4. ABSTACT LOOP & LAZY EXECUTION
generator - 동기명령을 중간에 멈출 수 있는 기능이 있다. yield (이러한 기능을 suspension이라 한다), 그리고 다시 재진행한다.
이것이 기본사항이 돼서 그걸 바탕으로 루프를 추상화시키는 것, 그리고 LAZY EXCUTION(지연실행)을 배울 것이다.
지연실행이라는 것은 함수의 특권이다.
여러분이 어떤 제어문을 작성했는데, 그 문이 즉시실행되지 않게 하려면 원래는 함수에 담아두고 함수를 호출할 때까지 지연되지?
기본적으로 지연실행이라는 것은 함수호출 지연실행인데, 이걸 함수의 호출 지연말고도 제너레이터를 통해서 지연 시킬 수 있다.
문이 다 실행되지 않고 다시 빠져나올 수 있기 때문에, yield 밑에를 실행시키지 않고 지연시킬 수 있다.
기존에 지연실행이 함수형 프로그래밍의 특징이자 걔네들의 특권으로 여겨졌다면, 코루틴을 지원하는 대부분의 언어에서는 제어문으로 지연실행을 일으킬 수 있다.
기존의 복잡한 함수형 프로그래밍 지연 실행을 지금은 다 제어문으로 실행할 수 있다.
오늘 공부 목표 : 제너레이터의 지연실행 측면, 그리고 이걸 위한 추상루프화
오늘 배우는 내용에는 약간의 디자인 패턴을 포함하고 있는데, 조금 복잡하다. 천천히 살펴보도록 하자.
ABSTRACT LOOP
루프의 추상화.
아니 루프가 루프지 루프를 추상화해? 라고 생각할지도 모르지만, 이미 지난 시간에 이터레이터를 통해 루프를 추상화하는 방법을 공부했다.
루프문을 쓸 때 보다 이터레이터 객체로 바꿔놓으면, 루프를 위한 상태값들을 객체가 갖고 있기 때문에 언제든지 똑같은 루프를 재현할 수 있게 되고, 루프문의 역할이 크게 줄어드는 걸 알 수 있었다.
기존의 제어문은 많은 역할이나 책임을 제어문이 갖고있는데 비해서, 이터레이터를 사용한 경우는, 루프문을 더 돌릴지말지, 루프마다 뭘할지말지, 이런 결정권들이 이터레이터 객체로 넘어가기 때문에 훨씬 더 여러번 똑같은 루프를 제어할 수 있는 루프문을 만들 수 있었다.
이 장점을 본격적으로 이용해보려고 하는 것이다.
이전 시간까지는 이것이 진짜 제어문에 비해서 좋은건가? 아리까리한 상태였다면 이번시간에 좀 더 복잡한 루프를 해결해보자는 것이다.
COMPLEX RESURSION
단순한 배열 루프부터 시작해보자.
{
[Symbol.iterator](){return this;},
data:[1, 2, 3, 4],
next(){
return {
done: this.data.length == 0,
value: this.data.shift()
}
}
}
이터러블과 이터레이터 인터페이스를 떠올려보자.
- 이터러블 인터페이스는
Symbol.iterator메서드를 갖고 있다. - 이터러블 인터페이스는 이터레이터를 반환한다.
[Symbol.iterator](){return this;} - 이터레이터 인터페이스의 조건은
next메서드를 갖고 있어야 한다는 것이다.
위 예시의 객체 자체가next메서드를 갖고 있으므로this를return해도 이터러블 규약에 어긋나지 않는다. next를 호출하면 이터레이터 리절트 오브젝트를 반환한다.
이터레이터 리절트 오브젝트 조건은?
done,value가 있어야 한다.{ done: this.data.length == 0, value: this.data.shift() }
복잡한 다층형 그래프는 어떻게 이터레이션할 것인가?
{
[Symbol.iterator](){return this;},
data: [{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9],
next(){
return ???;
}
}
위와 같이 생기면 어떻게 할 것인가?
ES6 이전과 이후의 객체 리터럴은 차이가 있다.
바로 ‘순서’
ES6 이전엔 객체 리터럴에는 순서가 없다.
순서가 없다는 것은 자바로 따지면 해시맵으로 되어있다는 것이다.
그런데 자바스크립트 ES6 이후부턴 객체 리터럴을 통해서 객체를 선언하면 링크드 해시맵으로 되어있다. 즉, 순서가 있다는 것.
for ... in으로 돌리면 반드시 순서대로 나온다.
여튼 위의 data를 해체하여 next 메서드로 1, 2, 3, 4, -, 5, 6, 7, 8, 9 이렇게 나오게하고 싶다.
이것을 next 메서드로 어떻게 구현할 것인가.
반복문, 제어문은 어렵다. 책에서 만나는 ‘구구단’ 이런거에 현혹되지 마라.
