생 시 이벤트 호출)
// watch.js const fs = require("fs"); fs.watch("./target.txt", (eventType, filename) => { console.log(eventType, filename); })
파일을 감시하는 방법이라고 해서
fs.watch()그리고 파일을target.txt로 설정해두면target.txt가 바뀔 때, 누군가가 이 파일을 수정하거나 그럴 때 위 코드의 콜백함수가 실행이 됩니다.
내용물을 수정하면 위와 같이 change 이벤트 타입이 발생하고 파일명 변경 또는 삭제하면 rename 이벤트 타입이 발생하고..
3.15 스레드풀과 커스텀 이벤트
-
fs,crypto,zlib모듈의 메소드를 실행할 때는 백그라운드에서 동시에 실행됨
위 모듈의 메소드들은 어느정도 백그라운드에서 동시에 돌아간다는 것을 보여드렸었잖아요?
그래서 동기/비동기로 해서 순서도 맞추고 그런 것들을 보여드렸었는데
그럼 백그라운드에서 동시에 돌아가면 몇개까지 동시에 돌아갈까? 그런 것들이 궁금하실 수도 있습니다.
그런데 얘네들이 무턱대고 다 백그라운드에서 돌아가는건 아니니깐 공식문서에서 확인을 해보셔야합니다.여튼 백그라운드에서 동시에 몇개가 돌아가냐면 노드에선 기본적으로 4개로 설정되어있습니다.
그걸 저희가 직접 눈으로 확인을 해보겠습니다.-
스레드풀이 동시에 처리해줌
확실히 눈에 보이려면,
crypto같이 복잡한거를 해야 4개씩 눈에 보이거든요?
원래 이 책 초판에는 이 부분을 안 보여드렸었는데 백그라운드에서 무제한으로 돌아간다거나, 아니면 동시에 돌아가지 않는줄 아시는 분들도 많아가지고 제가 이 부분은 강좌에 넣었습니다.아래 코드는 100만번 돌리는 작업이라 상당히 부담스러운 작업입니다.
알고리즘도sha512로 상당히 복잡한 작업이고..
이런 해시화 작업에서 100만번 계산을 한다는 것은 연산량이 꽤 많겠죠?// threadpool.js const crypto = require("crypto"); const pass = "pass"; const salt = "salt"; const start = Date.now(); crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { // 처음 시작 시간에서 끝나는 시간까지의 걸린 시간, 몇 초 걸린지 확인을 할 수 있습니다. console.log("1:", Date.now() - start); }) crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { console.log("2:", Date.now() - start); }) crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { