ES6+ 함수와 OOP 2회차
2회차 스터디 주제
- Spread Ref
메인루틴과 서브루틴이 통신을 할 때 참조값을 활용하면 문제가 크다. 이에 대해 좀 더 살펴보도록 하자.- Sub Routine Chain
서브루틴 안에 서브루틴이 있는 경우를 깊게 살펴보면 Tail Recursion optimize라는 꼬리물기 최적화에 대해 이해할 수 있다.- Tail Recursion
위의 서브루틴 체인에 대해 이해하고 나면 꼬리물기 최적화에 성공한 재귀함수에 대해 이해가 가능하다.- Tail Recursion to loop
그렇게되면 재귀함수를 손쉽게 루프로 바꿀 수 있다.- Closure
- Nested closure(중첩된 클로져)
- Shadowing
- Co routine
Spread ref

참조값은 잠깐 전파가 되는 것이 아니라 지속적으로 전파되어 오염을 시킨다.
위 식에서 지난번 가이드대로 Local variable을 사용했지만, 이 지역변수조차 B를 물고있다.
즉, 참조를 계속 물고 있기 때문에, A와 B는 참조가 서로 전파되고 있다. (서로 관계가 생기게 된다.)
이렇게되면 나중에 어디에서 오류가 발생했는지 디버깅해도 찾을 수 없게 된다.

새로운 참조값인 D를 추가해보자.
D를 ROUTINEB에게 넘겼다고 해보자.
위와 같은 식이라면 C하고 D도 서로 관계가 없다고는 못한다.
여기서 더 최악인 경우는 D자리에 A가 넘어가는 것이다.
위 소스는 겉보기엔 멀쩡해보이고 깔끔해보이나, 참조가 서로 얽히고 섥혀서 어디서 문제가 터질지 모르는 코드인 상태인 것이다.
ROUTINEA만 보면 별로 문제가 아니게 보일 수도 있다.
새로운 객체를 생성하는데 무엇이 문제가 되겠어? 라고 생각할 수 있다.
하지만 문제는 MAIN FLOW의 A = ROUTINEA(B) 부분이다.
이 MAIN FLOW 단계에서 A가 B와 관계된 무언가를 할 때 문제가 발생한다.
방법은 복사본을 사용하는 것이다.
결론 : 참조를 소유한 참조 객체를 만들어도 참조의 여파는 끝나지 않는다.
이 모든 문제의 근원은 B를 그냥 사용하고 있다는 것이다.
복사본의 개념에서 보자면 위의 LA에 B를 넘길 때 조차도 복사본을 넘겼어야 했다.
인자로 넘어가는 B도 전부 new 처리해서 넘겨야 된다.
B를 그냥 사용하면 간접적으로라도 서로 물리기 때문에 이 오염이 끝나질 않는다.
Sub routine chain
참조값을 안넘길 수는 없으니 내부에서 새로운 값을 만들어서 리턴하거나 복사본을 사용하자.
그때의 대상이 단지 만들어진 값만을 포함하거나 만들어진 값한테 인자로만 넘겨도 위험하다.
그러니 아예 처음부터 새로 만들고 시작하는 것이 편하다.
(아.. 이게 작년 리액트 배울 때 딥카피 개념인가? 스프레드 연산자로 하는…)
여러분이 만든 함수는 여러분만 쓰는 것이 아니다.
그렇기에 꼼꼼하게 살펴야 한다.
복사본으로 넘어가는지, 객체 참조인지 아닌지를 항상 확인하는 습관을 가져야된다.
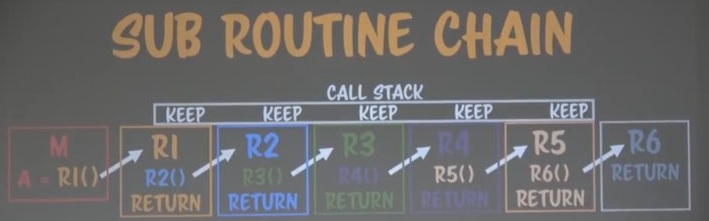
위와 같이 서브루틴에 서브루틴이 있으면 콜스텍에 루틴들이 쌓이게된다.
그리고 하나씩 리턴될 때마다 스텍이 사라지게 된다.
그리고 결과값이 리턴된다.
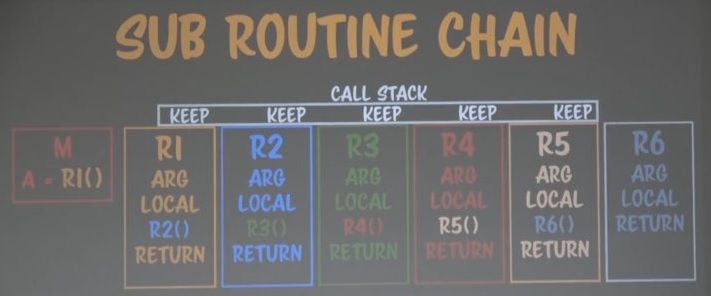

Keep의 정확한 대상들이다.
아주 정확하겐 위의 인자(arguments)와 지역변수(local variable)를 기억하는 메모리가 필요하다.
이걸 기억한 상태에서 다음 서브루틴으로 갔다가 다시 돌아오는 것이다.
그렇다면 함수는 호출되는 순간 하나 분량의 미니 메모리를 갖게되는 것이다.
이 미니 메모리엔 인자와 지역변수가 들어있다.
이것이 바로 자바스크립트에서 excution context(실행 컨텍스트)라고 부르는 것이다.
함수가 호출될 때 만들어지는 것이고 이 실행 컨텍스트 안엔 인자와 지역변수가 담겨져 있다.
이걸 해제하지 않고 그 다음 서브루틴을 부르는 것이다.

