reduce는 필자가 가장 좋아하는 메서드입니다.
map이 배열의 각 요소를 변형한다면 reduce는 배열 자체를 변형합니다.
reduce라는 이름은 이 메서드가 보통 배열을 값 하나로 줄이는 데 쓰이기 때문에 붙었습니다.
예를 들어 배열에 들어있는 숫자를 더하거나 평균을 구하는 것은 배열을 값 하나로 줄이는 동작입니다.
하지만 reduce가 반환하는 값 하나는 객체일 수도 있고 다른 배열일 수도 있습니다.
사실 reduce는 map과 filter를 비롯해 여태까지 설명한 배열 메서드의 동작을 대부분 대신할 수 있습니다.
reduce는 map이나 filter와 마찬가지로 콜백함수를 받습니다.
그런데 여태까지 설명한 콜백에서 첫 번째 매개변수는 항상 현재 배열 요소였지만, reduce는 다릅니다.
reduce가 받는 첫 번째 매개변수는 배열이 줄어드는 대상인 어큐뮬레이터(accumulator) 입니다.
두 번째 매개변수부터는 여태까지 설명한 콜백의 순서대로 현재 배열 요소, 현재 인덱스, 배열 자체입니다.
역주_ 어큐뮬레이터 사전에는 누산기라는 뜻이 있지만 적절하지 않다고 생각해서 음차 표기합니다.
본문에서는 어큐뮬레이터라는 표현은 되도록 자제하고 ‘누적값’, ‘전 단계의 결과’ 등 문맥에 맞게 쓰겠습니다.
reduce는 초깃값도 옵션으로 받을 수 있습니다.
배열의 숫자를 더하는 단순한 예제를 봅시다.
const arr = [5, 7, 2, 4];
const sum = arr.reduce((a, x) => a +=x, 0);
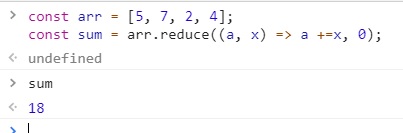
reduce의 콜백 함수는 매개변수로 누적값 a와 현태 배열 요소 x를 받았습니다.
이 예제에서 누적값은 0으로 시작합니다.
reduce의 첫 예제이니 자바스크립트가 하는 방식대로 한 단계씩 진행하며 이해해보기로 합시다.
- 첫 번째 배열 요소 5에서 (익명) 함수를 호출합니다.
a의 초깃값은 0이고 x의 값은 5입니다.
함수는 a와 x(5)의 합을 반환합니다.
이 값은 다음 단계에서 a의 값이 됩니다. - 두 번째 배열 요소 7에서 함수를 호출합니다.
a의 초깃값은 이전 단계에서 전달한 5이고, x의 값은 7입니다.
함수는 a와 x의 합 12를 반환합니다.
이 값은 다음 단계에서 a의 값이 됩니다. - 세 번째 배열 요소 2에서 함수를 호출합니다.
이 단계에서 a는 12이고 x는 2입니다.
함수는 a와 x의 합인 14를 반환합니다. - 네 번째이자 마지막 배열 요소인 4에서 함수를 호출합니다.
a는 14이고 x는 4입니다.
함수는 a와 x의 합인 18을 반환하며 이 값은 reduce의 값이고 sum에 할당되는 값입니다.
예민한 독자라면 a에 값을 할당할 필요도 없다는 것을 눈치챘을 겁니다.
화살표 함수에서 명시적인 return문이 필요하지 않았던 것처럼, 함수에서 중요한 건 무엇을 반환하는가 이므로 그냥 a + x를 반환해도 됐을 겁니다.
하지만 reduce를 더 잘 활용하려면 누적값이 어떻게 변하는지 생각하는 습관을 기르는 게 좋습니다.
더 흥미로운 예제를 보기 전에, 누적값이 undefined로 시작한다면 어떻게 될지 생각해 봅시다.
누적값이 제공되지 않으면 reduce는 첫 번째 배열 요소를 초깃값으로 보고 두 번째 요소에서부터 함수를 호출합니다.