console.log("3:", Date.now() - start); }) crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { console.log("4:", Date.now() - start); }) crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { console.log("5:", Date.now() - start); }) crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { console.log("6:", Date.now() - start); }) crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { console.log("7:", Date.now() - start); }) crypto.pbkdf2(pass, salt, 1_000_000, 128, "sha512", () => { console.log("8:", Date.now() - start); })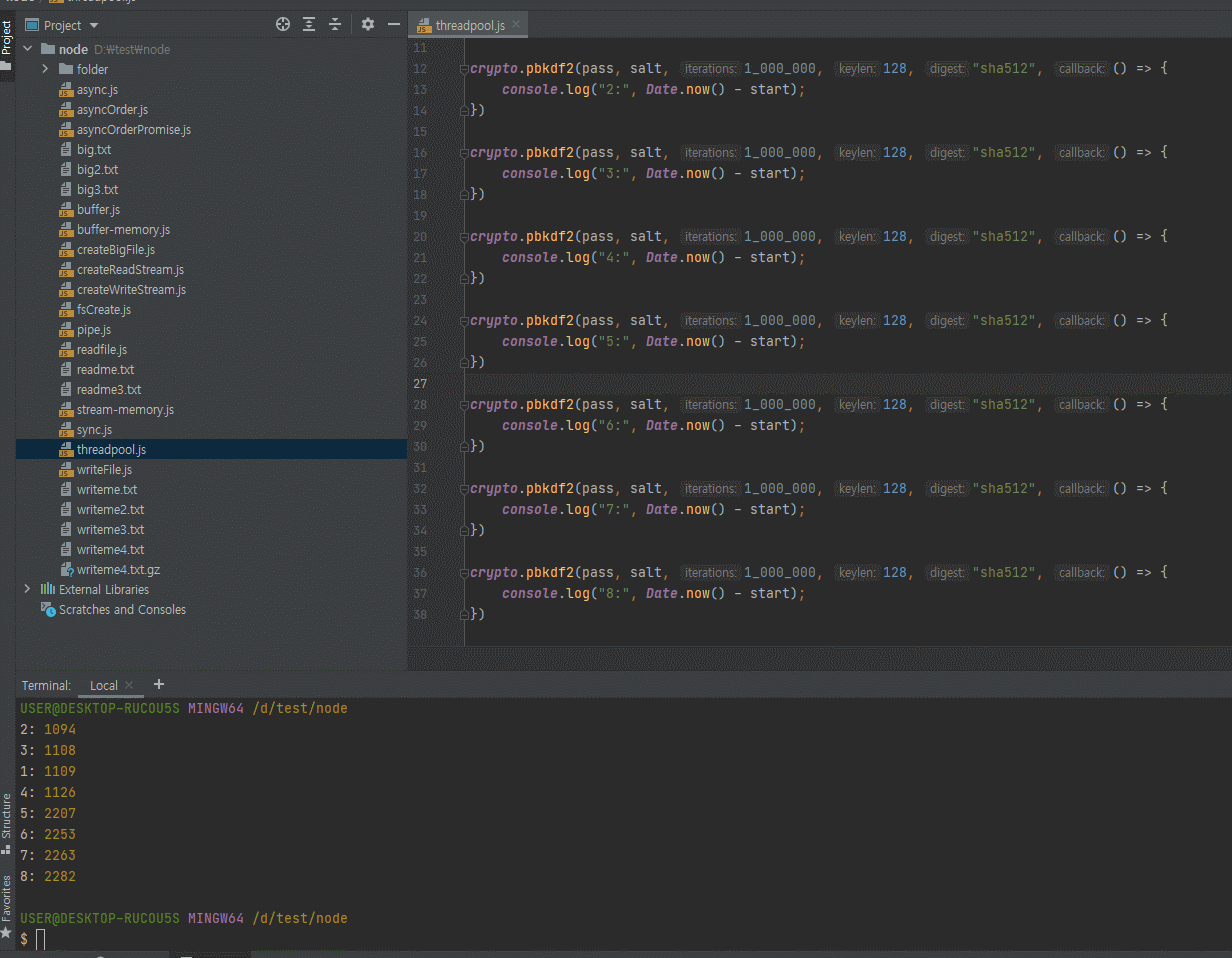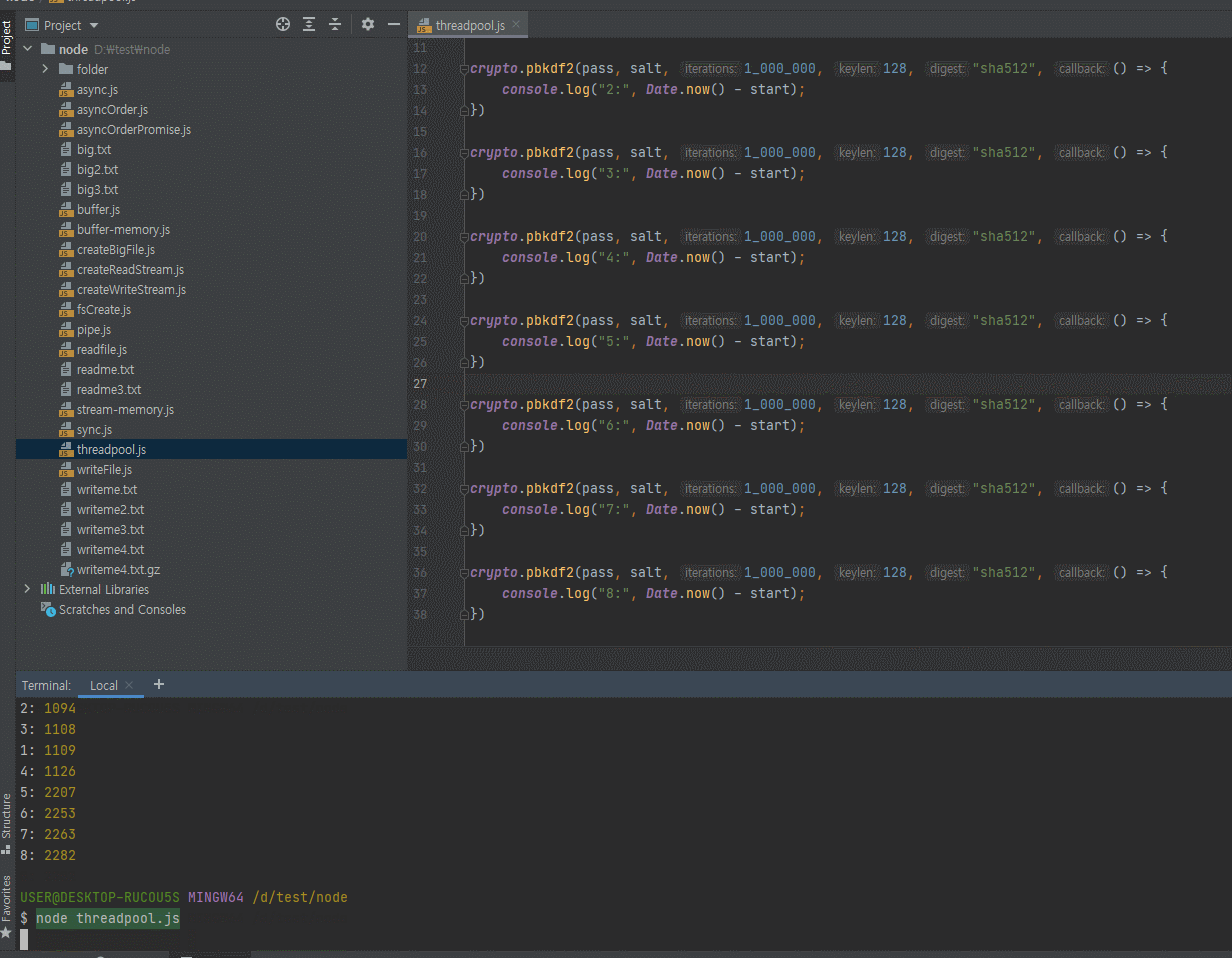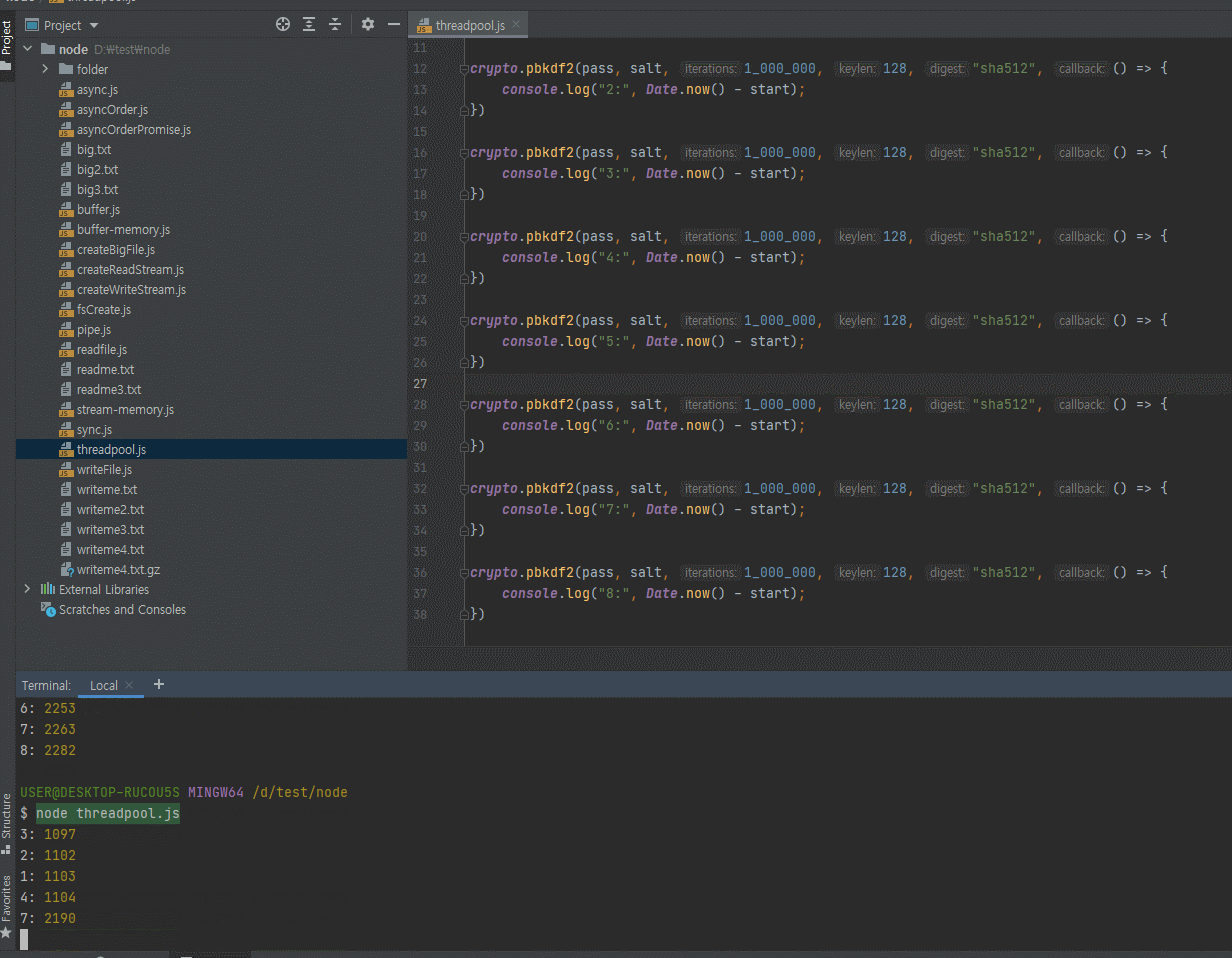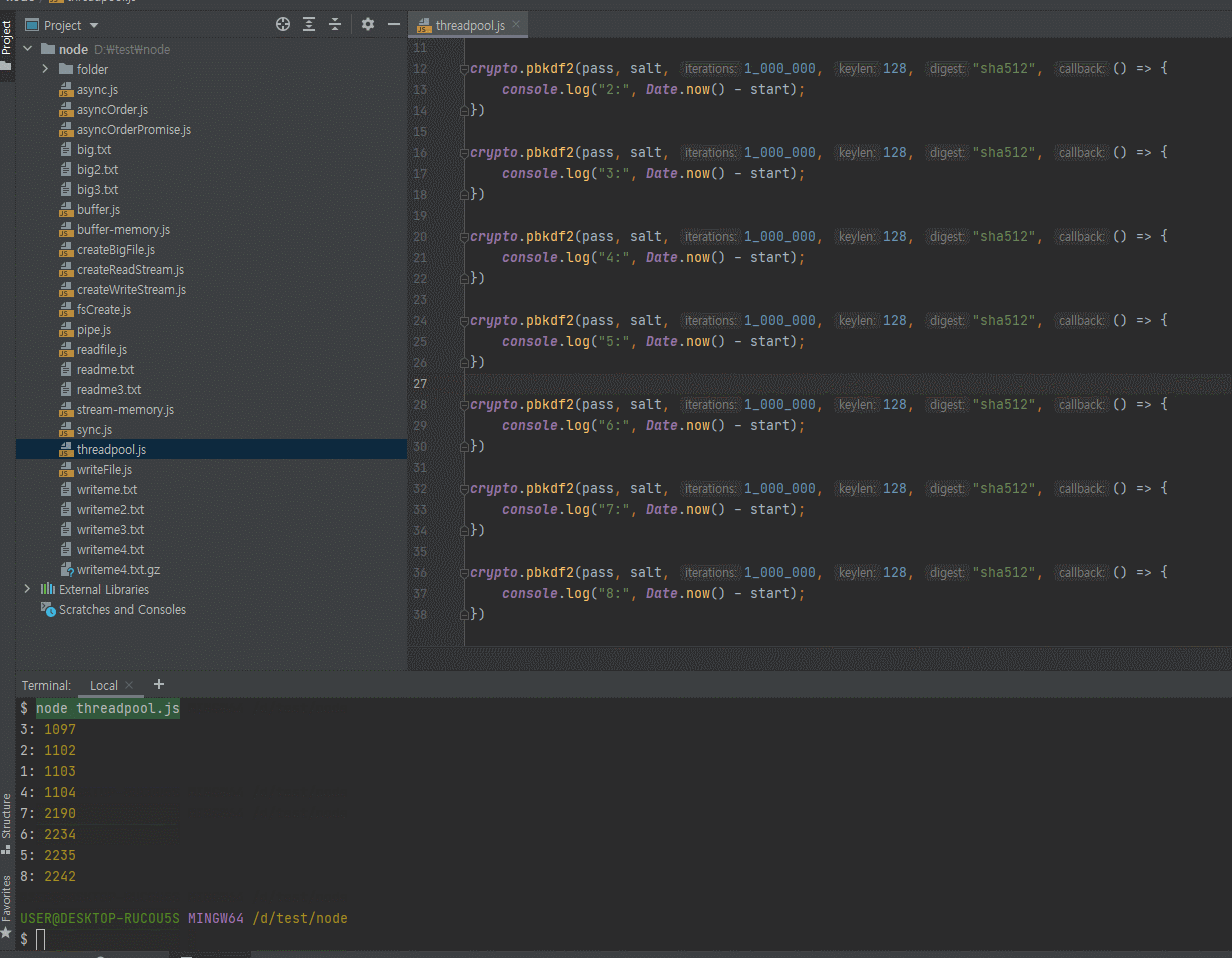
위에 보시면 4개/4개씩 그룹이 나뉘어진 것을 확인하실 수 있습니다.
이는 계속 반복해서 실행하도 처음 "1, 2, 3, 4" 4개의 그룹과 나머지 "5, 6, 7, 8" 4개의 그룹이 나뉘어 실행됩니다.
즉, 기본적으로 노드는 이렇게 백그라운드에서 돌아가는 작업,fs,crypto,zlib이런 것들을 4개씩 동시에 돌린다는 것을 알 수 있는거죠?만약 지금 사용하는 컴퓨터의 코어가 6개라면 지금 4개밖에 사용 안하고 있는거죠.
그래서 이를 좀 비효율적이라고 생각하시면 자기 컴퓨터 코어 갯수에 맞게 늘려주시면 됩니다.
-
3.15.1 UV_THREADPOOL_SIZE
-
스레드풀을 직접 컨트롤할 수는 없지만 개수 조절은 가능
process.env에서UV_THREADPOOL_SIZE를 바꿀 수 있습니다.- 윈도우라면 터미널에
SET UV_THREADPOOL_SIZE=개수 - 맥, 리눅스라면
UV_THREADPOOL_SIZE=개수 -
이전 예제를 스레드풀 개수를 바꾼 뒤 재실행해보기

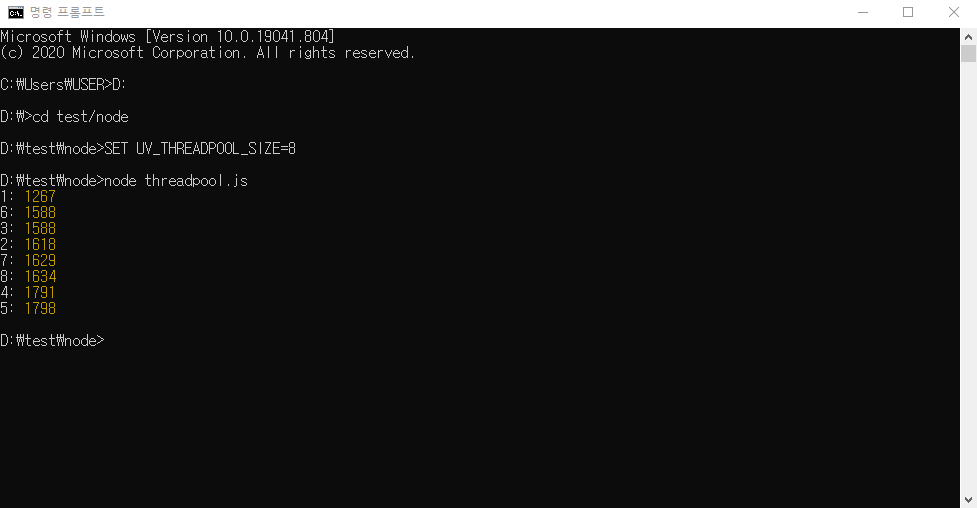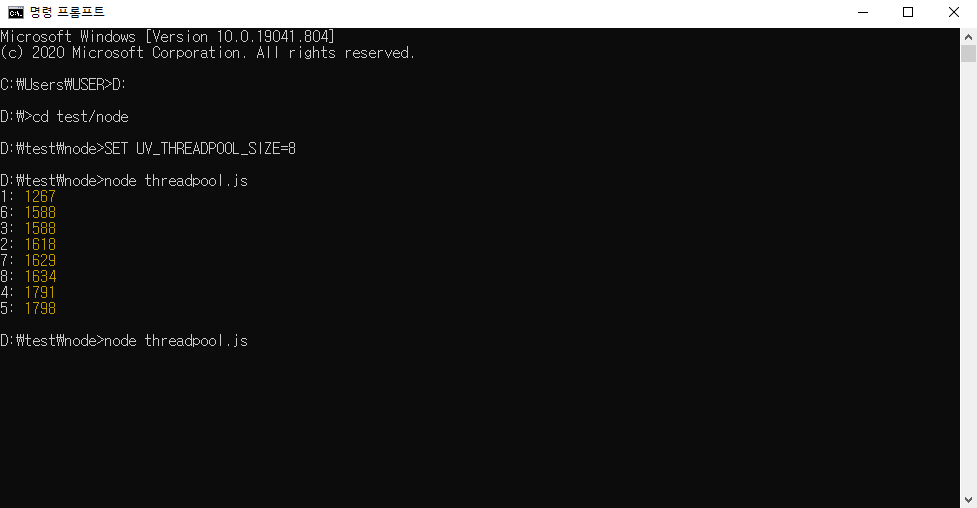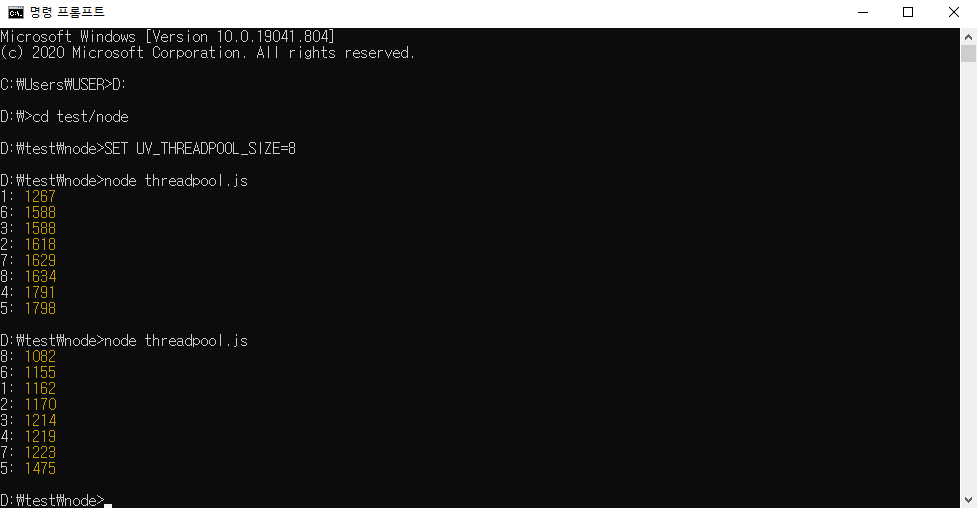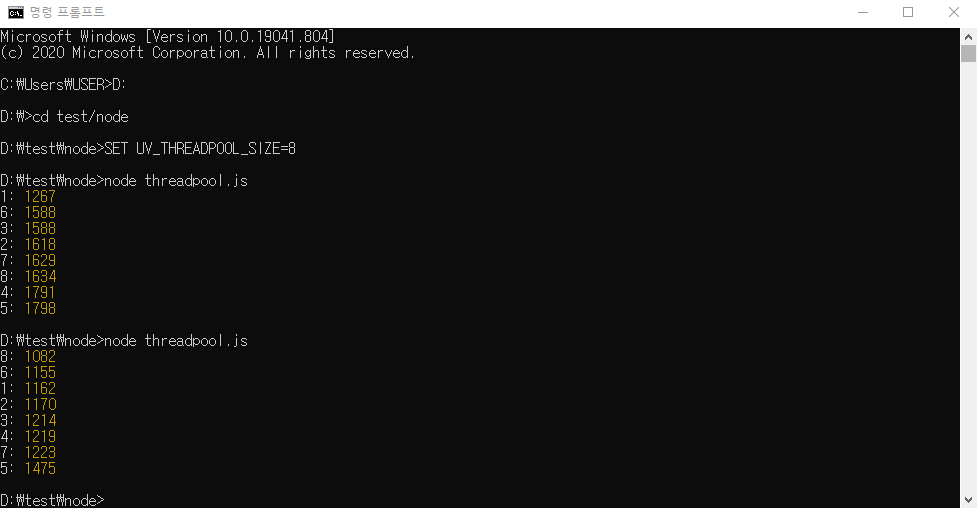
SET UV_THREADPOOL_SIZE=개수명령어가 git bash에선 동작을 안하길래cmd창을 열어 실행했습니다.