중간에 있는 함수 콜을 끝으로 옮겼다.
루트에서 return 이후는 없는 거다.
즉 return 이후는 해당 함수가 끝나는 걸 의미한다.
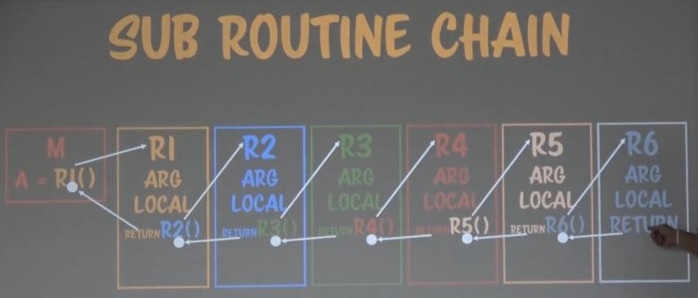
위가 해당 함수의 흐름이다.
여기서 약간 아이디어를 바꿔보자는 것이다.
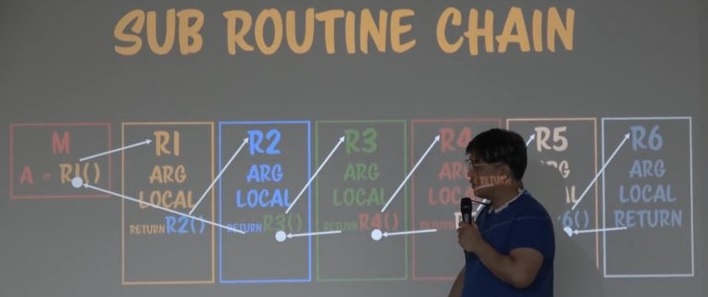
함수 안의 Keep 부분을 메모리에 저장할 필요가 없다면, R2의 리턴값을 Main으로 보내는 것이 어떻겠냐는 것이다.
리턴 포인트는 언어 수준에서 결정된다.
언어 엔진 수준에서 함수를 호출할 때 리턴 포인트를 결정한다.
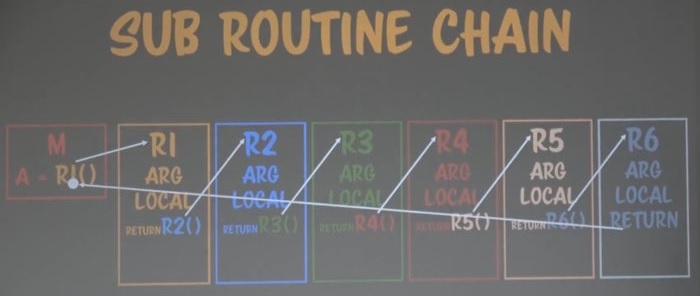
이 아이디어를 확장하면 위와 같은 흐름이 된다.
위의 함수 흐름을 보면 더 이상 콜스텍이 없다.
이런 흐름을 바뀐다면 아까와는 굉장히 다르다.
아무리 많은 함수를 불러도 유지하는 메모리가 없게되는 것이다.
게다가 각 함수의 영역을 유지할 필요도 없다.
리턴 포인트가 없기 때문이다.
이러한 흐름은 반드시 언어 수준에서 도움을 줘야된다.
왜냐하면 함수의 리턴 포인트를 바꿔주는 것은 언어밖에 못하기 때문이다.
따라서 언어가 이 기능을 지원하냐 안하냐에 따라서 꼬리물기 최적화를 지원하냐 안하냐가 결정되는 것이다.
위와 같은 식의 조건은 다음과 같다.
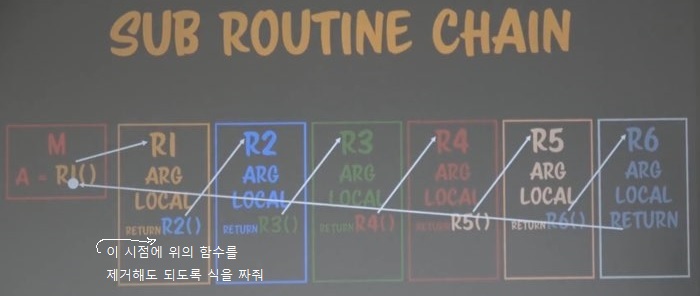
이것을 우리는 꼬리물기 최적화(Tail Recursion)라고 부르는 것이다.

이 방법은 안타깝게도 이를 지원하는 언어에서밖에 사용 못한다.
이를 지원하는 언어 수준에서 위와 같이 꼬리 물기 최적화를 활용해 소스를 짠다면 해당 소스는 메모리를 많이 사용하지 않고, 함수 메모리를 사용하고 바로 해제하고 사용하고 헤제하는 식으로 메모리를 사용한다.
이는 제어문과 같은 작동원리이다.
for문은 돌때마다 항상 그 안에 있는 것을 메모리에 유지하지 않는다.
for문 안에 있는 내용은 다음 for문을 돌릴 때 index 변수를 제외하곤 다 해제해버린다.
이를 제어문의 stack clear 기능이라고 부른다.
제어문의 루프문(for, while)들은 모두 stack clear 기능을 갖고 있다.
구식 언어는 stack clear를 안해주는 언어도 있다.
for문 같은 제어문을 goto 언어의 우아한 버전이라고 생각하면 큰 오산이다.
제어문은 원래 앞에 실행되었던 stack문을 제거해버리는 기능이 있다.
우리가 사용하는 abc 언어의 제어루프문은 루프 블록의 stack clear 기능이 있다.
그런데 이를 언어가 함수 수준에서도 구현할 수 있게 해준다면, 함수 수준에서 제어문과 동일하게 소스를 짤 수 있다는 것이다.
위 함수 예제도 마치 for문을 돌릴 때의 메모리 동작과 같은 효과를 낸다는 것이다.
그래서 꼬리물기 최적화를 지원하는 언어에서는 for, while문의 도움을 받지 않고도 고성능의 루프를 만들어낼 수 있다.
이게 먼나라 이웃나라 이야기일까?
아니다. 현재 사파리가 지원하고 있다.(2018년 9월 7일 기준)
크롬과 엣지는 아직 지원 안된다.
그래서 사파리에선 재귀함수를 꼬리물기 최적화해서 짠다면 몇억번을 호출해도 뻑나지 않는다.
이렇게하면 스크립트 타임아웃이 뻑날뿐이지 stack overflow로 죽지 않는다.
Tail Recursion(꼬리물기 최적화)