{
[Symbol.iterator](){return this;},
data: [{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9],
next(){
let v;
while(v = this.data.shift()) {
switch (true) {
case Array.isArray(v):
this.data.unshift(...v);
break;
// null 이 아니면서 객체인 경우
case v && typeof v == 'object':
let n = [];
for (var k in v) n.push(v[k]);
this.data.unshift(n);
break;
default:
return {value:v, done:false};
}
}
return {done: true};
}
}
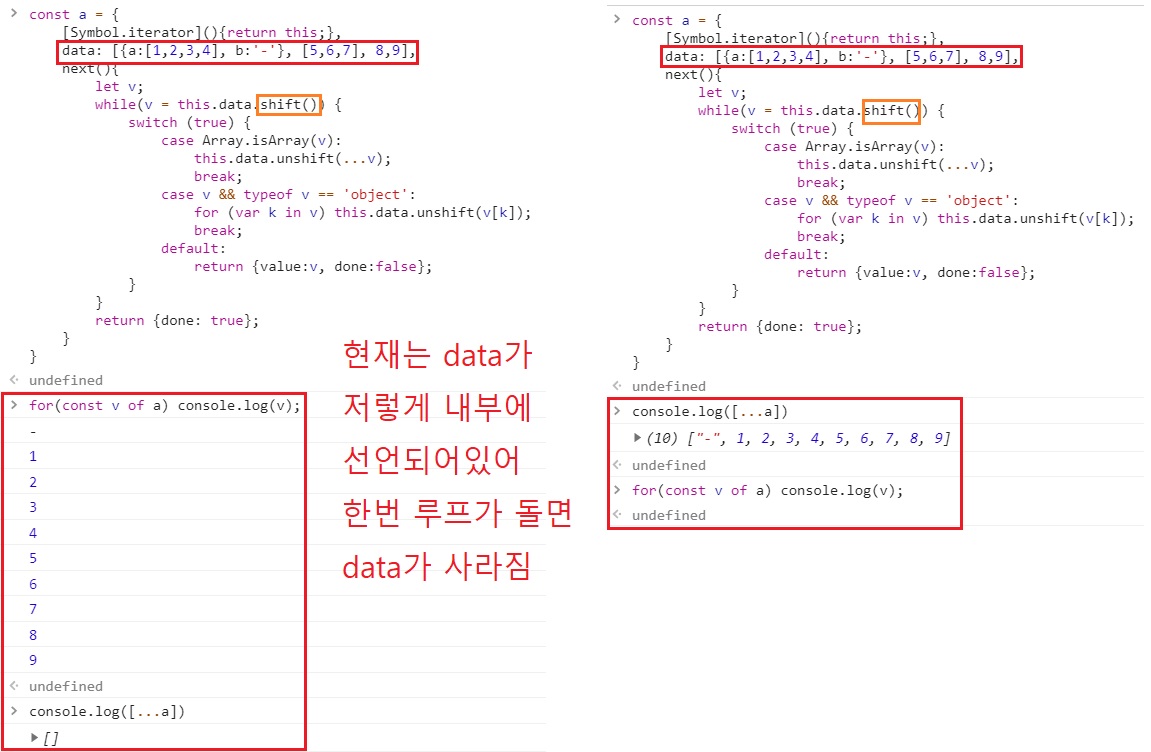
 —
—
{
[Symbol.iterator](){return this;},
data: [{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9],
next(){
let v;
// 아래에 안전장치를 걸어줘야 한다!! max 같은!!
while(v = this.data.shift()) {
switch (true) {
case Array.isArray(v):
this.data.unshift(...v);
break;
// null 이 아니면서 객체인 경우
case v && typeof v == 'object':
let n = [];
for (var k in v) n.push(v[k]);
this.data.unshift(n);
break;
default:
return {value:v, done:false};
}
}
return {done: true};
}
}
조금 더 어려운 루프 형태이다.
기존 루프를 돌릴 때, i=0 이런 조건이 아닌, 데이터에 대한 판정이다.
그리고 그런 데이터에 대한 판정이 런타임에서 계속 바뀐다.
왜 이렇다? 데이터의 삽입이 일어나기 때문이다.
이런 이유 때문에 지난번에 max 조건 같은 안전장치를 하나 걸라고 했었다.
이런 런타임 평가를 하면 루프문이 무한히 돌 가능성이 있기 때문이다.
여튼 위와 같이 짜면 data 형태가 어떻게 들어오든 전부 해체해버린다.
그런데 이렇게 짜면 컴퓨터가 느리지 않을까?
컴퓨터는 반복의 제왕이다.
우리는 컴퓨터와 반복을 경쟁할 수 없다.
여러분들이 어지간히 여러분들의 코드를 개선해도 10만번 돌려서 1/1000 밀리초 땡기기도 쉽지 않다.
컴퓨터는 원래 너무 빠르다.
여러분들의 비효율성을 흡수할 수 있을 정도로 빠르다.
그래서 알고리즘에 너무 욕심 안내도 된다.
컴퓨터 프로그래머 초보가 가장 많이 하는 실수, 어떻게하면 로직 하나라도 더 줄일 수 있을까? 에 대한 노력을 많이한다.
알고리즘 퀴즈에선 당연히 중요하다. 하지만 실무에서는 문제가 더 정확히 해결되는 것이 중요하다.
코드스피츠 73확인, 위의 식에서 오류가 있다고함. 그 오류를 알아내서 수정하는 것이 과제.
힌트 : data의 a의 값을 3 또는 7과 같은 값으로 바꾸면 알 수 있다는데…
음… 글쎄.. 난 모르겠는데.. 여튼 코드스피츠 73을 참고해야겠다..
위의 코드는 복잡한 것중에 가장 단순한 것이다.
위의 코드가 조금만 더 복잡해지면 문제가 발생한다.
디버깅이 안된다.
디버깅을 해도 루프 27번째에 걸리거나 그런다.
또한 생각할 조건이 더 많아지면 조건문을 어떻게 처리할 것인가?
case가 더 많아진다면?
사람이 감당할 수 있을까?
아무도 감당 못한다.
따라서 코드를 위와 같이 짤 수는 없다는 것이다.
그렇다면 ES6의 힘을 이용해서 약간 더 줄여보자.
위의 코드를 정리하면 아래와 같이 정리가 된다.
{
[Symbol.iterator](){return this;},
data: [{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9],
next(){
let v;
// 아래에 안전장치를 걸어줘야 한다!! max 같은!!
while(v = this.data.shift()) {
// Object의 instance가 아닌 애들 : Number, String, Boolean, NaN, undefined 즉, primitive value 원시값(기본값)
// null은 안타깝게도 Object - ES6에서도 과거와의 호환성 때문에 수정 안함
// 그렇기 때문에 앞에 !v && 조건을 더 붙인 것 - falsy 인 값들은 Object일리가 없기 때문에 이렇게만 적으면 된다.
// 첫줄 if문의 return값에 done 키 안 넣음 -> undefined. done은 truthy, falsy 값이면 된다.
// 첫줄에서 원시값(기본값) 처리
if (!v && !(v instanceof Object)) return {value:v};
// 두번째 줄에서 배열인지 아닌지를 판정
// 배열이 아닌 애들을 먼저 솎아낸다.
// 왜? 보다 추상 계층인 애를 먼저 보는 것이다. 구상 계층은 밑에 내릴려고..
// 배열이 아닌 애들은 Object.values라는 ES6 이후 도입된 메서드를 사용해 Object에서 value만 모아서 배열로 만들어준다.
if (!Array.isArray(v)) v = Object.values(v);
// 배열이 아닌것도 위에서 Object.values 메서드로인해 다 배열로 바뀌었으므로
// 아래 식에서 다시 해체 할당된다.
this.data.unshift(...v);
}
return {done: true};
}
}

코드 커버리지라는 개념이 중요
우리가 코드를 짜고 테스트를 할 때 단위 테스트라는 개념이 있다.