위와 같이 8개가 한 그룹으로 실행되는 것을 보실 수 있습니다.
즉,UV_THREADPOOL_SIZE를 자기 컴퓨터에 맞게 적절하게 수정해보시는게 중요합니다.제가
worker_threads할 때도 Worker 갯수를 조절을 했었잖아요?
그거와 마찬가지로UV_THREADPOOL_SIZE도 자기 컴퓨터 사양에 맞게, 코어 갯수에 맞게 조절을 하셔야 효율적으로 동시작업을 하실 수 있습니다.
- 윈도우라면 터미널에
3.15.2 이벤트 이해하기
이거는 알아두면 편리합니다.
브라우저 쪽 자바스크립트 하셨던 분들은 "click"하면 어떤 함수가 실행되어야하는지 콜백 함수를 등록해놓는 것처럼 아래와 같이 이벤트를 등록할 수 있습니다.
3.15.2.1 커스텀 이벤트 예제
이렇게 이벤트를 등록해놓으면 나중에 그 이벤트를 실행했을 때, 어떤 특정한 동작을 할 수가 있죠?
아래 이벤트 패턴으로 여러 파일간의 동작을 공유할 수가 있거든요?
예를 들어 A라는 파일에다가 event1이란걸 심어놓고 B라는 파일에서 event1을 호출하면 A 파일의 event1 콜백함수가 실행돼고..
이렇게 여러 파일간 서로를 호출하는 겁니다.
// event.js
const EventEmitter = require("events");
// 나만의 커스텀 이벤트 생성
// 이벤트를 여러개 만들 수도 있습니다. new EventEmitter() 이걸 계속 실행시키면 이벤트 묶음들이 여러개가 생기겠죠?
// 예제에선 하나만 생성했습니다.
const myEvent = new EventEmitter();
// addListener, on 둘 다 같은 것
myEvent.addListener("event1", () => {
console.log("이벤트 1");
})
myEvent.addListener("event1", () => {
console.log("이벤트 1 두번째");
})
// event2라는 같은 이벤트에 콜백함수를 여러개 추가
myEvent.on("event2", () => {
console.log("이벤트 2");
})
myEvent.on("event2", () => {
console.log("이벤트 2 추가");
})
myEvent.once("event3", () => {
console.log("이벤트 3");
}); // 한 번만 실행됨
myEvent.emit("event1"); // 이벤트 호출
myEvent.emit("event1"); // 이벤트 호출
myEvent.emit("event2"); // 이벤트 호출
myEvent.emit("event3"); // 이벤트 호출
myEvent.emit("event3"); // 실행 안됨
myEvent.on("event4", () => {
console.log("이벤트 4");
})
// removeAllListeners는 이벤트 리스너에 등록된 모든 콜백함수를 제거합니다.
// 이벤트 리스너에 등록된 모든 콜백함수가 아닌 특정 콜백함수만 지우고 싶다고 한다면 removeListener
myEvent.removeAllListeners("event4");
myEvent.emit("event4"); // 실행 안됨
const listener = () => {
console.log("이벤트 5");
}
myEvent.on("event5", listener);
// removeListener: 이벤트 리스너 콜백함수들 중 특정 콜백함수를 지웁니다.
// 때문에 이때는 그 콜백함수가 무엇인지를 2번째 인자로 넣어줘야합니다.
// 2번째 인자를 안 넣어주시면 어떤걸 지우라는건지 몰라서 못지움
myEvent.removeListener("event5", listener);
myEvent.emit("event5"); // 실행 안됨
console.log(myEvent.listenerCount("event2"));
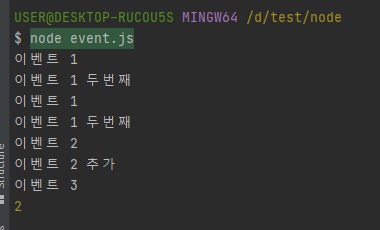
커스텀 이벤트는 잘만 사용하시면 엄청 효율적으로 사용하실 수 있습니다.
여러 이벤트들을 엮어놓으면 하나의 이벤트가 호출되었을 때 그에 따라서 다른 이벤트들을 연계적으로 호출시킬 수도 있고 다양한 파일들간에..
A파일이 어떤 이벤트를 emit(이벤트명)해서 B파일의 이벤트명을 발생시키고 그것의 콜백함수 부분을 호출합니다.
이런식으로 연쇄작용을 할 수 있으니까 커스텀 이벤트는 잘 활용하시면 아주 좋을겁니다.
커스텀 이벤트를 나중에 활용할 수 있으면 또 보여드리는게 좋을텐데 제 강의에선 여기밖에 소개를 안하고 있습니다.
그런데 나중에 WebSocket.. 12장 정도에선 한번 제가 다루는걸로 고민을 해볼게요.
3.15.2.2 이벤트 만들고 호출하기
-
events 모듈로 커스텀 이벤트를 만들 수 있음
- 스트림에 쓰였던
on("data"),on("end")등과 비교 on(이벤트명, 콜백): 이벤트 이름과 이벤트 발생 시의 콜백을 연결해줍니다.
이렇게 연결하는 동작을 이벤트 리스닝이라고 부릅니다.
event2 처럼 이벤트 하나에 이벤트 여러개를 달아줄 수도 있습니다.addListener(이벤트명, 콜백): on과 기능이 같습니다.emit(이벤트명): 이벤트를 호출하는 메소드입니다.
이벤트 이름을 인자로 넣어주면 미리 등록해뒀던 이벤트 콜백이 실행됩니다.once(이벤트명, 콜백): 한 번만 실행되는 이벤트입니다.
myEvent.emit("event3")을 두 번 연속 호출했지만 콜백이 한번만 실행됩니다.removeAllListeners(이벤트명): 이벤트에 연결된 모든 이벤트 리스너를 제거합니다.
event4가 호출되기 전에 리스너를 제거했으므로 event4의 콜백은 호출되지 않습니다.removeListener(이벤트명, 리스너): 이벤트에 연결된 리스너를 하나씩 제거합니다.
역시 event5의 콜백도 호출되지 않습니다.off(이벤트명, 콜백): 노드 10 버전에서 추가된 메소드로removeListener와 기능이 같습니다.listenerCount(이벤트명): 현재 리스너가 몇개 연결되어있는지 확인합니다.
- 스트림에 쓰였던
3.16 에러 처리하기
3장의 마지막이 이 에러(예외) 처리하기인데 상당히 중요한 부분입니다.
노드는 싱글 스레드이기 때문에, 음식점이라고 예를 들었을 때 점원 한명이 지쳐 쓰러지거나 주방장이 지쳐 쓰러지면 서비스가 중단된다고했죠?
그렇기 때문에 에러가 나지 않게, 에러처리에 신경써주셔야 합니다.
그래서 제가 콜백 함수를 처리할 때 if (err) {}로 에러가 났을 시 어떻게 처리할지 적어주고, Promise에서도 항상 catch() 붙여주고 async/await에서도 항상 try {} catch {} 감싸주는 이유가 전부 에러(예외)로 부터 노드 프로세스를 보호하기 위함입니다.
3.16.1 예외 처리
-
예외(Exception): 처리하지 못한 에러
참고로 자바스크립트는 예외랑 에러랑 큰 차이가 없습니다.
다른 언어는 예외(Exception)랑 에러(Error)를 서로 다른 객체로 구분하기도 하는데 자바스크립트는 둘 다 Error라고 생각하시면 됩니다.
에러가 발생했을 때 그 에러를 어떻게 처리하지 못하면 노드 프로세스/스레드가 멈춥니다.- 노드 프로세스/스레드를 멈춤
- 노드는 기본적으로 싱글 스레드라 스레드가 멈춘다는 것은 프로세스가 멈추는 것
- 에러 처리는 필수
3.16.2 try catch 문
-
기본적으로 try catch 문으로 예외를 처리
-
에러가 발생할 만한 곳을 try catch로 감쌈
// error1.js setInterval(() => { console.log("시작"); try { // throw ~ : ~ 이거를 던지는 겁니다. // 아래 코드는 Error 객체를 던지고 있습니다. 이렇게하면 에러가나서 서버를 고장냅니다. throw new Error("서버를 고장내주마!"); } catch (err) { // 위에서 throw한 것을 이 catch 안에서 받습니다. console.error(err); } }, 1000)위와 같이 코드를 작성하면 에러가 실재로
try구문 안에서 발생했지만 전체적으로 보면 아무일도 없었던 겁니다.