이것이 재귀함수이다.
위 재귀함수는 꼬리물기 최적화가 될까, 안될까?
위의 함수는 현재 꼬리물기 최적화가 된거일까?
아니다.
sum(2)의 리턴값이 와서 계산되려면 3 +가 메모리에 남아있어야 한다.
현재 꼬리물기 최적화를 방해하고 있는 요소는 더하기이다.
연산자는 꼬리물기 최적화를 방해한다.
그래서 메모리를 해제시키지 못한다.
연산을 하기위해선 스택 메모리가 필요하다.
그렇다면 이걸 어떻게 tail recursion하게 바꿀까?
메모리를 유발시키는 것을 모두 제거해야지 tail recursion을 실현시킬 수 있다.
제일 마지막에 return과 함수콜만 남겨야지 진짜 tail recursion을 실현시킬 수 있다는 것이다.
한 가지 조건(마지막 return에다 함수를 콜해)은 충족시켰지만 더하기 연산자 때문에 tail recursion을 이루지 못하고 있는 것이다.
가장 많이 알려진 방법
연산을 인자로 옮긴다.

위의 식을 보면 인자쪽에 연산을 옮겼다.
여기서 의문이 들것이다.
어? 3항연산자도 연산식인데 위와 같이 작성하면 3항 연산식도 stack memory에 쌓이지 않나요?
언어에는 stack에 쌓이지 않는 연산자가 따로 정의되어 있다.
자바스크립트 같은 경우엔 3항 연산자와 &&, || 연산자는 stack memory를 일으키지 않는다.
이들은 tail recursion의 대상이다.
보통 언어에선 위 세가지가 stack memory를 일으키지 않는 연산자로 지정이 되어있다.
- truthy && A : 이럴 경우엔 A의 값만 평가하면 된다.
- falsy && A : 이럴 경우엔 A의 값을 평가하지 않아도 된다.
- truthy || A : 이럴 경우엔 A의 값을 평가하지 않아도 된다.
- falsy || A : 이럴 경우엔 A의 값만 평가하면 된다.
즉, 앞의 값이 뭐냐에 따라 뒤에 값을 평가하거나 평가하지 않아도 되는 것이 이들 연산자의 특징이다.
즉, 이 연산자들은 stack에 메모리를 쌓을 필요가 없다는 것이다.
stack을 잡지 않아도 stack을 clear할 수 있다. 뒤로 갈지말지를 결정할 수 있기 때문이다.
3항 연산자도 마찬가지이다. 맨 왼쪽을 평가한 다음에 어느 것을 불러올지를 선택하면 되기 때문에 stack에 쌓을 필요가 없다.
꼬리물기 최적화가 안되어있는 함수를 꼬리물기 최적화 함수로 바꾸는 첫번째 전략은 내부에서 연산이나 상태를 유지해야될게 있으면 다 말아서 다음번 함수 콜에 인자로 전달하는 것이다.
내 메모리는 해제하고 다음 함수콜의 인자로 다 넘겨버리는 것이다.
tail recursion으로 하다보면 인자가 늘어나는데 이는 어찌보면 당연한 것이다.

tail recursion을 언어가 지원하면 재귀적으로 돌아가지 않고 그때마다 메모리를 해제하고 마지막에 원래 최초의 콜 포인트로 보내면 그만이라는 것이다.
stack memory를 활용하는 코드에서 다음 함수콜의 인자 메모리를 사용하도록 수정했다.
재귀적인 로직이 있으면 앞으론 꼬리물기 최적화 형식으로 짜는 습관을 들인다!!!! 무조건!!!!!!!!

노란색 인자 메모리를 stack memory를 사용하는 연산자를 대신해 사용한다.
왜? 내 메모리를 해제할 수 있으니깐.
다음번 함수 메모리를 사용하면 되니깐.
함수의 메모리는 인자와 지역변수로 이뤄져있다.
내 메모리는 해제하고 다음 함수쪽 인자메모리를 사용하는 것이다.
함수를 테일리컬션하게 바꾸면 함수 외적 메모리를 알 수 있다.
위의 prev메모리는 루프 바깥쪽 메모리라고 할 수 있다.
루프 바깥쪽메모리가 아니었다면 꼬리물기최적화를 할 수 없기 때문이다.
Prev를 계속 물고있었다면 꼬리물기 최적화를 할 수 없다.
외재화시켰기 때문에 꼬리물기 최적화를 할 수 있는 것이다.
이는 제어문 for문에 지역변수가 있고 그 지역변수를 갱신해서 사용하는 구조랑 똑같은 것이다.
위의 함수를 for문으로 만든다면 sum이란 지역변수를 루프 바깥에 정의하고 그 변수에 합을 쌓아나가는 식으로 정의할 것이다.
이를 어그리게이션(Aggregation)이라고 한다.
그 역할을 위의 prev가 하는 것이다.
그래서 이렇게 메모리를 유지해야되는 부분을 외재화하면 루프화를 할 수 있게된다.

테일 리컬션(꼬리물기 최적화)한 함수는 루프로 기계적으로 바꿀 수 있다.

const sum = (v) => {
let prev = 0;
while(v>1){
prev += v;
v--;
}
return prev;
}
sum(3);
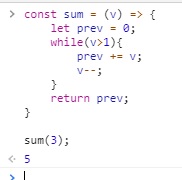
const sum = (v, prev=0) => {
prev += v;
return (v>1 ? sum(v-1, prev) : prev)
}
sum(3)
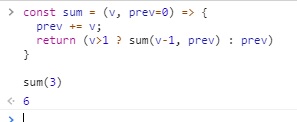
(음.. 위 결과값이 다르긴 한데… 뭐, 이 부분은 부등호만 수정해주면 되는 부분이니뭐..)
꼬리물기 최적화로 함수를 작성한다면 기계적으로 루프로 바꿀 수 있다.
별로 큰 고민을 안해도된다.
*꼬리물기 최적화 함수 - 스택을 쌓지않는다. *루프 - 스택을 쌓지않는다.(스택클리어)
꼬리물기최적화를 지원안하는 언어는 기계적으로 루프문으로 작성할줄 알아야된다.
프로개발자라면 루프문을 꼬리물기최적화된 재귀함수로 재귀함수를 루프문으로 기계적으로 자유자재로 바꿀수 있어야된다.
언어 지원 확인 -> 꼬리물기최적화 재귀함수 -> 루프문
하노이의 탑 알고리즘을 꼬리물기 최적화로 바꾼 담에 루프문으로 바꾸면 바꿀 수 있다.
그 반대도 마찬가지다.
Closure