다양한 데이터 종류를 준비하고 나눠서 단위 테스트를 하는데, 단위테스트를 할 때 유의할 점이 뭐냐면, 단위 테스트 케이스를 1000개를 만들고, 2000개를 만들고가 중요한 것이 아니라, 코드 커버리지라는 개념이 굉장히 중요하다.
크롬 개발자창(dev tool) 보시면 coverage 라는 탭이 있다.
이 창에서 보면 왼쪽에 초록색 빨강색이 표시된다.
이것이 의미하는 게 뭐냐면, 내가 짠 코드 중에 사용된 줄과 사용되지 않은 줄들을 표시해놓은 것이다.
즉, 빨강색이 없고 모두 다 초록색이 되도록, 그것을 코드 커버리지 100%라고 한다.
사용되지 않는 코드를 제거하는 것이 중요~! —
{
[Symbol.iterator](){return this;},
data: [{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9],
next(){
let v;
// 아래에 안전장치를 걸어줘야 한다!! max 같은!!
while(v = this.data.shift()) {
switch (true) {
case Array.isArray(v):
this.data.unshift(...v);
break;
// null 이 아니면서 객체인 경우
case v && typeof v == 'object':
let n = [];
// 여기서도 실수 하나 있다.
// if (v.hasOwnProperty()) 를 안 넣어준 것이 실수다.
for (var k in v) n.push(v[k]);
this.data.unshift(n);
break;
default:
return {value:v, done:false};
}
}
return {done: true};
}
}
여튼 코드가 확 줄었다.
코드가 확 줄어든 이유는 복잡한 처리를 해주는 메서드들이 이미 존재하기 때문~!
위의 코드에도 실수가 있다.
if (v.hasOwnProperty()) 이것을 안 넣은 것이 실수다.
for … in 반복문은 proto type에 있는 key까지 다 나오기 때문에 반드시 옆에 hasOwnProperty를 걸어줘야 한다.
{
[Symbol.iterator](){return this;},
data: [{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9],
next(){
let v;
// 아래에 안전장치를 걸어줘야 한다!! max 같은!!
while(v = this.data.shift()) {
// Object의 instance가 아닌 애들 : Number, String, Boolean, NaN, undefined 즉, primitive value 원시값(기본값)
// null은 안타깝게도 Object - ES6에서도 과거와의 호환성 때문에 수정 안함
// 그렇기 때문에 앞에 !v && 조건을 더 붙인 것 - falsy 인 값들은 Object일리가 없기 때문에 이렇게만 적으면 된다.
// 첫줄 if문의 return값에 done 키 안 넣음 -> undefined. done은 truthy, falsy 값이면 된다.
// 첫줄에서 원시값(기본값) 처리
if (!v && !(v instanceof Object)) return {value:v};
// 두번째 줄에서 배열인지 아닌지를 판정
// 배열이 아닌 애들을 먼저 솎아낸다.
// 왜? 보다 추상 계층인 애를 먼저 보는 것이다. 구상 계층은 밑에 내릴려고..
// 배열이 아닌 애들은 Object.values라는 ES6 이후 도입된 메서드를 사용해 Object에서 value만 모아서 배열로 만들어준다.
if (!Array.isArray(v)) v = Object.values(v);
// 배열이 아닌것도 위에서 Object.values 메서드로인해 다 배열로 바뀌었으므로
// 아래 식에서 다시 해체 할당된다.
this.data.unshift(...v);
}
return {done: true};
}
}
하지만 위에 식은 이미 그런 기능을 모두 내재하고 있다.
자기 자신의 프로퍼티만 나온다.
그래서 자바스크립트 언어는 두 가지로 되어있다.
- 언어 자체의 문법적인 내용으로 되어 있다.
- 모든 언어가 그러하듯이 class library로 되어있다.
자바스크립트의 클래스 라이브러리는 코어 객체라고 알려져 있는데, 코어 객체에는 무엇이 있을까?
- Math, Object, Array, Function, Date, Regular Expression… 등등
이들은 표준으로 제공되고 있는 언어 표준의 일부이다.
자바스크립트 for, while 문들이 표준인 것 처럼 자바스크립트가 코어 객체로 제공하고 있는 것들은 Node가 되었건 뭐가 되었건 다 갖고 있어야되는 표준 객체이다.
이 코어 객체도 언어 스펙의 일부이다.
그럼 위의 Object.values도 언어 스펙의 일부겠지?
임의대로 이를 우리가 쓰고싶으면 쓰고, 안 쓰고 싶으면 안 쓰고가 아니라, 언어 스펙의 일부이기 때문에, 이 기능과 부합하면 당연히 언어 스펙에 있는 애를 우선적으로 써야한다.
그래야 에러가 적고 더 바르게 동작한다.
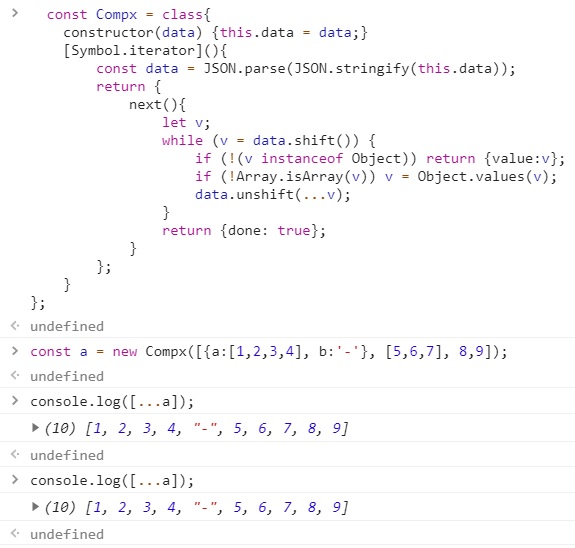
const Compx = class{
constructor(data) {this.data = data;}
[Symbol.iterator](){
const data = JSON.parse(JSON.stringify(this.data));
return {
next(){
let v;
while (v = data.shift()) {
if (!(v instanceof Object)) return {value:v};
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
return {done: true};
}
};
}
};
const a = new Compx([{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9]);
console.log([...a]);
console.log([...a]);
ERROR!