try catch문을 넣은거랑 뺀거랑 비교해보시면 아시겠지만 노드에서 에러났을 때try catch가 없다면 바로 에러가 난 시점에서 프로그램은 고장나버리고 맙니다.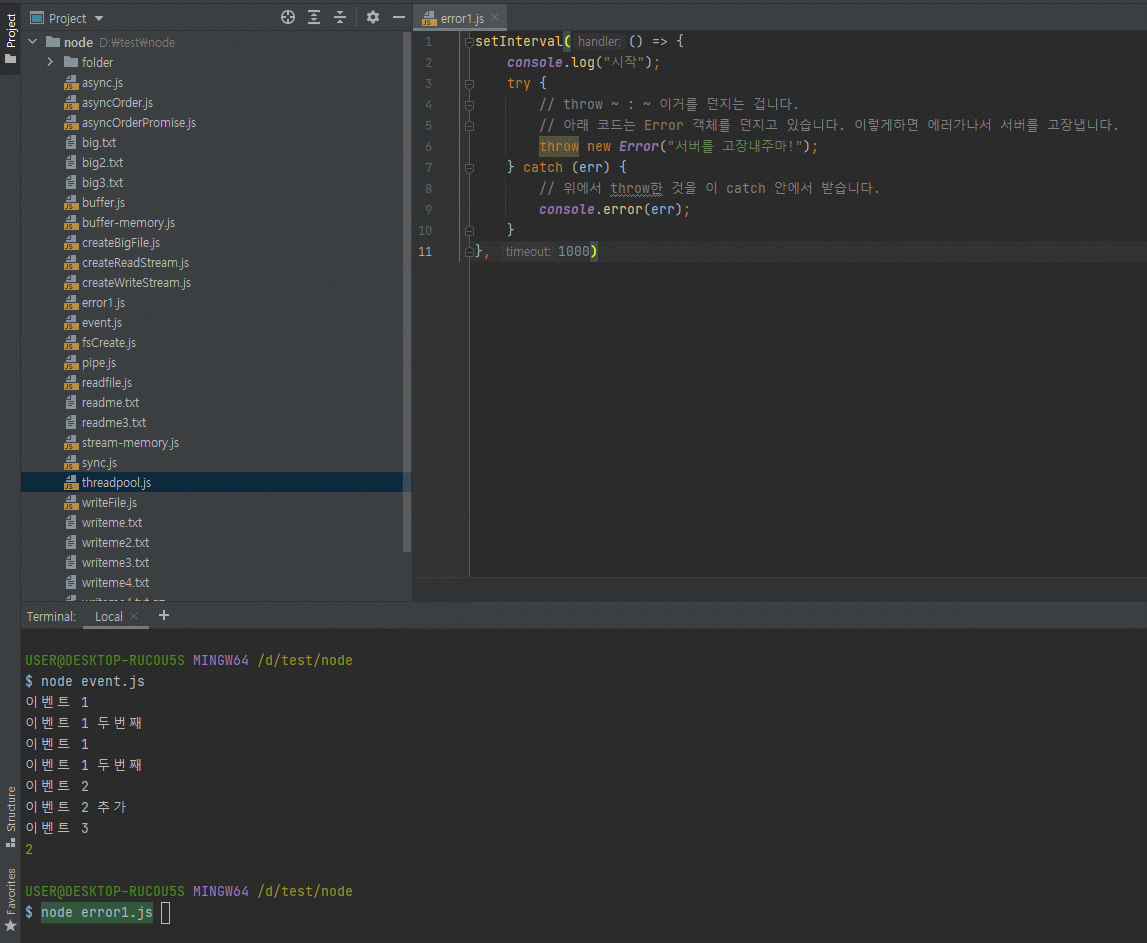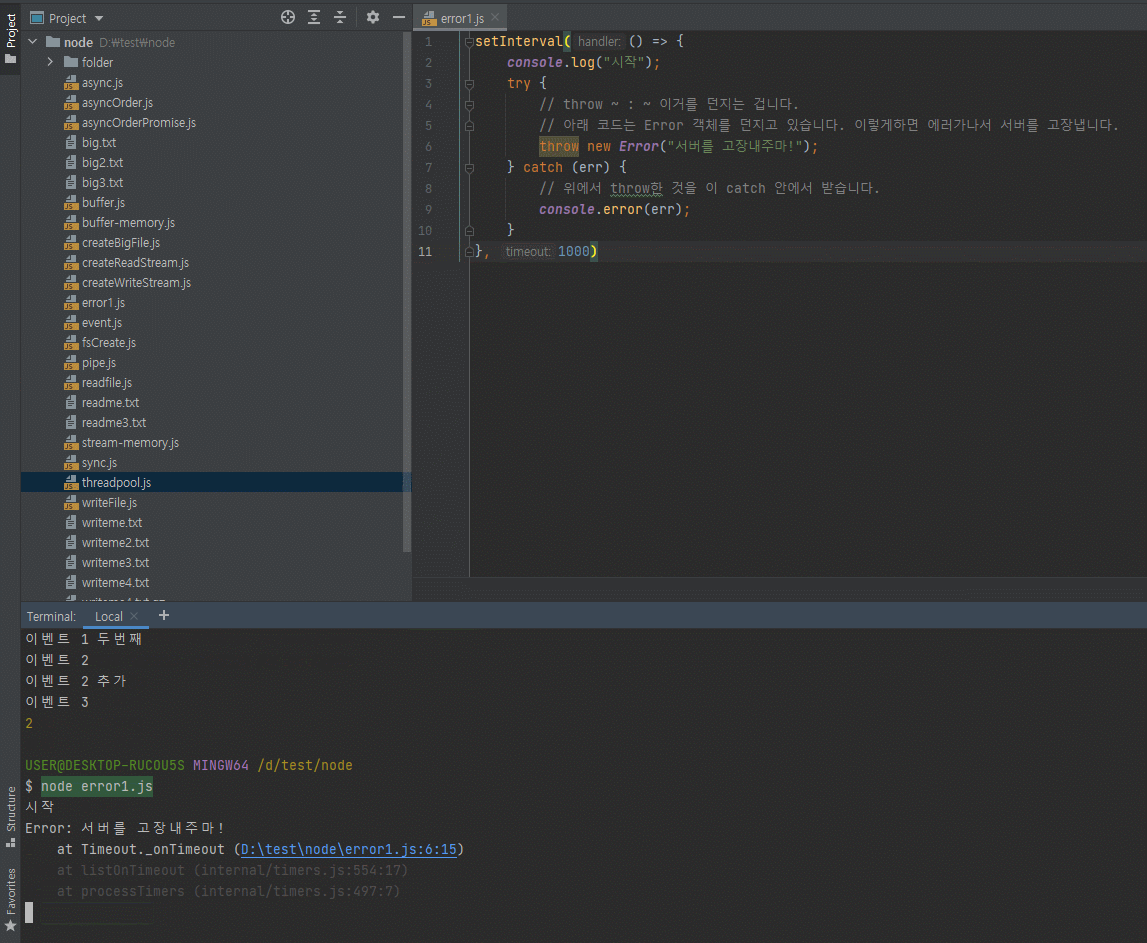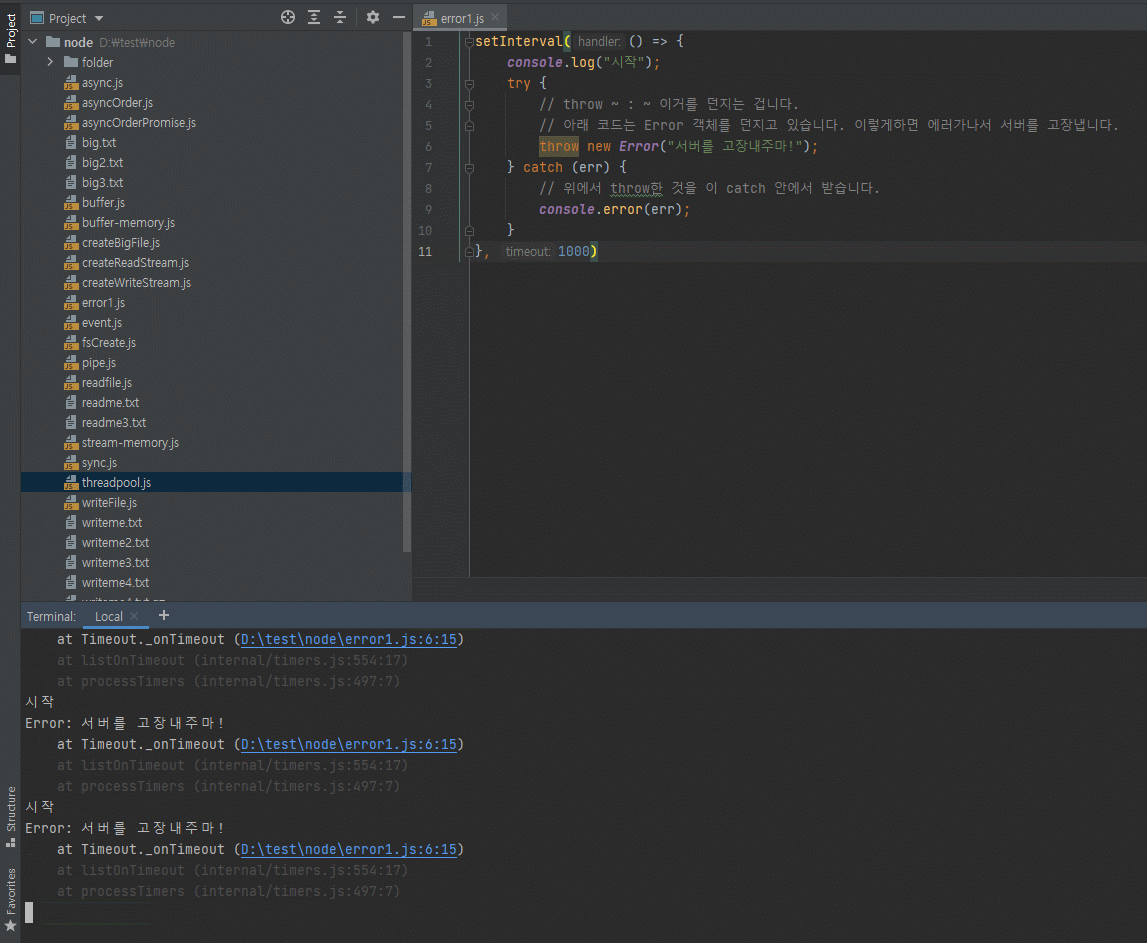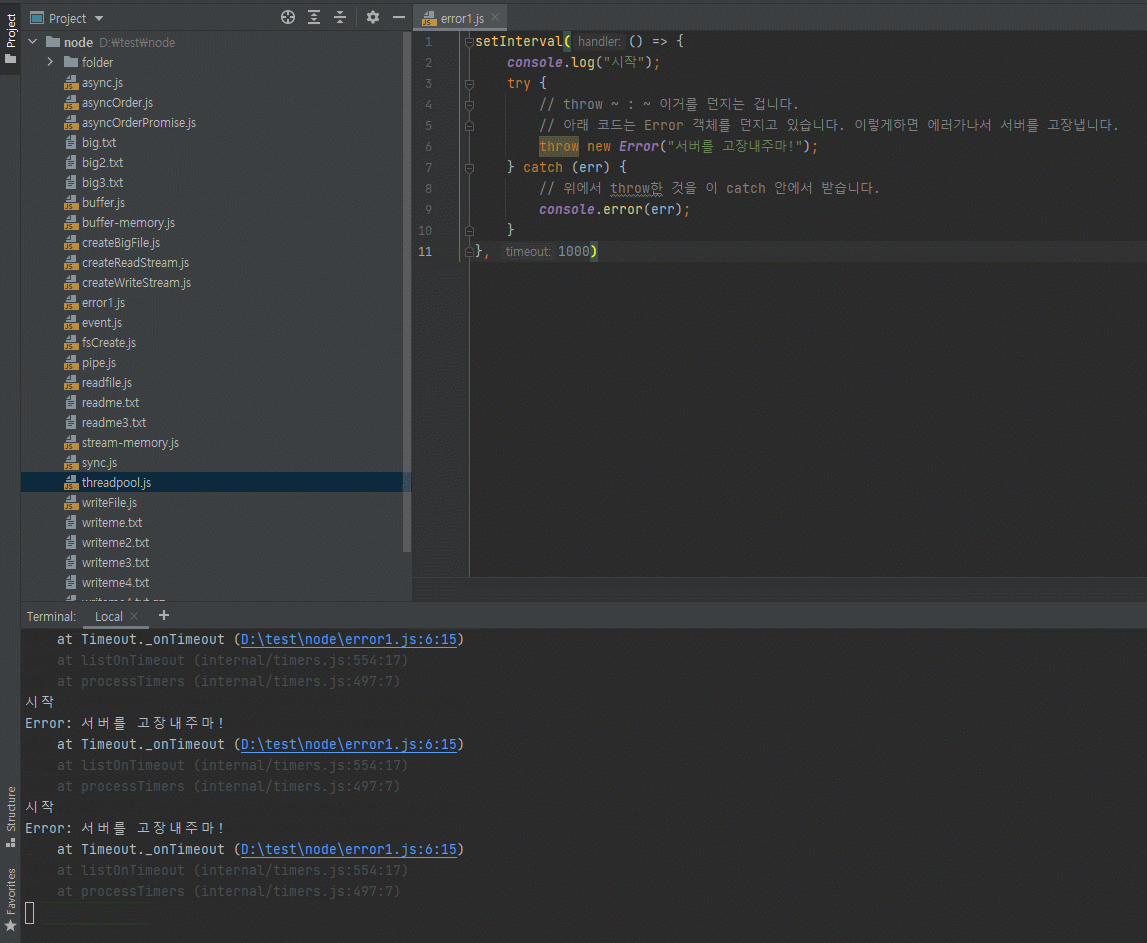
하지만
try catch문으로 감쌌기에 에러가 나도 아무일 없다는 듯이 계속 에러를 콘솔창에 찍어주면서 계속 반복합니다.
여튼 기본적으로 에러가 발생할만한 곳을 위와 같이try catch문으로 감싸주시면 되는데,
모든 코드에다try catch문을 감싸주는 것도 방법이긴 방법인데,
그러면 좀 없어보이거든요?
노드의 에러 발생 원리 이런걸 좀 모르는 거 같아보이기 때문에try catch문으로 감싸야되는 곳과 안감싸도 되는 곳 정도는 구분을 해두시는 게 좋습니다.