Main flow에 A, B 변수가 있고, ROUTINEA에 B를 넘겨 변수 A에 받았다고 했을 때, ROUTINEA는 내부에 인자와 지역변수를 만들게 된다.
하지만 실제론 이렇게 작동하는 언어가 매우 드물다.
이렇게 작동하는 대표적인 언어는 ‘C’이다.
뿐만아니라 이렇게 작동하는 여러 언어들은 ‘루틴’을 만드는게 무엇으로 되어있다?
문으로 되어있다.
C에서 함수를 선언할 수 있는 것은 ‘문’이지 자바스크립트처럼 값에 대입할 수 있는 것이 아니다.
그래서 세상에는 서브루틴을 ‘객체’형태로 만들어내는 언어가 있고, ‘문’의 형태로 만들어내는 언어가 있다.
자바의 메소드는 클래스 안에 ‘문’ 형태로 존재해야된다.
바깥쪽에서 값으로 대입할 수가 없다. 반드시 문으로 선언된다.
그래서 완전히 시그니쳐가 똑같은 메서드가 있다고 하더라도 A라는 클래스와 B라는 클래스를 위해 하나의 메서드만 작성하는 것은 불가능하다.
똑같이 두벌을 만들어야된다.
왜? ‘문’이기 때문이다.
대신에 얘네들은 ‘문’으로 만드는 경우엔 정적 디스패치라는 것을 할 수 있기 때문에, 서브루틴이 어디에 만들어지는지 얼만큼의 메모리를 갖게되는지를 다 컴파일 시점에 확정을 지어버린다.
그렇기 때문에 얘는 클로져가 생성되지 않는다.
그냥 루틴과 서브루틴의 관계만 생성된다.
이는 서브루틴을 ‘문’으로 작성하는 언어의 특징이다.
그런데 현대 언어가 발전하면서 람다라는 기술이 등장했다.
이 람다라는 기술은 ‘서브루틴을 값으로 볼래’라는 기술이다.
이 기술을 활용하면 루틴 안에 서브루틴이 ‘문’으로 작성됨에도 불구하고 값으로 처리되어 여기저기로 보내 활용할 수 있다.
이 기술은 C언어의 함수포인터로부터 발전된 기술이다.
그래서 우리는 드디어 런타임에 서브루틴을 만들수 있게 되었다.
‘문’밖에 지원되지 않으면 코드로 하드코딩해야지만 해당 함수가 태어나기 때문에 절대로 실행 중에 함수가 태어나는 일이 없다.
정의할 때만 만들어지고 실제 런타임에선 사용밖에 못하는 것이다.
그런데 우리가 이를 값으로 만들어낼 수 있다면 실행 도중에 루틴을 만들어낼 수 있다. 파괴할 수도 있다.
즉 클로져라는 현상은 런타임 도중에 루틴을 만들 수 있는 언어에서만 생겨난다.
C와 자바에서 순수 클래스에선 클로져라는 현상이 안생기는 이유다.
자바세어 이너클래스를 사용해야 클로져가 생긴다.


그래서 이 메모리가 스테틱 스테이트 즉 정적으로 생긴 메모리는 클로져가 안생긴다 유일하게 참조해야될 영역이 글로벌밖에 없다.
그래서 위의 식 안에서 루틴a가 사용할 수 있는 메모리는 자기 자신안의 인자와 지역변수 그리고 전역메모리밖에 없다.
C에서는 이를 스태틱 메모리라고 부른다.
이것이 바로 함수를 문으로 만드는 언어들의 특징이다.
아직 객체지향을 안배웠으므로 객체 컨텍스트에 대한 이야기는 지금은 안할것이다.
메서드는 위와 다르게 객체컨텍스트에서 찾아올 수 있는데 지금은 메서드 배우는 시간이 아니기때문에.

그에비해서 런타임때 루틴을 만들 수 있는 언어들은 루틴이 처음부터 정적인 언어로 존재하지 않는다.

메인플로우가 실행되는 와중에 루틴이 태어난다.
메모리에 미리 적재되어있는 것이 아니라 실행 도중에 태어난다는 것이다.

그럼 이제 글로벌만 바라보는 것이 아니라 자기가 태어난 지역변수도 바라보게 되는 것이다.
그럼 이제 글로벌과 자기의 지역변수와 인자만 바라보는 것이 아니라 태어낫을때에 자기가 갇혀있던 박스도 바라볼 수 있는 여지가 생긴다.
그래서 런타임에서 루틴을 만들 수 있는 언어들은 자기자신이 어디서 만들어졌는지도 같이 기록한다.
자바스크립트에선 이를 스코프라고 부른다.
자바스크립트 3.1, 5버전 엔진 공부 X
보다더 언어론적인 언어의 근본적인 공부를 해야된다.
스코프 체이닝 이런게 중요한게 아니다.
실제로 요즘은 스코프 체이닝도 안한다.
보다 더 언어의 루틴이 문으로 작성되는지 아니면 값으로 될수있는지 또 각각의 경우에 어떤 현상이 발생하는지 이런 공부를 하는 것이 좋다.
여튼 위의 메인플로우의 서브루틴은 내가 어떤 플로우에서 탄생했는지를 알고 있는 것이다.
내가 이 메인루틴에서 탄생했구나를 기억하는 것이 아니라 이 메인루틴의 플로우에서 탄생했구나를 기억한다.
이 차이는 중요하다.
플로우를 알고있기 때문에 플로우에서있는 변수들을 기억하는 것이다.
그래서 아까 정적인 함수에 비해서 동적으로 함수를 만들 수 있는 언어에서는 인식할수있는 변수가 더 늘어났다.