앞 예제에서 초깃값을 생략하고 다시 생각해 봅시다.
const arr = [5, 7, 2, 4];
const sum = arr.reduce((a, x) => a += x);
- 두 번째 배열 요소 7에서 함수가 호출됩니다.
a의 초깃값은 첫 번째 배열 요소인 5이고 x의 값은 7입니다.
함수는 a와 x의 합인 12를 반환하고 이 값이 다음 단계에서 a의 값입니다. - 세 번째 배열 요소 2에서 함수를 호출합니다.
a의 초깃값은 12이고 x의 값은 2입니다.
함수는 a와 x의 합인 14를 반환합니다. - 네 번째이자 마지막 배열 요소인 4에서 함수를 호출합니다.
a는 14이고 x는 4입니다.
함수는 a와 x의 합인 18을 반환하며 이 값은 reduce의 값이고 sum에 할당되는 값입니다.
단계는 하나 줄었지만 결과는 같습니다.
이 예제를 포함해, 배열의 첫 번째 요소가 그대로 초깃값이 될 수 있을 때는 초깃값을 생략해도 됩니다.
reduce는 보통 숫자나 문자열 같은 원시 값을 누적값으로 사용하지만, 객체 또한 누적값이 될 수 있고 이를 통해 아주 다양하게 활용할 수 있는데도 간과하는 사람들이 많습니다.
예를 들어 영단어로 이루어진 배열이 있고 각 단어를 첫 글자에 따라 묶는다고 하면 reduce와 함께 객체를 쓸 수 있습니다.
const words = [
"Beachball",
"Rodeo",
"Angel",
"Aardvark",
"Xylophone",
"November",
"Chocolate",
"Papaya",
"Uniform",
"Joker",
"Clover",
"Bali"
];
const alpahbetical = words.reduce((a, x) => {
if (!a[x[0]]) a[x[0]] = [];
a[x[0]].push(x);
return a;
}, {})
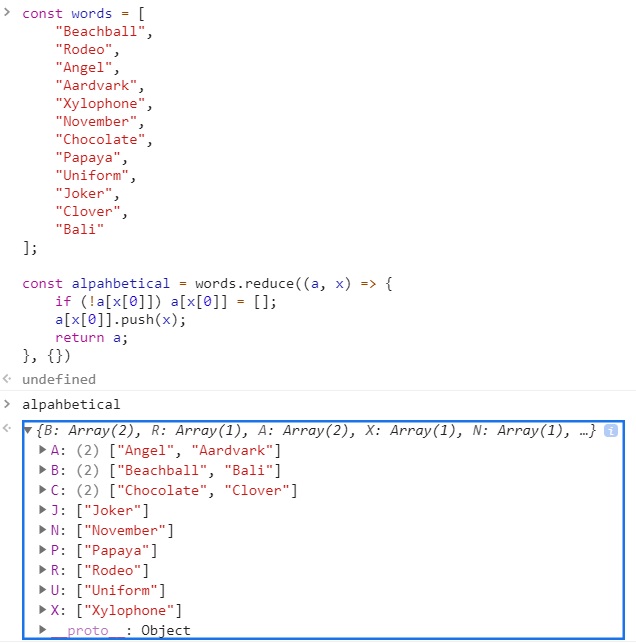
이 예제는 조금 더 복잡하지만 원칙은 같습니다.
배열의 모든 요소에서 콜백 함수는 전 단계의 결과에 이 단어의 첫 번째 글자인 프로퍼티가 있는지 확인합니다.
그런 프로퍼티가 없다면 빈 배열을 추가합니다.
즉, “Beachball”을 만나면 a.B 프로퍼티를 확인하는 데 그런 프로퍼티는 없으므로 빈 배열을 만듭니다.
그리고 그 단어를 적절한 배열에 추가합니다.
“Beachball”은 a.B 프로퍼티가 없었으므로 빈 배열에 추가되고, 마지막으로 {B : [Beachball]}인 a를 반환합니다.
reduce는 통계에도 사용할 수 있습니다.
예를 들어 데이터 셋의 평균(mean) 과 분산(variabce) 을 계산한다고 해 봅시다.
const data = [3.3, 5, 7.2, 12, 4, 6, 10.3];
// 도널드 커누스(Donald Knuth)가 분산 계산을 위해 만든 알고리즘입니다.