음.. 위에서 while(v= data.shift()) 이 구문.. 어짜피 이렇게하면 undefined나 null값이면 끝나는거아냐?? 그럼 데이터로 들어가는 값에 null이나 undefined 값이 있으면 while문으로 가지않고 바로 done:true 리턴되면서 끝날텐데.. 그럼 while문 안에서 null값을 처리해줄 필요도 없고..? 흐음…. 여튼 이는 다음에 다시 생각해보도록 하고 다시 돌아가자.
const Compx = class{
constructor(data) {this.data = data;}
[Symbol.iterator](){
const data = JSON.parse(JSON.stringify(this.data));
return {
next(){
let v;
while (v = data.shift()) {
if (!(v instanceof Object)) return {value:v};
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
return {done: true};
}
};
}
};
const a = new Compx([{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9]);
console.log([...a]);
console.log([...a]);
자바스크립트 3.1 시대에도 우리가 함수를 정의할 때 2가지 스타일이 있다.
함수 표현식, 함수 선언문.
그런데 이때도 함수 선언문은 사용하지 말고 표현식을 사용하라는 말 들어본적 있나?
기본적으로 자바스크립트에서 함수는 ‘값’이기 때문에 함수를 선언하지 않고 표현식으로 사용하는 것이 맞다.
그래야지 호이스팅 같은 거에 의존하지 않고, 어느 시점에 함수가 만들어졌는지를 코드로 명확하게 인지할 수 있기 때문에 함수 선언문은 아예 금지시키고 못 쓰게하는 경우도 많다.
린트에도 그런 룰이 있다.
마찬가지로 자바스크립트의 클래스도 값이다.
변수에 할당이 된다.
그래서 class ‘문’을 쓰려고하는 그 자체가 이 클래스가 언제 생성된 것인지 모호하게 만든다.
그런데 함수 선언문처럼 변수에 클래스 값을 할당하면 내가 정확하게 어느 시점에 이 클래스를 만들었는지를 알 수 있게 된다.
그래서 클래스도 마찬가지로
class className {
}
이렇게 하는 것 보다는
const className = class {
}
이렇게 변수에다가 클래스를 할당하는 것이 좋다.
여러분들이 여지껏 많이 봐온 문법은 당연히
class className {
}
이거 겠지만, 여기서 질문.
위의 className 은 let일까, const일까?
위의 className에 다른 값을 할당할 수 있나?
할 수 있다. let이기 때문.
이것부터도 벌써 헷갈린다.
어떤면에서 봐도 문법적으로 변수에 할당하는 것이 훨씬 더 정확하기 때문에 해당 방법을 추천드린다.
const Compx = class{
constructor(data) {this.data = data;}
[Symbol.iterator](){
const data = JSON.parse(JSON.stringify(this.data));
return {
next(){
let v;
while (v = data.shift()) {
if (!(v instanceof Object)) return {value:v};
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
return {done: true};
}
};
}
};
const a = new Compx([{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9]);
console.log([...a]);
console.log([...a]);
위 class는 생성자로 data를 받아 this.data로 잡아놓는다.
그리고 이터레이터에서, 이 data가 컴플렉스 데이터라고 생각한다면, 배열이 아니니깐 slice()으로 할 수도 없고, Object.assign을 해도 깊은 카피가 아니라 얕은 카피만 해주기 때문에.. 그러면 안되잖아?
그렇다면 이 data가 순수한 객체라고 생각한다면(함수도 없고, 특별한 객체도 없고), 우리가 json처럼 순수하게 인식할 수 있는 data로만 되어있는 객체라고 생각을 한다면, 이 data를 복사하는 가장 빠른 방법은
const data = JSON.parse(JSON.stringify(this.data));
이것이다.
완전히 새롭게 복사가되고, 완전히 똑같게 복사가 된다.
완전한 복사, - 깊은 복사보다 훨씬 빠르다. - 왜? - stringify, parse는 C가 하기 때문.
즉, 몇번이고 이터레이터를 호출해도 원본 data는 손상이 없다. 항상 사본을 사용하기 때문.
이렇게 하기위해 Symbol.iterator를 한 번 호출하고 이터레이터를 받는 것이다.
사본인 자율변수를 사용하기 위해 next 함수를 생성.
const Compx = class{
constructor(data) {this.data = data;}
[Symbol.iterator](){
const data = JSON.parse(JSON.stringify(this.data));
return {
// ES6는 아래와 같은 구조를
// function을 생략하고 next(){} 이런식으로 쓸 수 있다.
// 때문에 해당 함수 안에선 this 사용가능하고 해당 this는 return한 객체를 가리킨다.
// 아래에서는 this는 안쓰고있지만.. 자율 변수 data만 쓰고있지만.
next: function(){
let v;
while (v = data.shift()) {
if (!(v instanceof Object)) return {value:v};
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
return {done: true};
}
};
}
};
const a = new Compx([{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9]);
console.log([...a]);
console.log([...a]);
const Compx = class{
constructor(data) {this.data = data;}
[Symbol.iterator](){
const data = JSON.parse(JSON.stringify(this.data));
return {
// ES6는 next: function(){}을 next(){} 이런식으로 쓸 수 있다.
// 때문에 해당 함수 안에선 this 사용가능하고 해당 this는 return한 객체를 가리킨다.
// 아래에서는 this는 안쓰고있지만.. 자율 변수 data만 쓰고있지만.
next(){
let v;
while (v = data.shift()) {
if (!(v instanceof Object)) return {value:v};
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
return {done: true};
}
};
}
};
const a = new Compx([{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9]);
console.log([...a]);
console.log([...a]);
- 이터러블
- 이터레이터
- 아주 복잡한 루프
- json 데이터 아무거나 와도 상관X
여기서 한 가지 더~!
const Compx = class{
constructor(data) {this.data = data;}
[Symbol.iterator](){
const data = [JSON.parse(JSON.stringify(this.data))];
return {
next(){
let v;
// 그렇다면 받아들이는 data가 배열일 때만 아래가 처음을 성립하잖아?
// data가 배열로 시작해야만 shift로 맨앞에 추출하면서 시작할 수 있다.
// shift는 배열이어야 가능한 메서드
// 그래서 제일 안전하게는 위의 사본(data)에다가 대괄호를 씌우고 시작하는 것이다.
// 이 예제가 배열을 받아들여서 뻑이 안 났지만 Object를 받아들였으면 뻑이 났을 거다.
while (v = data.shift()) {
// 그리고 아래 if문 코드는 읽기가 굉장히 어려운 코드다
if (!(v instanceof Object)) return {value:v};
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
return {done: true};
}
};
}
};
const a = new Compx([{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9]);
console.log([...a]);
console.log([...a]);
이터러블은 제너레이터로 쉽게 줄일 수 있다는 것을 모두 알 것이다.