노랑박스에 등장하지 않은 변수들을 자율변수라고 부른다.
노랑박스에는 없는데 그 바깥에 변수를 인식할 수 있다면 다 자율변수라고 부른다.
그런데 이 자율변수를 서브루틴이 가져오게되면 마음대로 해지하거나 조작하지 못한다.
루틴이 자율변수를 안 건드리면 괜찮은데 건드리는 순간 해지가 안된다.
사브루틴에서 사용하기 때문에 자율변수를 해지를 못하고 그대로 잡고 내려가는 것.
만약 서브루틴에서 건드리지 않은 자율변수가 있다면 그 자율변수는 바로 해지될것.
그래서 위 오렌지박스 부분은 자율변수가 갇히는 공간이라고 볼 수 있다.
프리 벨리에블스 클로져라고 볼 수 있네.
이거의 줄임말이 바로 클로져
지역변수나 인자들은 원래 오렌지박스에 갇혀있다.
자율변수를 추가해서 가둘뿐.
클로저는 자율변수에 대한 클로져를 뜻한다. (Free variables closure)
그런데 위 서브루틴을 다른데로 빼돌렸다고 생각해봐라.
그럼 위의 플로우가 다 실행되고 사라져야되는데 그럴 수가 없다.
자율변수 또한 사라질 수 없다.
서브루틴이 자율변수를 다 가둬버렸기 때문이다.
이것이 바로 클로져이다.
클로져를 구현하는 방법은 언어마다 천차만별이고, 자바스크립트도 버전마다 다르다고 생각하면 된다.
그래서 여러분들이 보고있는 책 내용대로 움직이지 않는다. 지금도 이미.
단편적인 개념들을 익혀봤자 도움이 안된다.
언어 근본적인 개념을 익히는 것이 훨씬 좋다.
런타임에서 루틴을 만들 수 있는 언어라면 자율변수라는 개념이 있고, 자율변수를 루틴이 인식할 수 있는 시스템이 있으면 클로져가 발생할 수 밖에 없다.
그런데 언어에 따라선 런타임 때 루틴을 발생시키는데도 자율변수를 안 받아들이는 언어도 있다.
그런 언어들은 클로져가 발생하지 않는다.
런타임에 루틴이 발생한다고 무조건 클로져가 발생하는 것은 아니라는 것이다.
이는 언어 디자이너가 어떻게 디자인했느냐에 따라 달라지는 것이다. 하지만 대부분의 언어들은 자율변수가 존재하면 클로져 기능이 있다.
보통 루틴이 태어나는 환경을 컨텍스트라고 부른다.
클로져는 자바스크립트의 부분적인 내용이 아니다.
언어론적으로 공부해야지 이런 맥락으로 총체적으로 이해할 수 있다.
이러한 맥락에서 전역변수도 자율변수라고 생각할 수 있다.
해당 루틴 안에 없는 것은 모두 자율변수니깐.

Nested Closure(중첩된 클로져)

아까봤던 메인 Flow 흐름이다.
그런데 클로져라는 것은 루틴만이 만들어내는 것은 아니다.
자바스크립트는 ES5까지만해도 루틴만이 클로져를 만들어냈는데, ES6 이후부턴 블록스코프라는 개념이 생겼다.
그래서 블록만 만들어도 스코프라는 것이 태어난다. 이 스코프라는 것은 결국에는 스코프를 만드는 행위이다.
함수를 만들지 않고서도 블록만 생성해도 스코프를 만들 수 있게 되었다.(클로저)

함수와 블록을 생성함으로써 클로져를 생성할 수 있다.
현재의 자바스크립트는 이런 체인을 통해서 중첩되어있는 클로져 영역을 마구마구 생성할 수 있다.
여러분들이 중괄호만 계속 반복해서 쳐도 클로져가 만들어진다.

이런 내용을 코드로 작성하면, 위와같이 나타낼 수 있다.
오른쪽 코드를 보면, 글로벌(전역) 변수가 있고,
그 아래 첫번째 블록(if문)이 나왔고,
그 바로 안에 함수(루틴)가 나왔다.
그리고 그 루틴 안에 또 블록(if문)이 나왔다.
그리고 그 블록 안에서 다시 루틴이 나온다.
고작 위와 같은 정도의 코드가 왼쪽과 같은 상황을 만들어낸다.
이런 단순한 코드가 내부 메모리에선 중첩된 클로저를 발생시키는 것.
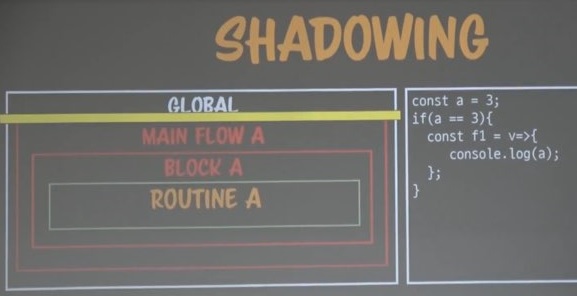
쉐도잉