-
3.16.3 노드 비동기 메소드의 에러
-
노드 비동기 메소드의 에러는 따로 처리하지 않아도 됨
-
콜백 함수에서 에러 객체 제공
// error2.js const fs = require("fs"); setInterval(() => { // 아래 같은 것들은 따로 try-catch로 안 감싸도 됩니다. fs.unlink("./abcdefg.js", (err) => { // 에러가 발생해도 아래처럼 에러가 발생했구나 하고 넘어갑니다. // 프로세스가 멈추지는 않습니다. 에러가 나도. // 이런 것은 try-catch로 하실 필요는 없고 if (err) { // 그래도 이렇게 콘솔로 에러를 찍어주긴 하잖아요? // 이게 왜 그러냐면 로그에 에러났다는게 표시는 되어야하니깐 나중에 그 로그를 보고 에러를 해결할 수 있겠죠? // 다만 노드 프로세스는 안 망가지고 유지가 됩니다. console.error(err); } }) }, 1000)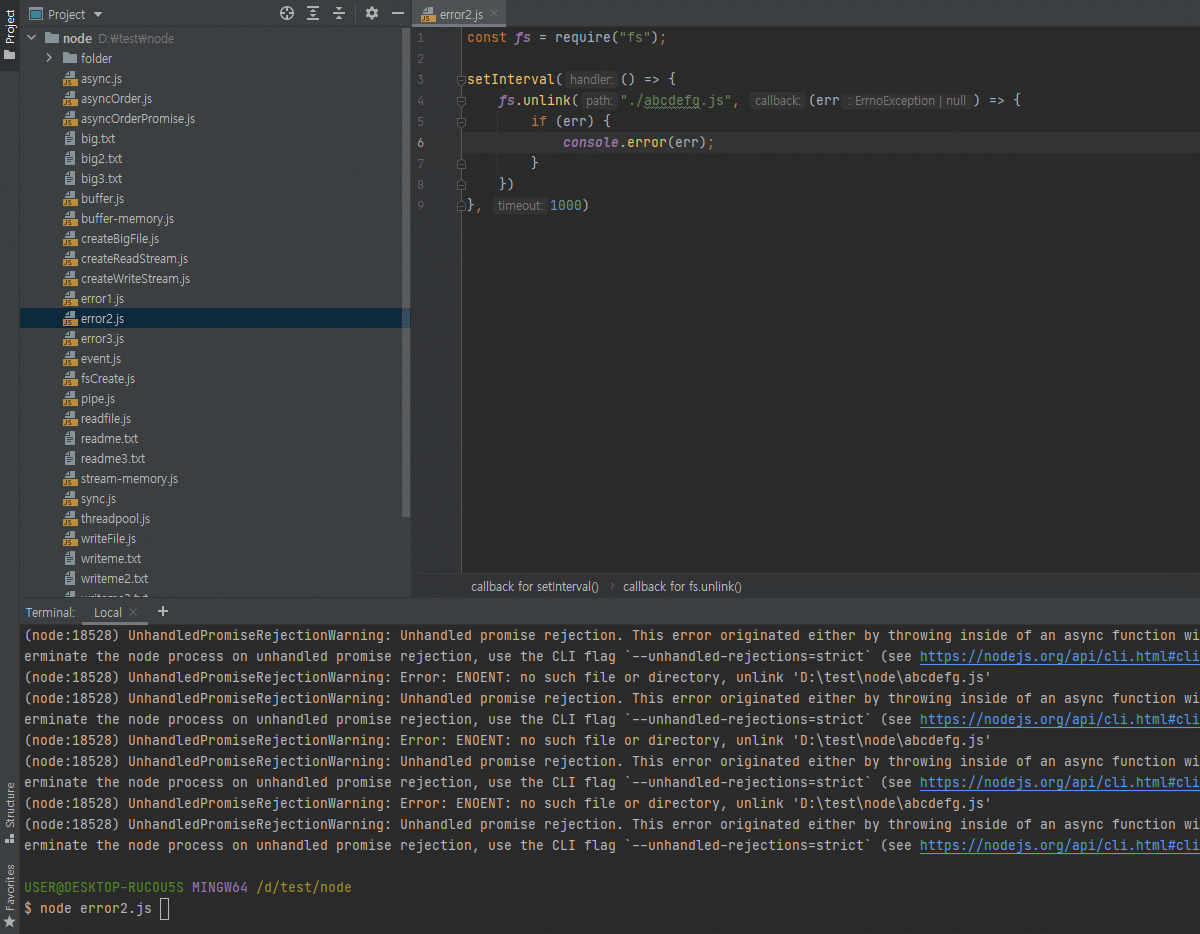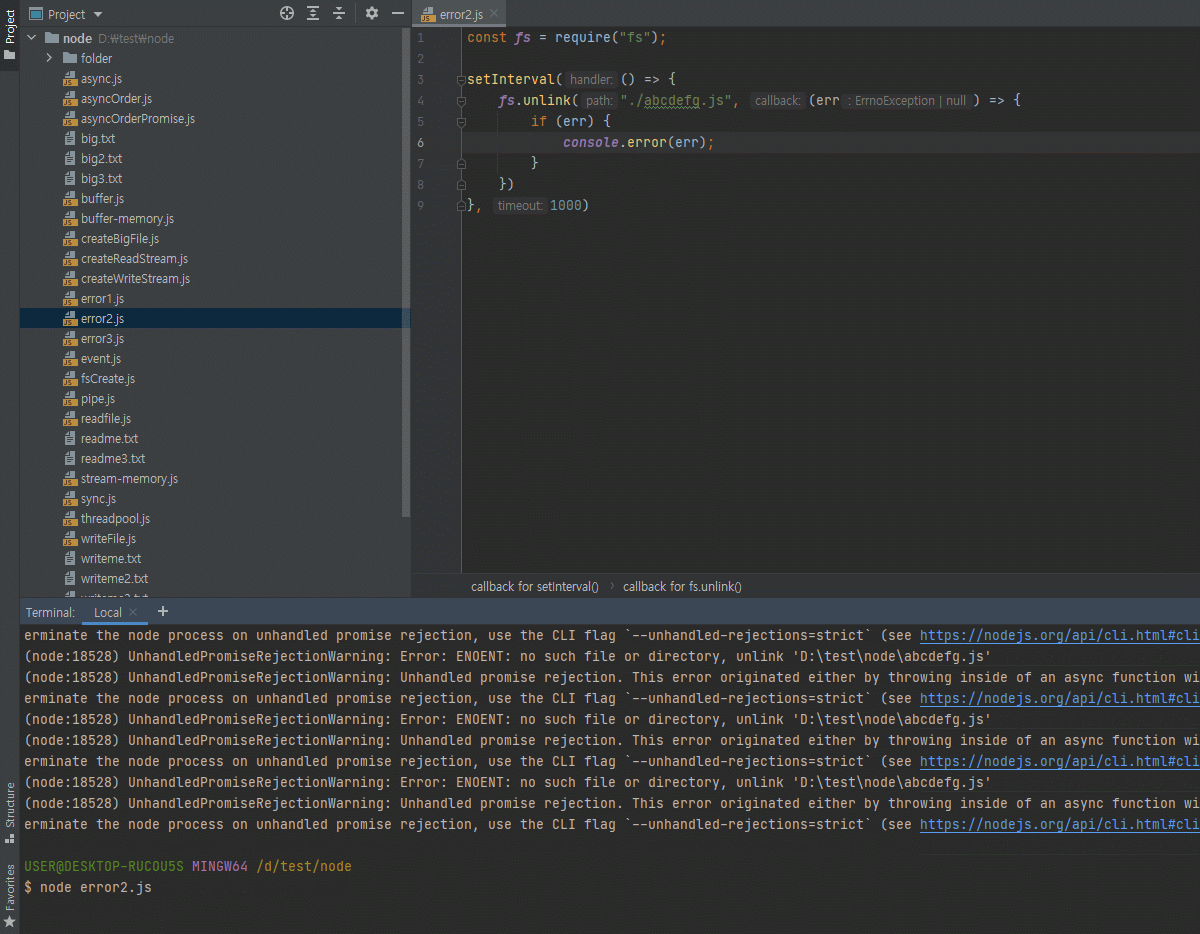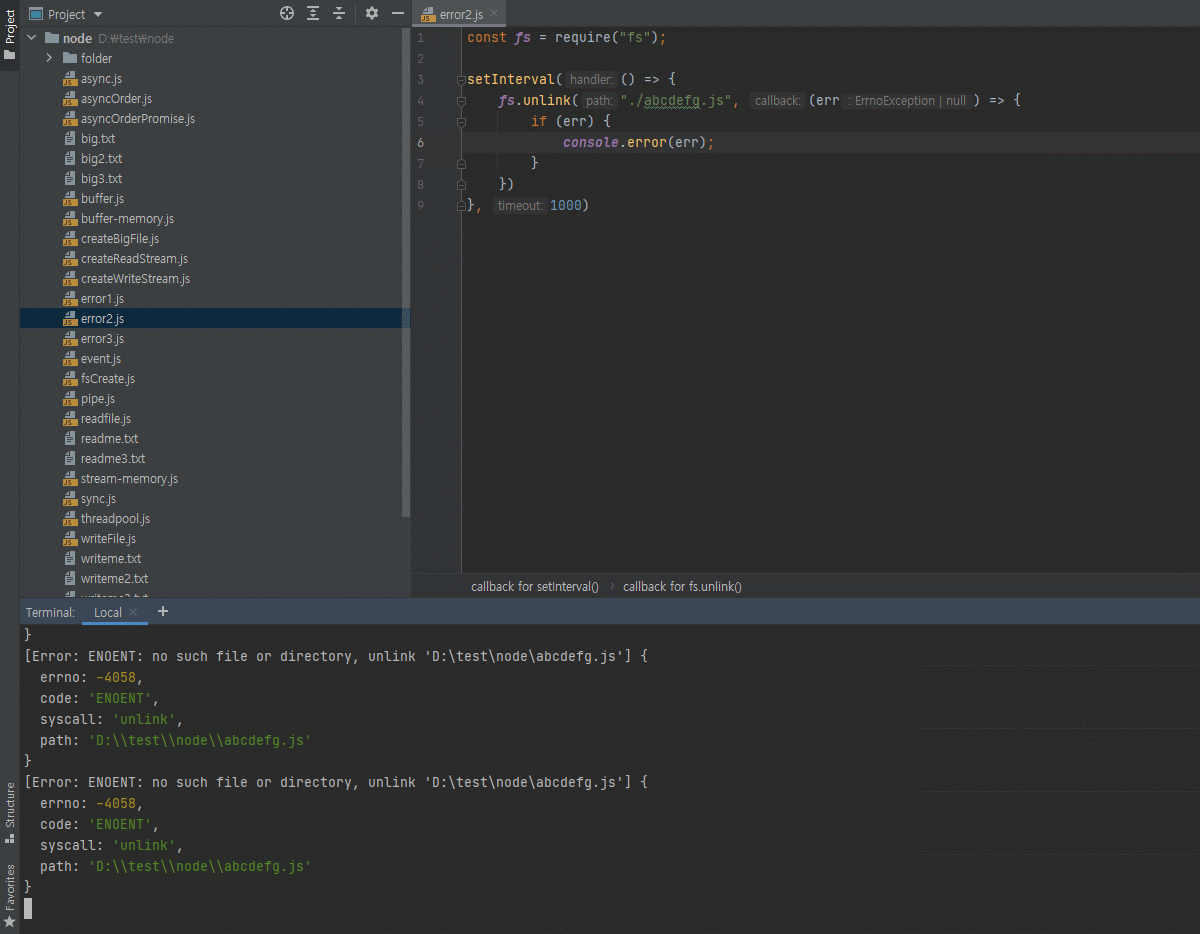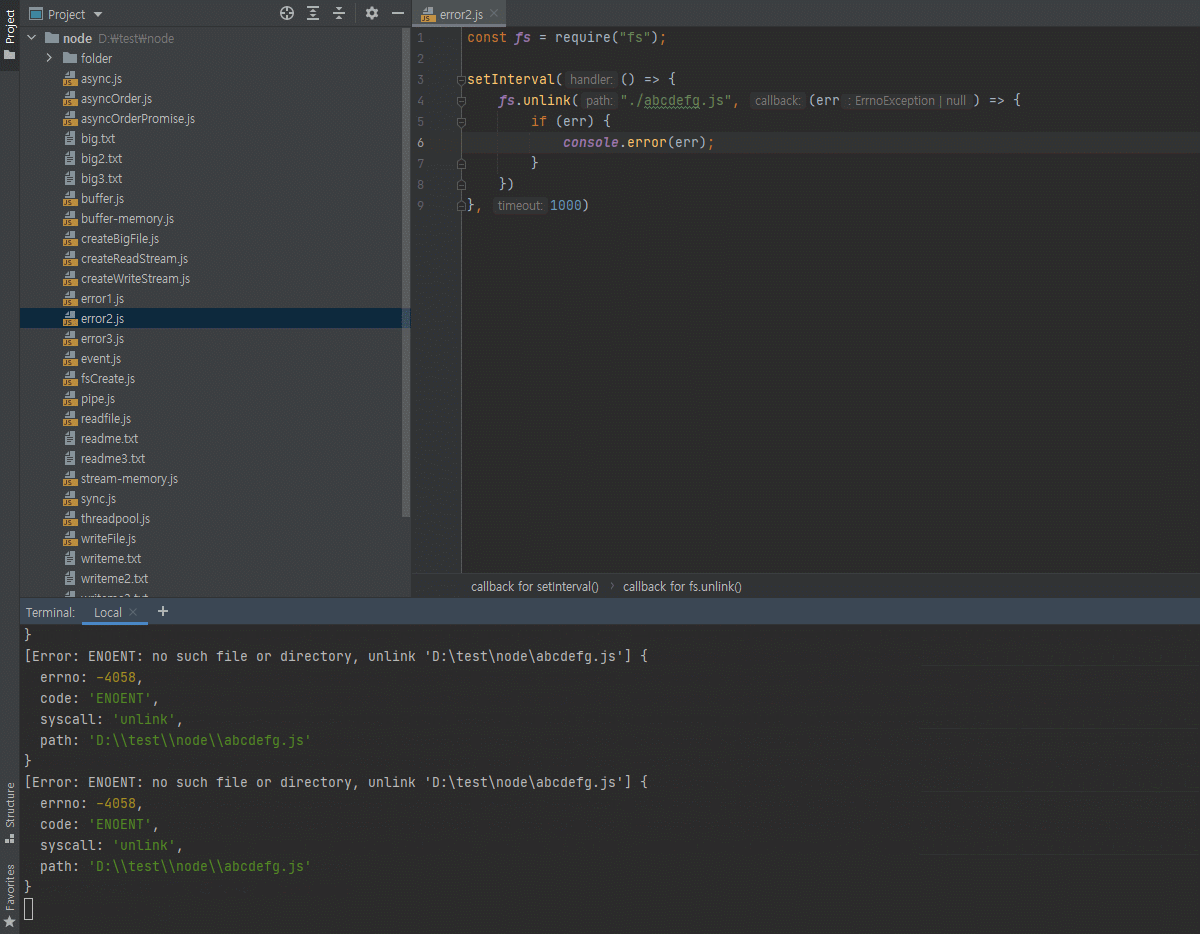
노드가 기본적으로 제공하는 비동기 함수, 메소드들의 콜백 에러는 노드 프로세스를 멈추지는 않습니다. 그렇게 생각하시면 됩니다.