위 소스도 급격하게 줄일 수 있다.(쓸 데 없는 구조물들을 줄일 수 있다)
아래 소스 참고.
제너레이트 : 이터레이터 리절트 오브젝트를 만들어 줄 것이고, 이터레이터를 만들어주는 이터러블도 필요 없을 것이고.
왜냐면 우리는 제너레이트를 호출해서 이터레이터를 만들 것이기 때문.
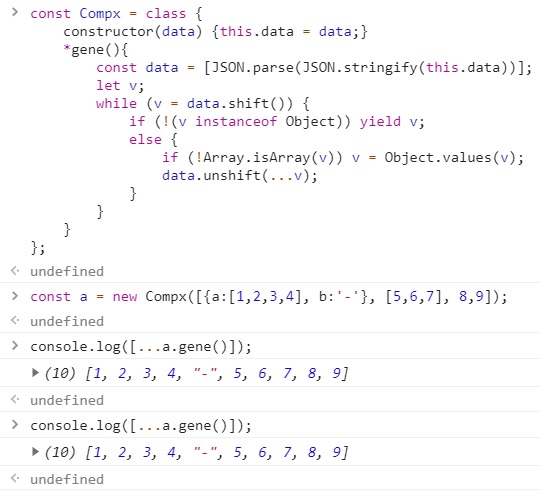
const Compx = class {
constructor(data) {this.data = data;}
*gene(){
const data = [JSON.parse(JSON.stringify(this.data))];
let v;
while (v = data.shift()) {
// if일 때와 else일 때를 명확하게 분리
// 객체인 경우와 아닌 경우
if (!(v instanceof Object)) yield v;
else {
// 객체인 경우 중에서 배열인 경우와 아닌 경우
// 배열이 아니라면 배열로 만들고,
if (!Array.isArray(v)) v = Object.values(v);
// 언제나 unshift하는 mandatory(필수) 로직이 옴
data.unshift(...v);
}
}
}
};
const a = new Compx([{a:[1,2,3,4], b:'-'}, [5,6,7], 8,9]);
console.log([...a.gene()]);
console.log([...a.gene()]);
NOTE - 읽기 쉬운 if 문
if 문 - mandatory(필수), optional(선택) 누가봐도 명확하게 작성해야된다.
잘짠 코드는 주석이 필요없다.
잘짠 코드는 주석보다 좋다.
주석은 괜히 오해를 불러일으킨다.
우리의 코드는 readable하기 때문에 읽기하면 하면 된다.
그렇다면 우리는 코드를 readable하게 짰는가? 가 문제인 것.
알고리즘은 항상 어렵기 때문에 그런 어려운 알고리즘을 주석으로 해결하려고 하지 말아라.
주석은 오해만 만든다.
코드는 우리편이지만 주석은 우리의 적이다.
코드 개발자가 주석을 제대로 작성해놨을 거란 기대를 버려라.
그나마 코드는 작성하면 컴파일러 도중에 잡아내기라도 한다. 주석은 누가 잡아낼건데?
ABSTRACT LOOP
위에서 본 루프는 ‘목적이 있는 루프’이다.
목적이 있는 루프를 만들면, 목적을 살짝 바꾸면 루프를 다시 짜야된다.
(data, f) => {
let v;
while(v = data.shift()){
// data의 원소마다 f함수 호출
if (!(v instanceof Object)) f(v);
else {
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
}
}
(data, f) => {
let v;
while(v = data.shift()){
// data의 원소마다 f함수 호출
if (!(v instanceof Object)) {
// console.log로 v찍어보고 싶다면 이렇게 소스를 바꿔줘야됨
// 겨우 console.log()로 찍어보고 싶었을 뿐이었는데, 새로 복사 붙여넣기 함, 왜?
// 제어'문'이기 때문에 그냥 다시 복사할 수밖에는 없는 것
// 고작 console.log 때문에 완전히 똑같은 함수를 복붙해야돼? 다른 방법 없어? 네, 없습니다.
console.log(v);
f(v);
} else {
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
}
}
이것이 ‘제어문’을 그냥 사용했을 때의 가장 큰 문제점이다.
여러분들은 구구단을 짤 줄 알지만, 구구단 사이사이 구분선을 넣으려면 똑같은 구구단 로직을 한번 더 짜야된다.
그 외 방법은 없다.
모든게 ‘문’으로 확정되어있기 때문.
그런데 어떻게 구조만 남길까?
재활용을 해야된다. - 그런데 문은 실행되면 사라지는 것. 얘를 어떻게 객체화해서 재활용하지?
- 결국 제어문을 직접 사용할 수 없고 구조 객체를 이용해 루프실행기를 별도로 구현하는 방법을 활용한다.
루프를 처리해주는 객체 시리즈를 만들어 놓고 여기에다 값을 넣거나 이 값을 이용하는 쪽을 따로 분리해주는 작업이다.
(data, f) => {
let v;
while(v = data.shift()){
if (!(v instanceof Object)) {
f(v);
} else {
if (!Array.isArray(v)) v = Object.values(v);
data.unshift(...v);
}
}
}

if 문은 제거할 수가 없다.
하지만 if 문을 다 제거하고싶어한다.
어떻게 if문을 제거할까?
if로 나뉘어지는 경우의 수만큼의 값을 미리 만들어놓고 바깥쪽에서 그 값을 선택해서 들어오게할 수밖에 없다.
이렇게 하면 안쪽에 if 조건의 하나가 사라진다.
이걸 겹겹이 쌓으면 if문을 하나씩 제거해나갈 수 있다.
위의 식에서 if가 세개가 나왔다.
원시값 / 객체 / 배열
이 세 개만큼의 객체를 미리 설정, 그리고 이것을 바깥쪽에서 선택하게 한다.
그렇게 하면 if문 하나를 제거할 수 있다.
이것이 디자인패턴 원리이다. 전략객체 패턴, 상태 패턴 등등..