전역변수 a
그 안에 블록에 변수 a
또 그 안에 블록에 변수 a
이를 쉐도잉이라 부른다.
쉐도잉은 언어에서 채용하고 있는 경우도 있고 아닌 경우도 있다.
층층이 생성되어있는 클로저마다 같은 이름의 변수가 있을 때 쉐도잉이 발생한다.
이런 쉐도잉이 발생했을 땐, 가장 가까이 있는 변수를 참조한다.
위 console.log(a)는 가장 가까이 있는 7을 참조한다.
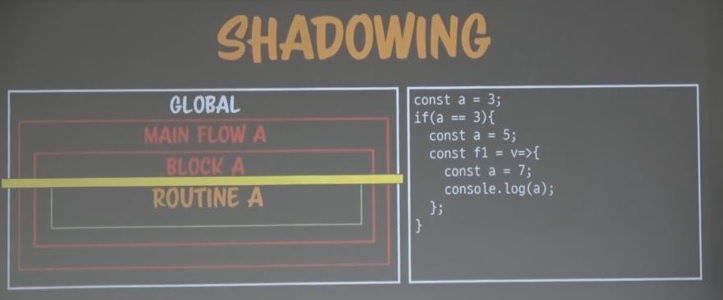
그래서 왼쪽 노랑색 시점에서 쉐도잉이 발생하면 그 위로는 보이지 않는 것이다.
그 위로는 그림자가 발생하고 어두워져. 그래서 쉐도잉이라고 부르는 것이다.
그럼 쉐도잉은 언제 쓰는 것일까?
네임스페이스를 정의할 때 쓴다.
이 변수 이름이 내부쪽에선 다른 뜻으로 사용되어야 해, 라고 할 때 반드시 쉐도잉이 발생하는 이름으로 지어야 한다.
보호하기 위해서이다.
바깥쪽에 있는 자율변수를 보호하는 가장 확실한 방법은 이 방법이다.
클로저에선 몇단계 바깥에있는 자율변수를 모두 사용할 수 있다.
이 말은 반대로 말하면 안에 있는 변수가 바깥에 있는 자율변수를 모두 오염시킬 수 있다는 것이다.
즉 안에 있는 변수가 바깥쪽 변수를 오염시키게하지 않는 방법은 쉐도잉이라는 것이다.
let a = 3;
if (true) {
let a = 5;
console.log(a);
}
console.log(a);
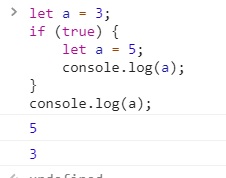
이런식으로 쉐도잉을 활용해 블록 바깥에 있는 자율변수를 지킬 수 있다.
그래서 쉐도잉은 절대로 취향대로 쓰는 것이 아니다.
바깥쪽 자율변수를 지키기위한 유일한 방법이란 것이다.
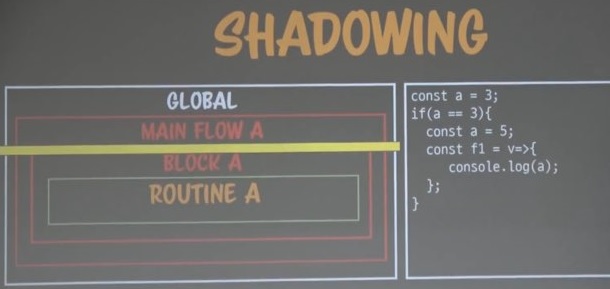
위와 같이 클로저가 영향을 끼칠 수 있는 범위, 접근권한을 설정할 수도 있다.
결론
쉐도잉은 중첩된 클로저를 지원하는 언어에서 외부 변수를 보호하는 유일한 방법이다.
쉐도잉은 취향의 문제가 아니라, 권한과 보호의 문제다.
왜 쉐도잉이 생겨났을까?
개발자마다 ‘좋은 이름’을 쓰고 싶어하기 때문이다.
좋은 이름이란 가장 명확하고 단순한 이름을 뜻한다.
하지만 이런 좋은 이름을 쓰는 것은 어렵다.
그 이유는 좋은 이름일 수록 기저에 있는 것들이 먼저 사용하기 때문이다.
Array, Date, … 이런 이름들은 자바스크립트 엔진이 가지고 있다.
그 다음으로 좋은 이름들은 시니어 개발자들이 보통 사용한다.
제일 먼저 코드의 줄기를 짜는 사람들이기 때문이다.
그 다음이 주니어 개발자들이다.
즉, 서로가 다들 좋은 이름을 사용하고 싶어하기 때문에 나도 모르게 바깥쪽에 있는 자율변수를 건드릴 수 있는 이름을 사용하기도 한다.
(개발 공부의 중요성)
이 때문에 바깥변수에 영향을 줄 수 있는 코드를 짤 수 있다.
이런 이유로 쉐도잉은 중첩된 클로저를 지원하는 언어에서는 반드시 필요하다.
다시 말하지만, 쉐도잉은 단순히 발생하는 언어적 특성? 현상이 아니다.
내부에 있는 루틴이 바깥쪽 자율변수를 건드리지 못하도록하는 유일한 방책인 것이다.
대부분의 언어가 그러한 이유로 쉐도잉을 지원하는 것이다.
클로저 내부에 있는 루틴이 제일 먼저 맨 바깥에 있는 자율변수를 참조하는 것이 아닌,
가장 가까운 자율변수를 참조하게 설계된 것도
이런 보안 이슈 때문에 이런 디자인 패턴으로 설계된 것이다.
CO ROUTINE