-
3.16.4 프로미스의 에러
-
프로미스의 에러는 따로 처리하지 않아도 됨
-
버전이 올라가면 동작이 바뀔 수 있음
// error3.js const fs = require("fs").promises; setInterval(() => { fs.unlink("./abcdefg.js"); }, 1000)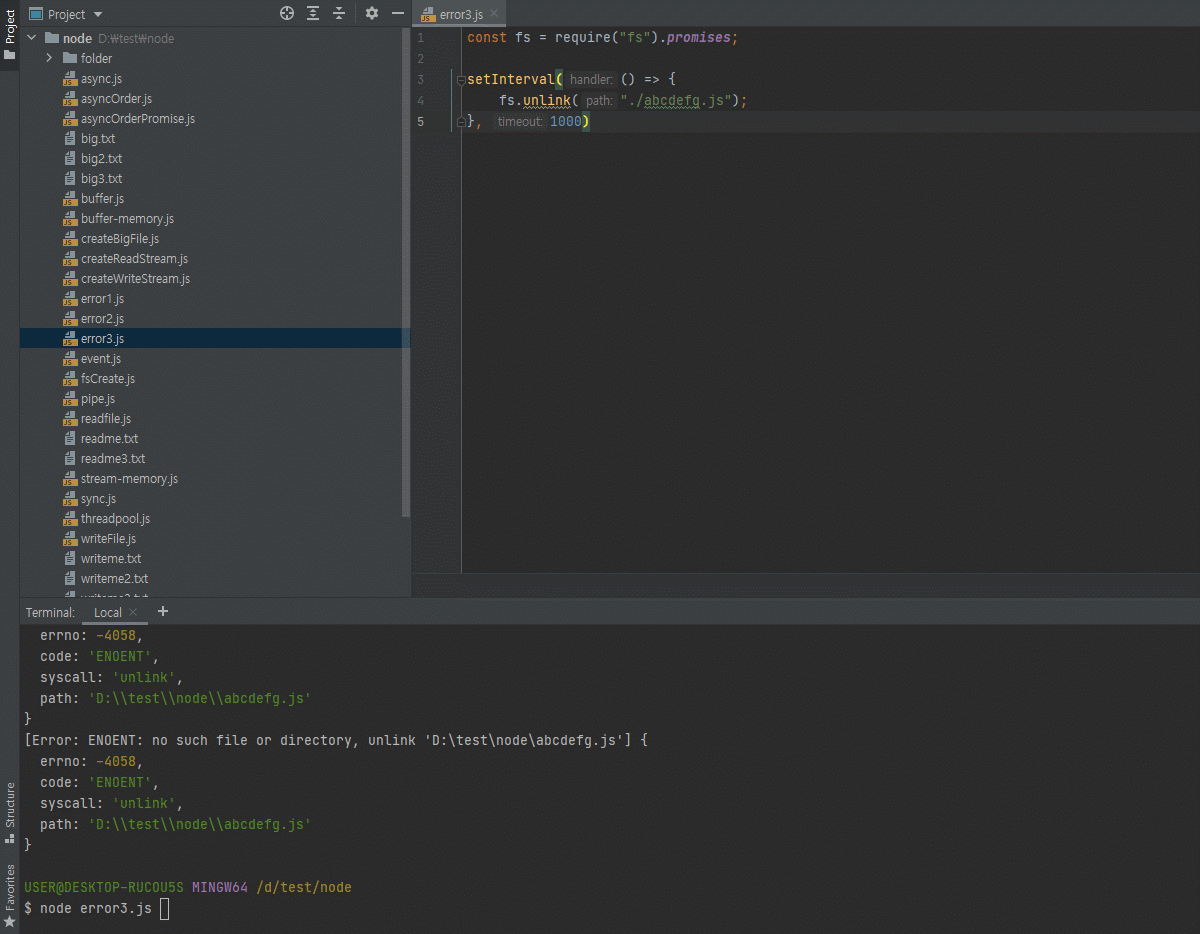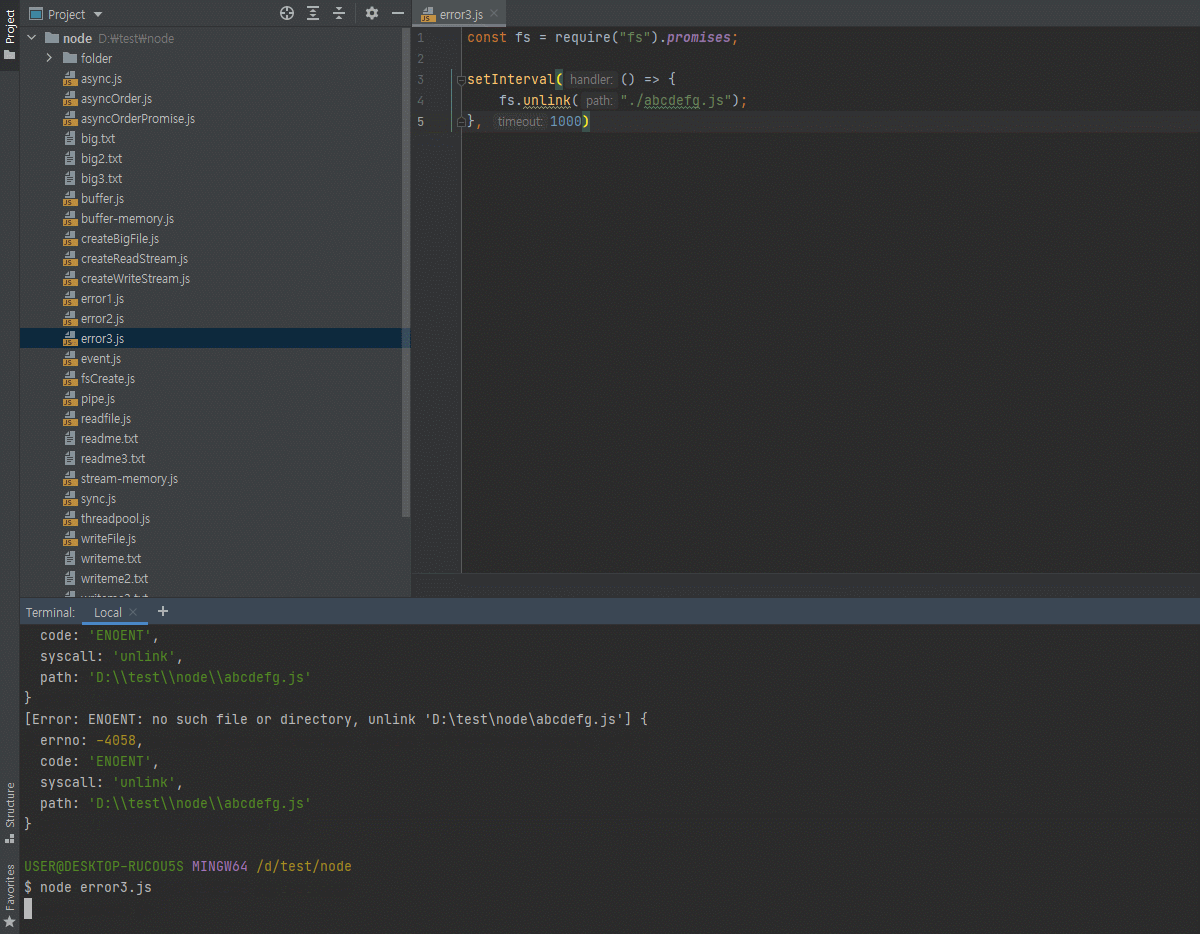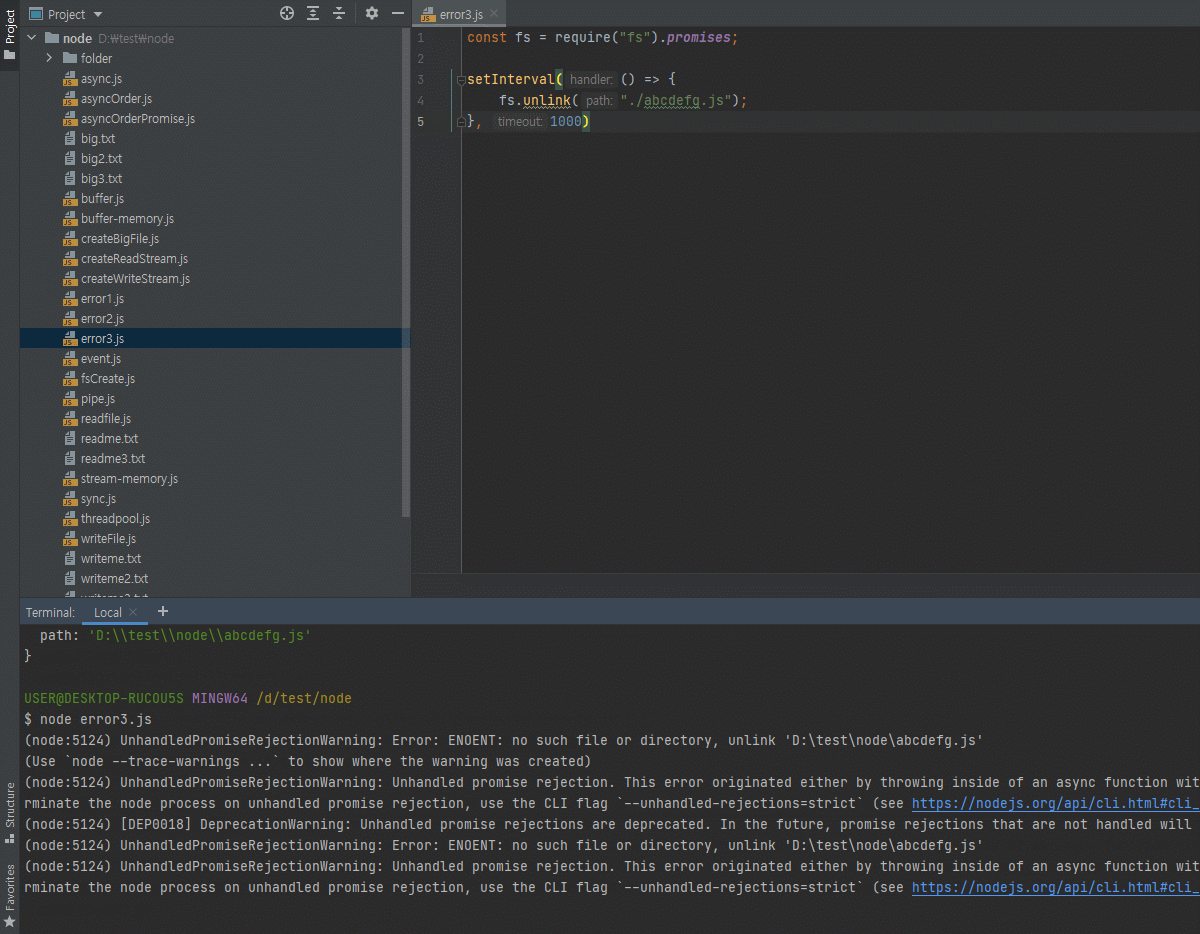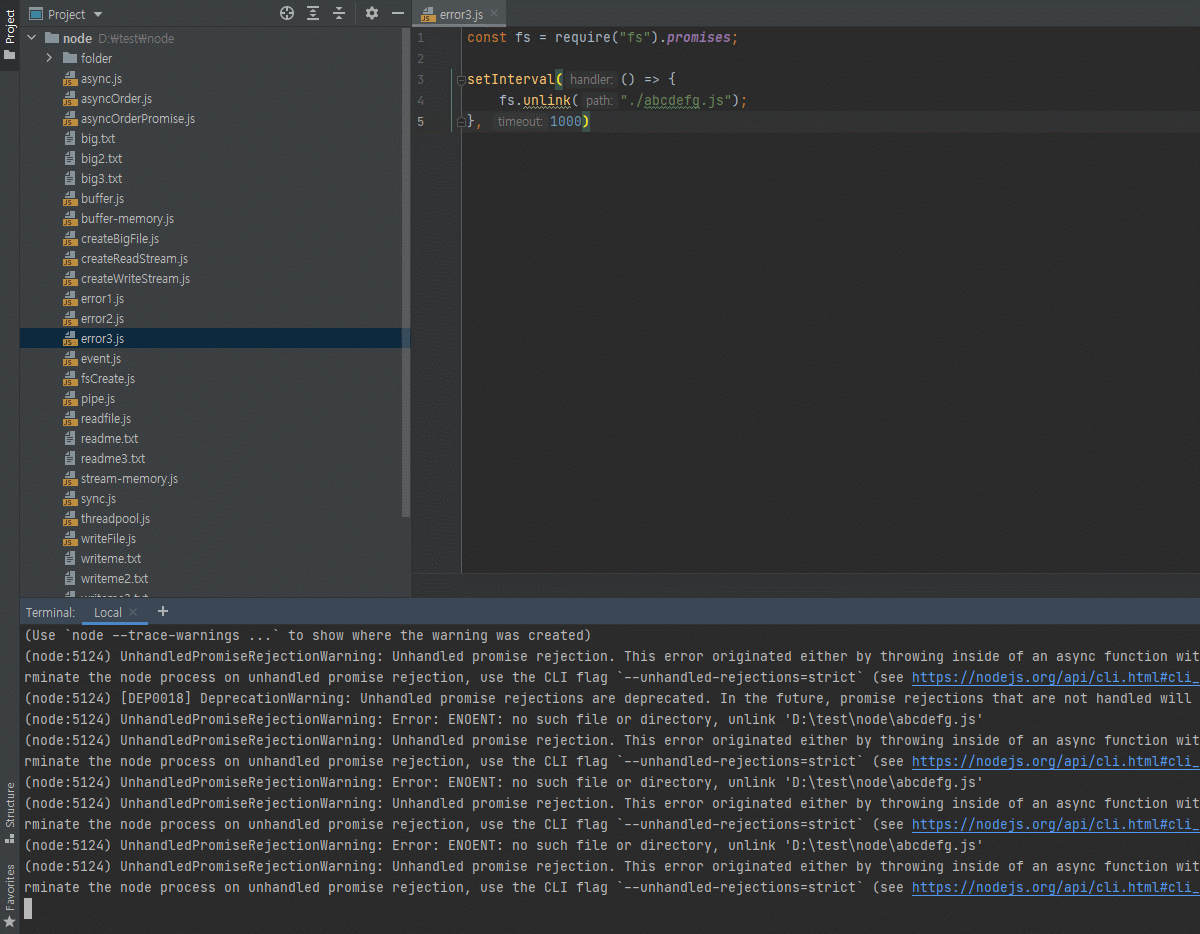
프로미스를 쓸 때 보통
catch를 붙여주잖아요?