ABSTRACT LOOP (추상루프) - 팩토리 + 컴포지트
// 팩토리
const Operator = class {
static factory(v){
if (v instanceof Object) {
if (!Array.isArray(v)) v = Object.values(v);
return new ArrayOp(v.map(v => Operator.factory(v)));
}else return new PrimaOp(v);
}
constructor(v) {this.v = v;}
operation(f) {throw 'override';}
};
// 컴포지트
const PrimaOp = class extends Operator{
constructor(v) {super(v);}
operation(f){f(this.v);}
}
const ArrayOp = class extends Operator {
constructor(v) {super(v);}
// 아래의 v.operation(f) 는 Operator.factory([1,2,3, {a:4, b:5}, 6, 7]).operation(console.log) 이거라고 보면 되는걸까?
operation(f){for (const v of this.v) v.operation(f);}
}
Operator.factory([1,2,3, {a:4, b:5}, 6, 7]).operation(console.log)
이렇게 하면 if를 늘려나가지 않고 분기 처리만 한 다음에, 그 후 객체를 늘려나가는 식으로 if를 해결할 수 있게 되었다.
원시값을 한번에 처리하는 게 아닌 스트링 처리기는 따로 나누고 싶어~!
그럼 아래와 같이 분기처리하고 객체 선언하면 된다.
이것이 if문을 줄이는 유일한 방법이다.
아키텍쳐도 다 이거하려고 하는 것이다.
if가 감당이 안되기 때문이다.
그리고 if는 ‘문’이기 때문에 확정인데 비해서, 객체는 ‘동적’으로 추가할 수 있다.
앞에꺼 하나도 안 건드리고 객체만 추가하면 된다. 후기 확장 용이, 플러그인.. 애드온 형태 다 이걸 활용
// 팩토리
const Operator = class {
static factory(v){
if (v instanceof Object) {
if (!Array.isArray(v)) v = Object.values(v);
return new ArrayOp(v.map(v => Operator.factory(v)));
}else return typeof v === "string" ? new StringOp(v) : new PrimaOp(v);
}
constructor(v) {this.v = v;}
operation(f) {throw 'override';}
};
// 컴포지트
const StringOp = class extends Operator{
constructor(v) {super(v);}
operation(f){for (const a of this.v) f(a)}
}
const PrimaOp = class extends Operator{
constructor(v) {super(v);}
operation(f){f(this.v);}
}
const ArrayOp = class extends Operator {
constructor(v) {super(v);}
// 아래의 v.operation(f) 는 Operator.factory([1,2,3, {a:4, b:5}, 6, 7]).operation(console.log) 이거라고 보면 되는걸까?
operation(f){for (const v of this.v) v.operation(f);}
}
Operator.factory([1,2,3, {a:'abc', b:5}, 6, 7]).operation(console.log)
라우터
// 여기에는 로직이 복잡하게 있어서 별도로 선택하는 팩토리가 필요했지만, 이걸 일반적으로 선택할 수 있게 하면 뭐가된다?
// 라우터라는 것이 되는 것이다.
// 이런식으로 짜면 수많은 url을 처리해야되는 웹사이트에서 if문으로 url이 추가될 때마다 새로 if문을 추가한 후 컴파일 하지 않아도 된다.
// 이런식으로 짜면 라우터 로직에 의해서 등록되어 있는 애들 중에 누군가를 찾으려고 할 테고,
// 그 등록된 애들은 계속 등록하면서 만들어나가기만 하면 되는 것.
// 여튼 팩토리가 일반화되면 라우터가 되는 것이고, (현재 아래 예제는 일반화가 될 수 없음. 값을 동적으로 여러가지 평가하고 있기 때문)
// 이런 경우는 팩토리를 활용해서 선택적으로 만들어내는 객체를 도와줘야 하는 것.
// 팩토리
const Operator = class {
static factory(v){
if (v instanceof Object) {
if (!Array.isArray(v)) v = Object.values(v);
return new ArrayOp(v.map(v => Operator.factory(v)));
}else return typeof v === "string" ? new StringOp(v) : new PrimaOp(v);
}
constructor(v) {this.v = v;}
operation(f) {throw 'override';}
};
// 컴포지트
const StringOp = class extends Operator{
constructor(v) {super(v);}
operation(f){for (const a of this.v) f(a)}
}
const PrimaOp = class extends Operator{
constructor(v) {super(v);}
operation(f){f(this.v);}
}
const ArrayOp = class extends Operator {
constructor(v) {super(v);}
// 아래의 v.operation(f) 는 Operator.factory([1,2,3, {a:4, b:5}, 6, 7]).operation(console.log) 이거라고 보면 되는걸까?
operation(f){for (const v of this.v) v.operation(f);}
}
Operator.factory([1,2,3, {a:'abc', b:5}, 6, 7]).operation(console.log)
ABSTRACT LOOP
팩토리 + 컴포지트 + ES6 iterable
const Operator = class {
static factory(v) {
if (v instanceof Object) {
if (!Array.isArray(v)) v = Object.values(v);
return new ArrayOp(v.map(v => Operator.factory(v)));
} else return new PrimaOp(v);
}
constructor(v) {this.v = v;}
*gene() {throw 'override';}
};
const PrimaOp = class extends Operator {
constructor(v) {super(v);}
*gene(){yield this.v;}
};
const ArrayOp = class extends Operator {
constructor(v) {super(v);}
*gene(){for (const v of this.v) yield * v.gene();}
};
for (const v of Operator.factory([1,2,3,{a:4, b:5}, 6, 7]).gene()) console.log(v)
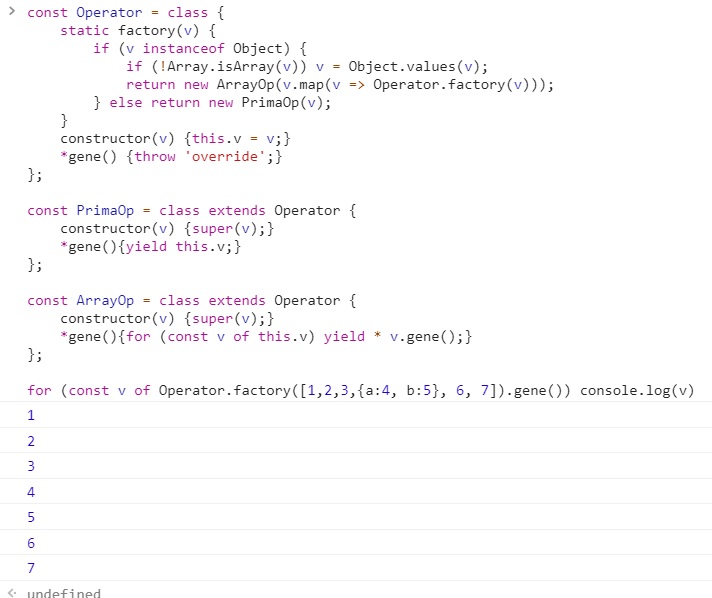
위의 제너레이터는 이전 식과는 다르다.