// [컴퓨터 프로그래밍의 예술 : 준수치적 알고리즘(개정 3판)]
const stats = data.reduce((a, x) => {
a.N++;
let delta = x - a.mean;
a.mean += delta/a.N;
a.M2 += delta * (x - a.mean);
return a;
}, {N: 0, mean: 0, M2: 0})
if(stats.N > 2) {
stats.variance = stats.M2 / (stats.N - 1);
stats.stdev = Math.sqrt(stats.variance);
}
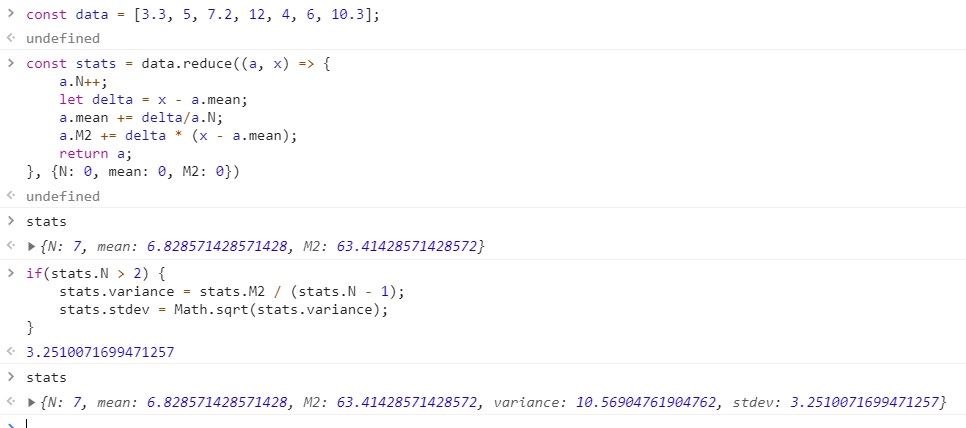
변수 여러 개, 특히 mean과 M2를 사용해야 하므로 이번에도 객체를 누적값으로 썼습니다.
원한다면 N 대신 인덱스에서 1을 뺀 값을 써도 되긴 합니다.
reduce의 유연성을 알아보기 위한 한 가지 예제를 더 살펴보겠습니다.
예제 자체는 매우 조악하지만, 이번에는 문자열을 누적값으로 사용합니다.
const words = [
"Beachball",
"Rodeo",
"Angel",
"Aardvark",
"Xylophone",
"November",
"Chocolate",
"Papaya",
"Uniform",
"Joker",
"Clover",
"Bali"
];
const longWords = words.reduce((a, w) => w.length > 6 ? a+" "+w : a, "").trim();
// longWords: "Beachball Aardvark Xylophone November Chocolate Uniform"
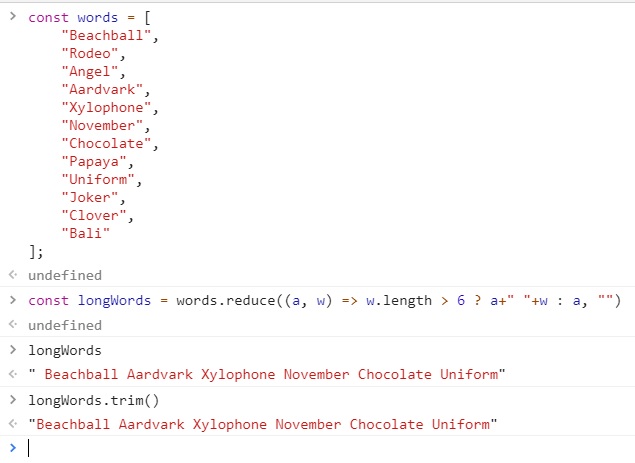
이 예제는 문자열 누적값을 써서 6글자가 넘는 단어를 모아 문자열 하나로 만들었습니다.
reduce 대신 filter와 join을 써서 같을 결과를 얻을 수 있습니다.
이건 독자의 연습문제로 남겨 두겠습니다.
reduce 다음에 trim을 호출한 이유를 먼저 생각해 보십시오.
reduce의 잠재력을 잘 활용할 수 있게 되길 바랍니다.
reduce는 배열 메서드 중에서 가장 범용적이고 가장 강력한 메서드입니다.