그런데catch를 안 붙여도 프로세스가 멈추진 않습니다.
다만 위 처럼 길게 워닝(경고)이 납니다. (경고는 무시해도 됩니다.)UnhandledPromiseRejectionWarning이 문구는 기억을 해주시는게 좋은게, 프로미스에다가catch를 안붙이면 위 처럼 좀 지저분하게 나오거든요?
그리고 이게 노드14버전까지는 아직 고장은 안 나는데, 나중에 노드 버전이 올라가면 프로미스에catch를 안 붙이면 노드 프로세스를 강제 종료 할 수도 있다고 지금 미리 예고를 해놨습니다.
그래서 프로미스에는 웬만하면catch를 꼭 붙여주시는게 앞으로 프로세스 유지하시는데 도움이 많이 될겁니다.
catch안 붙였다가 나중에 노드 버전 올라갔을 때 문제가 생길 수도 있습니다.
미리미리 프로미스에catch를 붙이는 습관을 들입시다.
-
3.16.5 예측 불가능한 에러 처리하기
그리고 try-catch로 모든 코드를 감싸면, 실제로 에러가 나도 문제가 발생하지 않기는 하지만 모든 코드를 try-catch로 감싸는 것은 너무 번거롭고 try-catch 자체가 계속 중복되기 때문에.. 에러를 한 번에 처리할 수 있는 경우가 있거든요?
-
최후의 수단으로 사용
- 콜백 함수의 동작이 보장되지 않음
- 따라서 복구 작업용으로 쓰는 것은 부적합
-
에러 내용 기록 용으로만 쓰는 게 좋음
// error4.js // process 객체에다 uncaughtException 이벤트를 달아서 아래와 같이 콜백함수를 적으면 // 모든 에러가 다 아래에서 처리됩니다. process.on("uncaughtException", (err) => { console.error("예기치 못한 에러", err); }) setInterval(() => { // 원래라면 아래 throw new Error()가 프로세스를 멈춰야하지만 // 위에서 모든 에러를 처리하는 uncaughtException을 달아놨기 때문에 에러가 프로세스를 멈추지 않습니다. throw new Error("서버를 고장내주마!"); }, 1000) setTimeout(() => { console.log("실행됩니다."); }, 2000)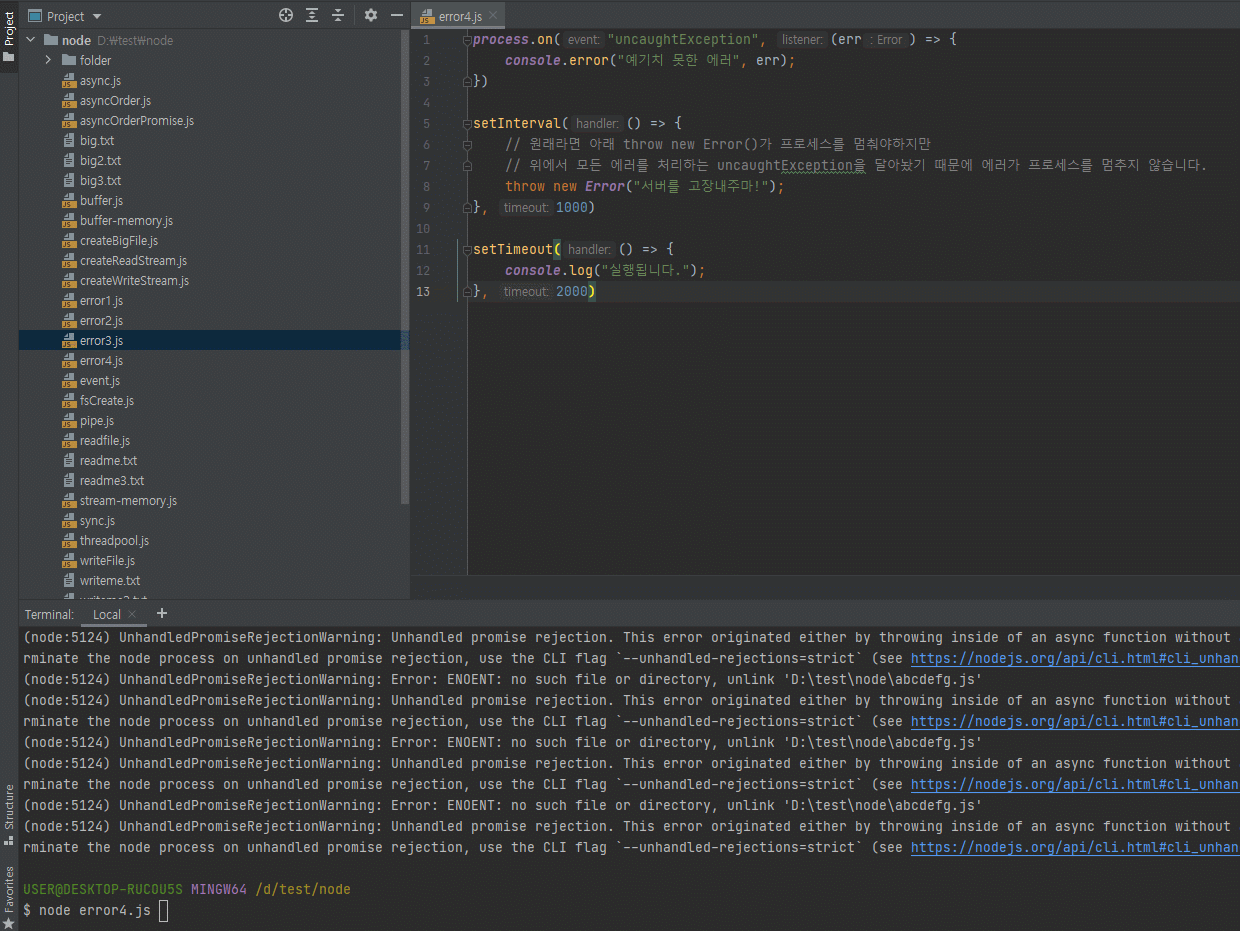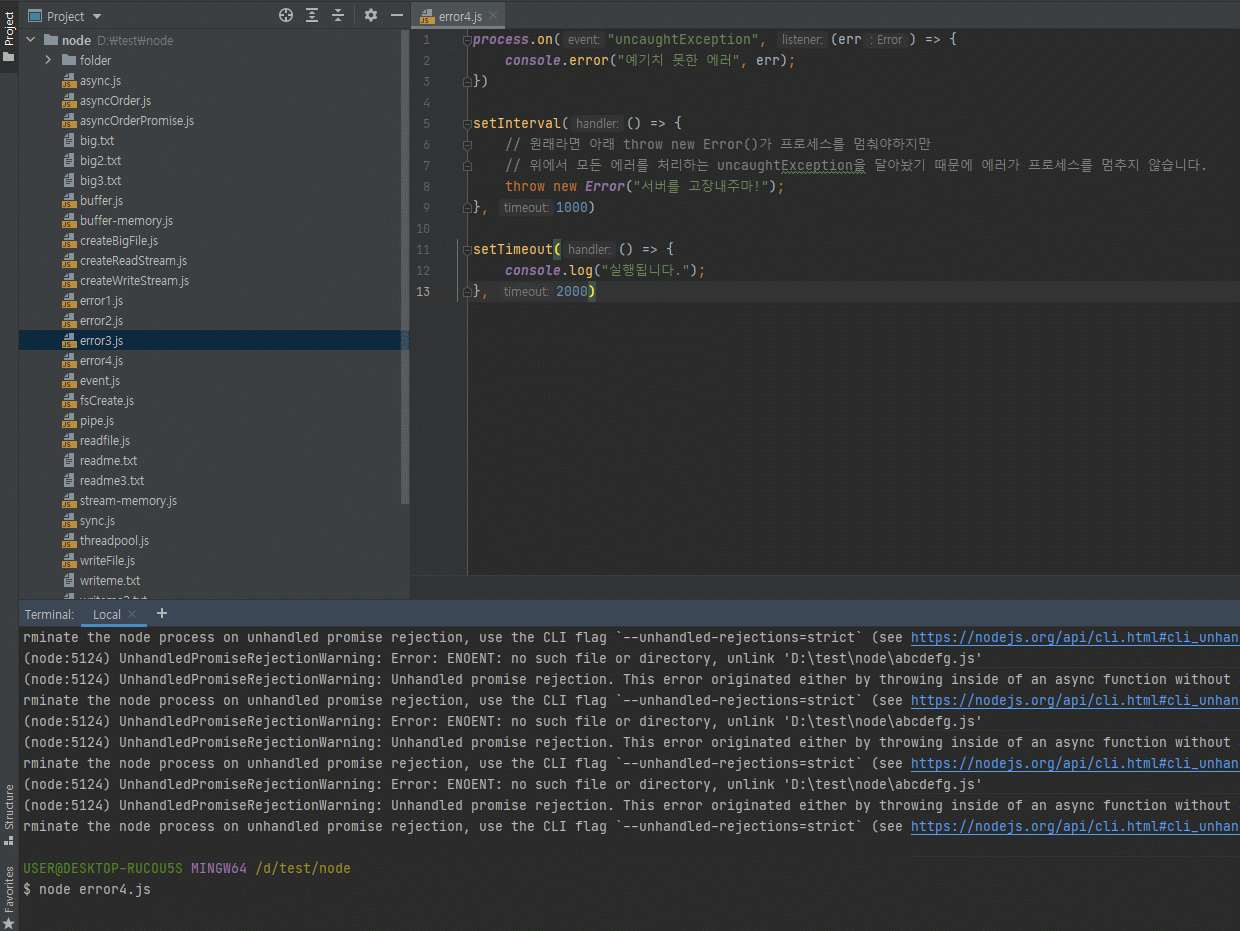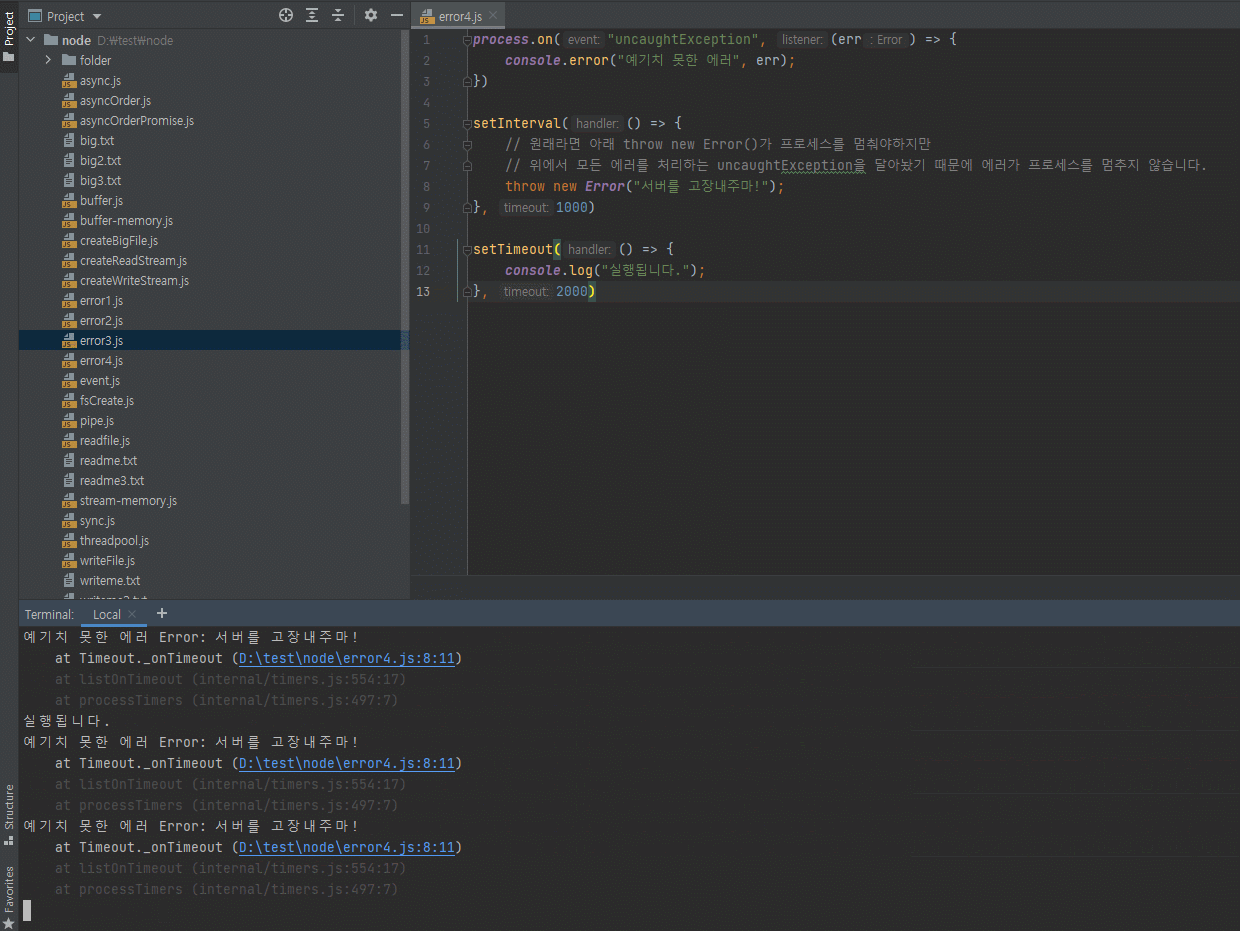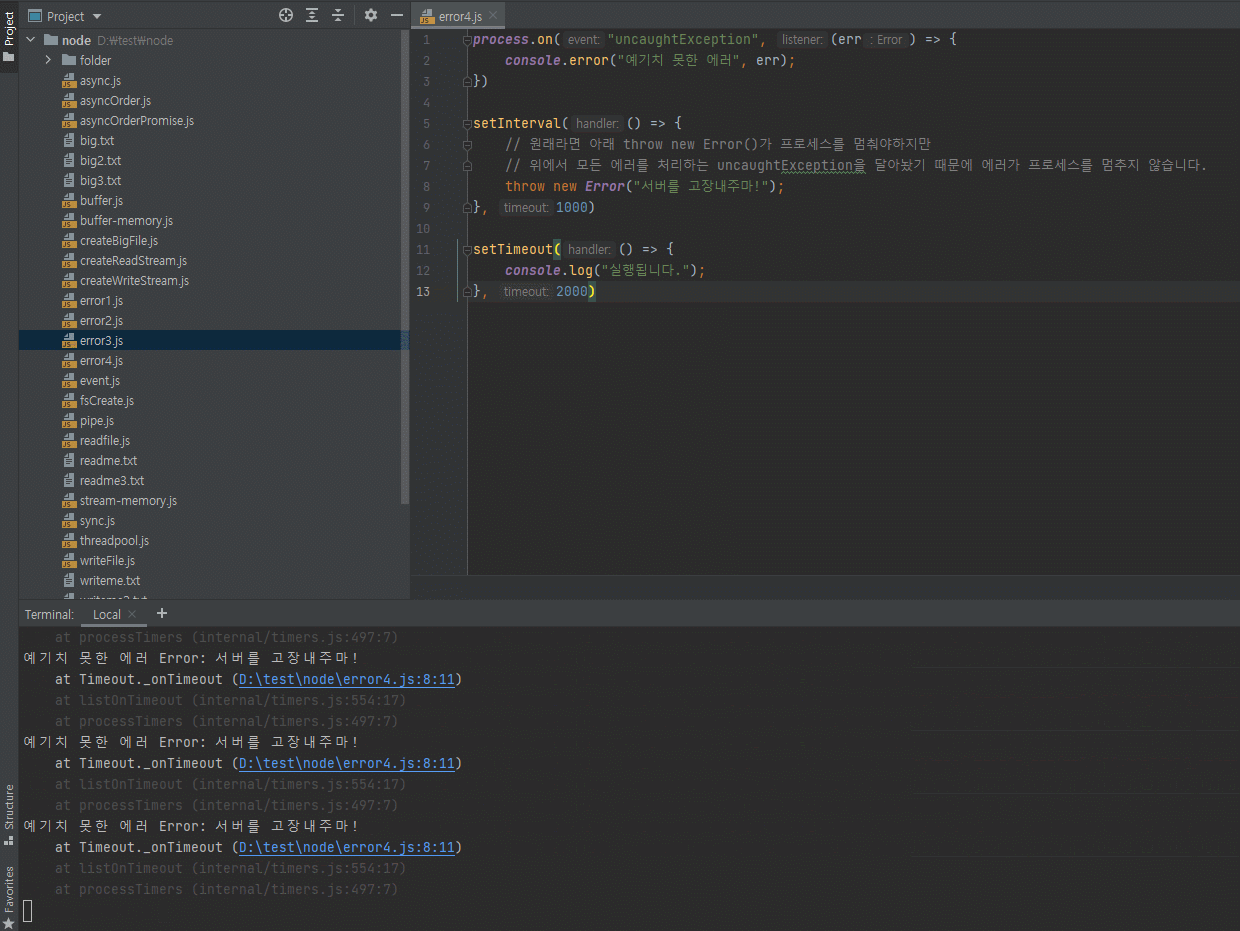
엇 그럼 위와 같은 방식이 만능 해결책이네요? 라고 생각하실 수도 있지만 이거를 만능 해결책이라고 생각하시면 안되는게, 위 코드에서 에러처리가 되었다는 것은 결국은 에러가 발생한다는 뜻이죠?
저희 서비스 자체에 에러가 있다는 거니까 그 에러를 결국은 해결해야겠죠?
그 에러를 해결하지 못하면 계속uncaughtException이 이벤트 헨들러 부분이 실행되겠죠.사용자들은 계속해서 에러 상황에 맞닿을겁니다.