이전 식은
// 팩토리
const Operator = class {
static factory(v){
if (v instanceof Object) {
if (!Array.isArray(v)) v = Object.values(v);
return new ArrayOp(v.map(v => Operator.factory(v)));
}else return typeof v === "string" ? new StringOp(v) : new PrimaOp(v);
}
constructor(v) {this.v = v;}
operation(f) {throw 'override';}
};
// 컴포지트
const StringOp = class extends Operator{
constructor(v) {super(v);}
operation(f){for (const a of this.v) f(a)}
}
const PrimaOp = class extends Operator{
constructor(v) {super(v);}
operation(f){f(this.v);}
}
const ArrayOp = class extends Operator {
constructor(v) {super(v);}
operation(f){for (const v of this.v) v.operation(f);}
}
// operation 메서드를 통해 우리가 해야될 것들을 각 객체에 정의했다.
// 이렇게 하기 싫다면?
// operation 에 해당하는 애들을 generator에게 미루면 된다.
Operator.factory([1,2,3, {a:'abc', b:5}, 6, 7]).operation(console.log)
const Operator = class {
static factory(v) {
if (v instanceof Object) {
// Object.values - hasOwnProperty 까지 다 처리되어있다.
if (!Array.isArray(v)) v = Object.values(v);
return new ArrayOp(v.map(v => Operator.factory(v)));
} else return new PrimaOp(v);
}
constructor(v) {this.v = v;}
*gene() {throw 'override';}
};
const PrimaOp = class extends Operator {
constructor(v) {super(v);}
// yield 값을 반환하고 중지
*gene(){yield this.v;}
};
const ArrayOp = class extends Operator {
constructor(v) {super(v);}
// yield * 다음 나오는 걸 전부 yield 처리한 후 그 다음 문으로 넘어간다.
// v.gene() 도 이터러블 객체
// 즉 아래 for 루프가 돌려면 각각 v마다 다 돌고 그 다음 v로 넘어간다.
*gene(){for (const v of this.v) yield * v.gene();}
};
// 그 덕분에 for 루프 안에다 제너레이터를 넣을 수 있게 되었다.
// 아까처럼 operation처럼 특수 구문을 만들어 실행시킨 것이 아닌 자바스크립트 표준 문법을 수용해서 작성하면 된다.
for (const v of Operator.factory([1,2,3,{a:4, b:5}, 6, 7]).gene()) console.log(v)
함수 객체를 받지 않고 제어문을 추상화하는 데 성공했다.
그 덕분에 우리는 똑같은 제어 구조 안에서 매번 문을 다시 만들어야 했는데(operation), 이제 맨 뒤의 문만 바꿔주면 되게 되었다.
위 제너레이터를 rest로도 쓸 수 있고 spread로도 쓸 수 있고..
우리가 했던 추상 루프의 완성이다.
LAZY EXECUTION
자바스크립트는 자바스크립트이다.
언어를 컴파일해서 컴퓨터에 전달하고 그런건 다 C가 한다.
C 개발자들이 언젠간 그 속도를 빠르게 해준다.
지금 잠깐 제너레이터가 느려도 브라우저가 빠른시간내에 이긴다.
최신 제안대로 짜는 게 무조건 좋다.
하지만 자바스크립트 코드로 DOM을 다루는 코드를 최적화하는 것은 굉장히 의미가 있다.
개발자 창 - 프로파일링 - 어느 브라우저나 예외없이 97% 랜더링으로 나온다.
여러분들이 짠 코드가 최적화되던 말던 3%이다.
두배 빠르게 짰다고하더라도 1.5% 빨라지는 것이다.
그렇지만 DOM을 최적화하면?
97%의 5%만 최적화해도 4.xx%가 빨라지는 것.
즉, 일반적인 최적화는 랜더링에 달려있다. 이런 자바스크립트 알고리즘에 달려있는 것이 아니다.
즉, 자바스크립트는 내장된 언어 스팩을 무조건 가져다 쓰는 것이 좋다. 스크립트 언어를 바라보는 관점은 주어진 클래스 라이브러리를 최대한 활용하는 것이다.
자바 같은 언어들은 직접 짠 것들이 내장 객체와 속도가 동일하게 할 수도 있지만 자바스크립트는 그게 아니다.
무조건 V8 엔진 내장 객체가 훨씬 더 빠르다.
무조건 랜더링 개선에 달렸다.
오히려 속도 개선보다 구조적인 개선에 초점을 맞춰야 한다.
프로그램 구조적 문제는 대부분 if가 복잡해지는 것에 있어 발생한다.
어떻게하면 if 중첩을 줄일까?
한 단계 if를 줄일 때마다 if가 가지고 있는 모든 경우의 수만큼의 객체를 만든 다음에 그 객체를 선택한 선택기를 바깥으로 빼면, 선택기를 확장하면서 로직들은, 개별 객체로 넘어가기 때문에, 복잡성이 한 단계 줄어든다.(그래봤자 한 단계지만..)
if 중첩이 3번이면 그런 행동을 3단계나 해야된다.
전략객체가 그 전략객체를 소비하고 그 전략객체가 또 다른 전략객체를 소비하고..
안타깝지만 아키텍처상 방법은 이것 뿐이다.
EXCUTION을 LAZY하게
const odd = function*(data) {
for (const v of data) {
console.log("odd", odd.cnt++);
// 나머지 구하는 식은 양의 정수만 된다.
// 따라서 절대값으로 계산한다.
if (Math.abs(v) % 2) yield v;
}
};
odd.cnt = 0;
for (const v of odd([1,2,3,4])) console.log(v)
일단 lazy하게 하는 방법 중 하나가 yield였다.
yield를 하면, 필요한 만큼만 루프를 돌릴 수 있다.
그 예를 보자.