코루틴이라는 개념은 1960년대 이미 나왔다.
코루틴에 지대한 영향을 끼친 것.
제어문이라는 것은 결국 ‘명령어’고 명령어는 메모리에 적재되어 실행이된다.
그리고 메모리에 적재된 명령어는 한번 실행되면 완료될 때까지 멈출 수 없다고 고정관념처럼 인식했다.
그런데 어느순간 이 명령어를 직접실행하지 않고 이 명령어 하나하나를 객체나 함수에 담았다가 내가 실행하고 싶을 때 실행하면 안될까? 라는 생각에 도달했다.
이것이 패턴으로 얘기하자면 바로 커맨드 패턴이다.
이러한 추상적인 개념에 도달하고 나니깐 서브루틴에있는 명령어를 일괄로 실행하지 않고 실행하다 중간에 멈출 수 있겠다라는 결론에 도달한 것이다.
서브루틴이 한 100줄 정도 되는데, 20줄정도까지 실행했다가 멈췄다가..
(서브루틴은 리턴포인트를 알고 있다.)
나를 호출한 리턴포인트로 값을 보낸다. 20줄까지의 결과값을..
그리고 메인 플로우가 흐르다가 다시 서브루틴을 호출하면 20번째 줄부터 다시 실행된다.
그리고 50번째줄 정도에 또 리턴해.
- 원래 우리가 알고 있는 서브루틴 : 한번 실행되고 실행 완료 후 리턴
- 코루틴 : 여러번 실행되고 여러번 리턴
이 아이디어는 ‘문’을 중간에 멈출 수 있다는 생각에 의해 만들어졌다.
코루틴을 지원하지 않는 언어에서는 함수를 활용해서 코루틴처럼 소스를 만들어내야한다.
하지만 코루틴을 언어에서 지원한다면 우리는 소스를 ‘문’처럼 작성했는데, 해당 문들을 각각 멈추었다가 다시 실행할 수 있다는 것이다.
그래서 ES6부터 이러한 코루틴 개념을 지원하기 위해서 여러분이 작성한 모든 ‘문’을 레코드라는 객체로 감싸 메모리에 저장한다.
그래서 자바스크립트에서 ‘문’은 실제로 한번에 실행되는 것이 아니라 해당 ‘문’들이 레코드로 만들어져서 이 레코드가 메모리에 올라가있고, 자바스크립트 엔진은 해당 레코드들을 실행하고(invoke) 실행했다가 멈출 수 있는..그런식으로 작동한다.
정확하게 커맨드 패턴과 일치한다.
이렇게 작동하기 때문에…
우리는 ‘자바’ 혹은 ‘C’ 처럼 생긴 소스를 작성했다고 생각하지만,
엔진에서는 이 ‘문’ 하나하나를 전부 다 객체로 바꿔서 실행한다.
그래서 사실은 한번에 실행되는 것이 아니다.
이걸 도입하면서 자바스크립트도 코루틴을 사용할 수 있게 되었다.
코루틴 VS. 싱글루틴
- 싱글루틴 : 한번에 완료할 때까지 실행되며 리턴도 한번만
- 코루틴 : 여러번 실행되며 여러번 리턴
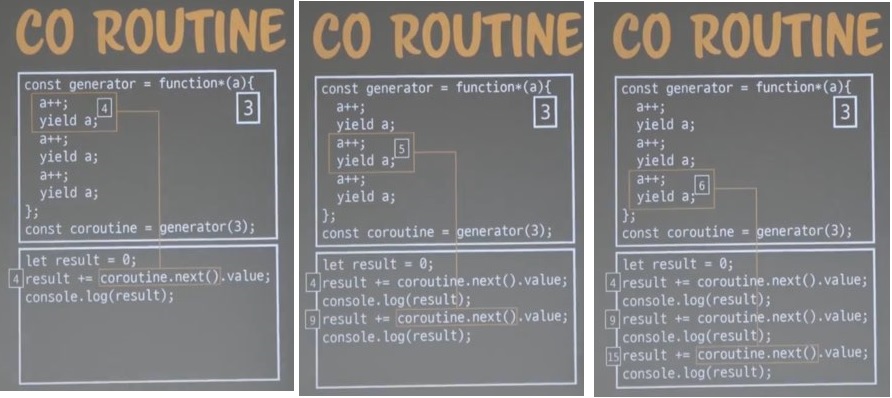
자바스크립트에선 이 코루틴이라는 개념을 제너레이터를 통해서 하고 있다.
그래서 제너레이터를 활용하면 신기한 것을 많이 할 수 있다.
코루틴을 이해하기 전에 먼저 ‘루틴’에 대해서 알아보자.
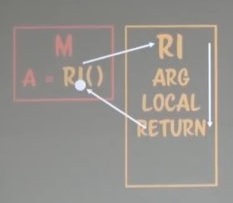
- 루틴 : 호출 -> 실행 -> 완료 -> 리턴
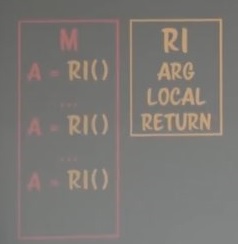
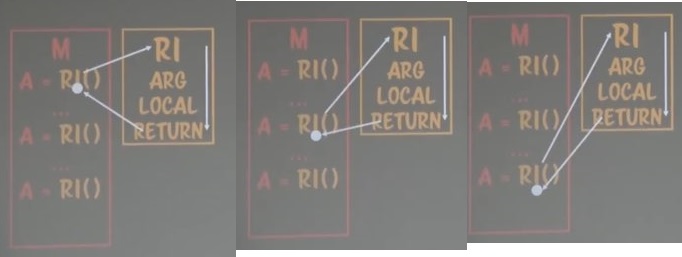
그렇기 때문에 싱글루틴은 호출할 때마다 위와 같은 플로우가 발생하게 된다.
싱글루틴은 호출하면 항상 루틴의 끝까지 실행한다라는 것을 보장하고 있다.
이를 일반적으로 우리는 그냥 ‘루틴’이라고 부른다.
코루틴은 위와 다르게 작동한다.