그런데uncaughtException이게 모든 에러를 처리해준다고 생각하면 안돼고 얘는 단순히 에러를 기록해주는 용도라고 생각하시고 나중에 로그를 봤는데 어디어디서 에러가 발생했다 그러면 얼릉 고치셔야겠죠?
process.on("uncaughtException", 콜백함수)여기서 콜백함수 있잖아요?
콜백함수의 모든 내용이 동작한다고 노드가 보장해주지 않는다고 공식문서에 적혀져있습니다.
그래서 에러가 났을 때 복구를 하는 그런 코드는 위 콜백함수 위치에 적으시면 안됩니다.
위 콜백함수에 복구 코드를 적을 시 그 복구 코드의 실행을 노드가 보장해주지 않거든요?
보장해주지 않기 때문에 이것은 단순히 에러 기록용으로만 쓰는 것이 좋습니다.
그리고 최대한 빨리 알림을 받아서 아예 코드 자체를 수정해주는 것이 좋겠죠?그래서 노드 자체에서 에러가 발생해서 프로세스가 멈춰야되는 상황이 발생하면 가장 좋은 방법은 빠르게 에러를 파악해서 코드를 고치고 서비스를 재시작하는 것.
그것이 가장 빠른 해결책이라고 보시면 됩니다.
3.16.6 프로세스 종료하기
이거는 혹시나 프로세스를 종료하실 분들을 위해서 명령어를 적어놓은 겁니다.
-
윈도
netstat -ano | findstr 포트 taskkill /pid 프로세스아이디 /f-
netstat -ano | findstr 포트: 내 노드 서버가 몇번 포트를 사용하고 있나 알아내는 명령어.
포트 개념은 4강에서 알려드리도록 하겠습니다.
몇번 포트를 사용하고있는지 알아내면 노드 프로세스에 id가 나오거든요?
예를 들어,10035이런 숫자가 나옵니다.그리고 또 노드 프로세스 id 알아내는 방법 뭐였죠?
3강에서 배웠었는데..process.pid- 프로세스 아이디 - 그런데10035이 숫자가 나왔다. -
taskkill /pid 10035 /f: 이렇게 입력하면 해당 pid
10035프로세스가 종료됩니다. (강제종료)
-
-
맥/리눅스
lsof -i tcp:포트 kill -9 프로세스아이디-
lsof -i tcp:포트 - 내 노드 서버가 몇번 포트를 사용하고 있나 알아내는 명령어.
몇번 포트를 사용하고있는지 알아내면 노드 프로세스에 id가 나오거든요?
예를 들어,10035이런 숫자가 나옵니다.그리고 또 노드 프로세스 id 알아내는 방법 뭐였죠?
3강에서 배웠었는데..process.pid- 프로세스 아이디 - 그런데10035이 숫자가 나왔다. -
kill -9 10035: 이렇게 입력하면 해당 pid
10035프로세스가 종료됩니다. (강제종료)
-
3강은 조금 내용이 길었는데 노드에서 사용되는 것들을 요약을 해놓은거라고 보시면되고 외우지마시고 나중에 응용해야될 때, 진짜로 어떤 명령어를 칠 때 노드에서 알려주는 뭔가가 있잖아요? 프로세스 아이디같은..
이럴 때 프로세스 아이디 어떻게 찾았더라? 생각을 해보시고..
대부분 다 3장에 있을겁니다.
3장에 노드가 제공하는 중요한 것들을 요약을 해놨기 때문에 그때 3장으로 다시 돌아오셔서 찾아보시면 되겠습니다.
만약 제 강의에 없다면 공식문서를 찾아보시면 나올겁니다.
절대 외우지마시고 그때그때 찾아보시길 추천드립니다.