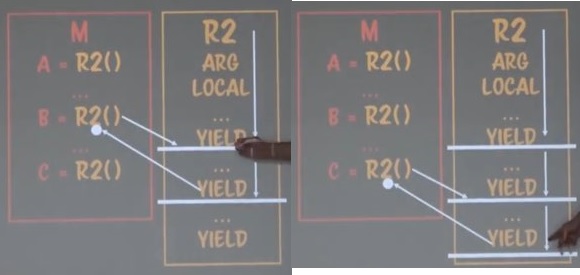
- yield : 이 키워드는 언어마다 다르다. ES6에서 ES7으로 넘어올 때 자바스크립트는 C#의 영향을 크게 받았다.
C#의 키워드를 갖고온 것이다. - 일시정지(suspension) : 코루틴은 일시정지하는 기능이 있다. 일시정지해있는 상태를 ‘서스팬션’이라고 한다.
‘문’인데도 불구하고 ‘서스팬션’을 걸 수 있기 때문에 위와같은 플로우가 가능하다.
원래 ‘문’은 멈출 방법이 없다.
for문을 중간에 멈출 방법은 없다.
그런데 코루틴은 ‘문’을 실행하다 멈출 수 있다. 서스팬션.
코루틴의 장점
코루틴이 없기 전까진 각각의 함수를 다 만들어야 했다.
게다가 서로 연관되어있는 것들이 많다면?
인자값을 넘겨야되고~ 인자값으로 뭐 받아와야되고~ 소스를 짜기가 복잡해진다.
반면, 코루틴을 사용하면 같은 메모리 안에서 돌아가게 할 수 있다.
지역변수도 상태를 유지하고 있다.
서스팬션이 걸릴 뿐이지 메모리가 해지되지 않는다.
즉, 인자값으로 뭐 넘겨주고 이럴 필요없이 지역변수로 소스를 관리할 수 있게 된다.
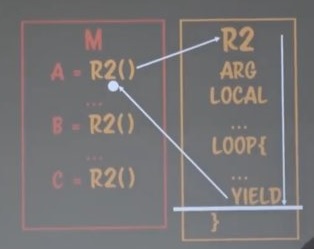
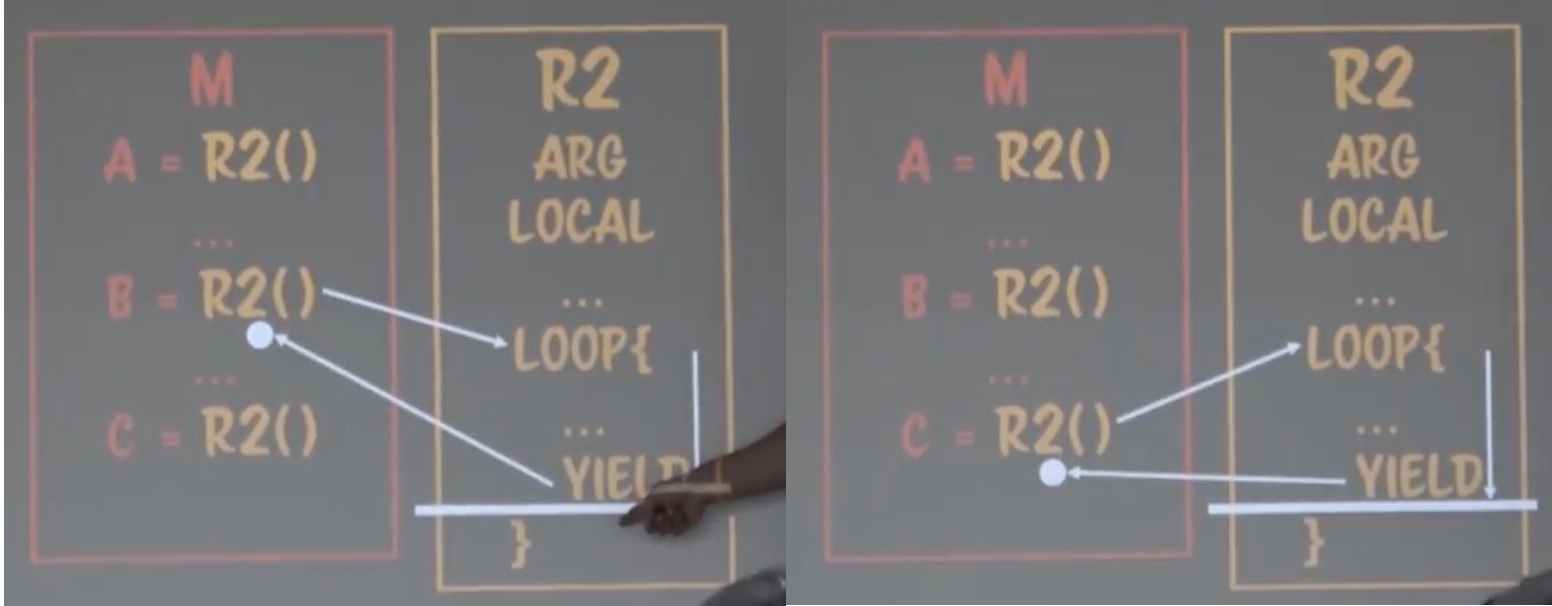
코루틴에서 루프가 등장할 때를 생각해보자.
위처럼 루틴이 한번돌때마다 멈출 수 있다.
멈추지 않는 무한루프를 넣는다해도 프로그램이 퍼져버릴 일이 없다.
루프는 리컬시브한 재귀함수로 고칠 수 있다.
그렇다면 위 코루틴을 사용해 리컬시브한 재귀함수를 전진할지 말지를 정할 수 있다는 얘기고
보통 코루틴이 없는 언어는 이런식으로 코루틴을 구현한다.
잘은 모르겠지만….

제너레이터로 코루틴을 구현할 수 있다.

제너레이터로 만든 함수가 코루틴이 아니다.
제너레이터로 만든 함수를 호출했을 때 그것이 코루틴이 된다.
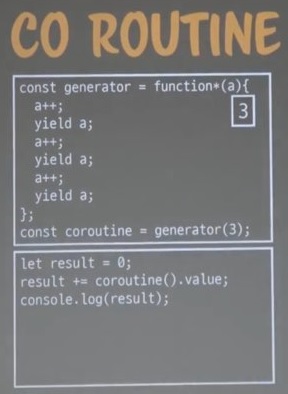
result에 어그리게이션하는 예제이다.
코루틴(제너레이터 호출)은 이터레이터 리절트 오브젝트를 반환한다.
이터레이터 리절트 오브젝트엔 value와 done이라는 키워드가 있다.
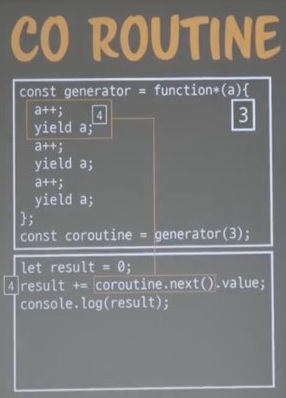
제일 처음 다음부턴 .next()를 활용해 코루틴을 호출.
이를 보면 코루틴이 웬지 객체일거 같다는 생각이 들죠?
맞음. 객체로도 구현 가능하다.