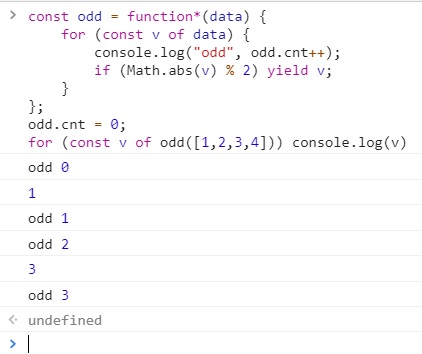
당연하게도 위 루프는 빠져나오라는 말이 없으므로 전부 다 돌고 빠져나온다.
const take = function*(data, n) {
for (const v of data) {
console.log("take", take.cnt++);
if (n--) yield v; else break;
}
};
take.cnt = 0;
for (const v of take([1,2,3,4], 2)) console.log(v);
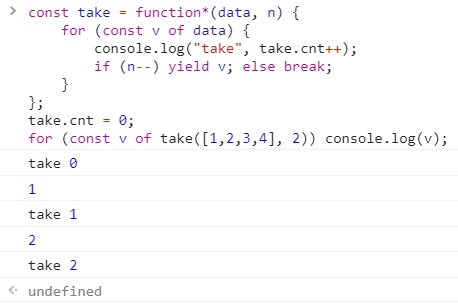
take란 함수는 n 값으로 루프를 몇번 돌게할지를 제어.
위에 두 개를 결합하고 싶다. 홀수인데 두 개만 찾아라.
- 상태를 이용하난 방법이 먼저 떠오를 것이다.
홀수를 먼저 걸러내 배열을 만든 다음 그 중에 2개를 골라내라.
하지만 이게 과연 효율적인 방법일까? - 루프를 돌려서 첫번째 홀수를 찾아내 -> take가 가져가고
루프를 돌려서 두번째 홀수를 찾아내 -> take가 가져가고 종료.
이렇게 하면 루프가 아주 효율적일 것이다.
2번 방법으로 할 때 루프를 돌리다가 멈출 수 있나?
코루틴은 된다. 멈출 수 있다.
그럼 루프를 돌리다가 조건 충족하면 멈춰, 언제? yield일 때.
const odd = function*(data) {
for (const v of data) {
console.log("odd", odd.cnt++);
// 나머지 구하는 식은 양의 정수만 된다.
// 따라서 절대값으로 계산한다.
if (Math.abs(v) % 2) yield v;
}
};
odd.cnt = 0;
const take = function*(data, n) {
for (const v of data) {
console.log("take", take.cnt++);
if (n--) yield v; else break;
}
};
take.cnt = 0;
for (const v of take(odd([1,2,3,4]), 2)) console.log(v);
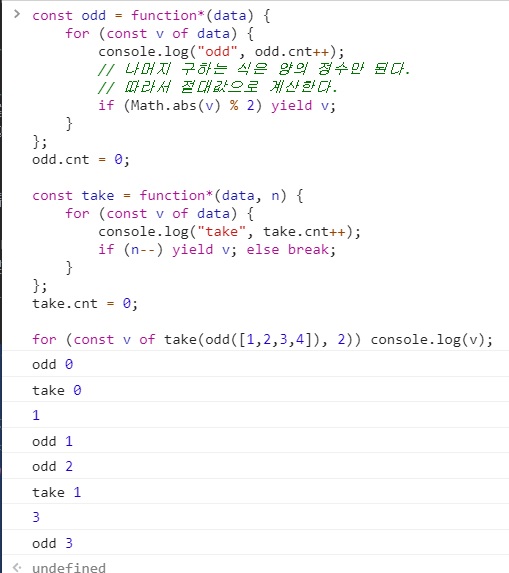
상태로 루프를 만들면 이렇게 못돌린다.
상태로 루프를 만들면 전체 홀수를 한번 걸러내주고 그 다음에 두가지를 골라야되는 식으로 짤수밖에 없다.
배열이 2000개여도 루프를 몇번 반복 안하고 끝낼 수 있다.
이것이 코루틴의 서스펜션을 이용한 것이다.
즉, 제어문이 실행되다가 멈출 수 있다는 성질을 이용한 것이다.
효율성 증대
위에서 yield와 yield를 체인했다.
그렇다는 말은 n개를 체인할 수 있다는 말이다.
stream
우리는 stream이라는 것으로 쭉 제너레이터를 연결할 수 있다.
이것이 바로 자바 8에 나오는 스트림의 개념이자, 일반적으로 함수형 언어에서 스트림이라고 얘기하는 개념이다. 이 때는 함수의 힘으로 구현하는데, 우리는 함수의 힘이 필요 없다고 했지?
지연실행을 제어문으로 구현할 수 있기 때문이다.
function 호출을 늦게 해서 지연시킬 필요가 없다.
제너레이터의 yield를 활용해 하면 된다.
제너레이터 문만으로 지연실행을 일으켜서 stream을 연결할 수 있다.
const odd = function*(data) {
for (const v of data) {
console.log("odd", odd.cnt++);
// 나머지 구하는 식은 양의 정수만 된다.
// 따라서 절대값으로 계산한다.
if (Math.abs(v) % 2) yield v;
}
};
odd.cnt = 0;
const take = function*(data, n) {
for (const v of data) {
console.log("take", take.cnt++);
if (n--) yield v; else break;
}
};
take.cnt = 0;
for (const v of take(odd([1,2,3,4]), 2)) console.log(v);
방금 위에서 본 소스가 스트림이다.
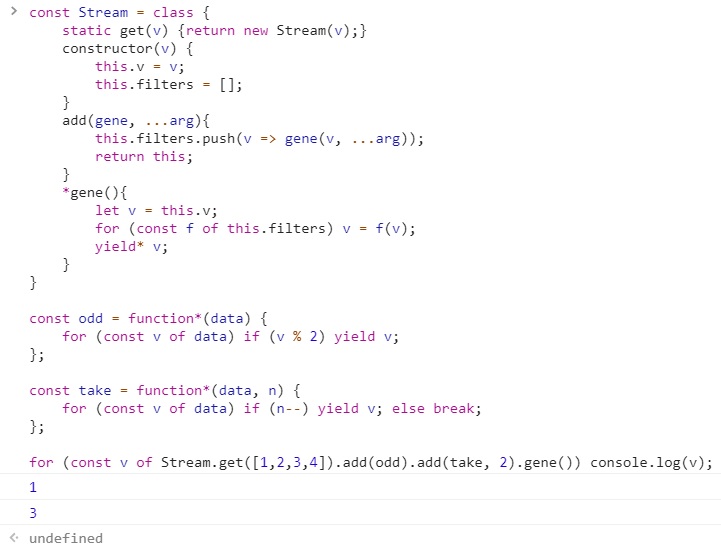
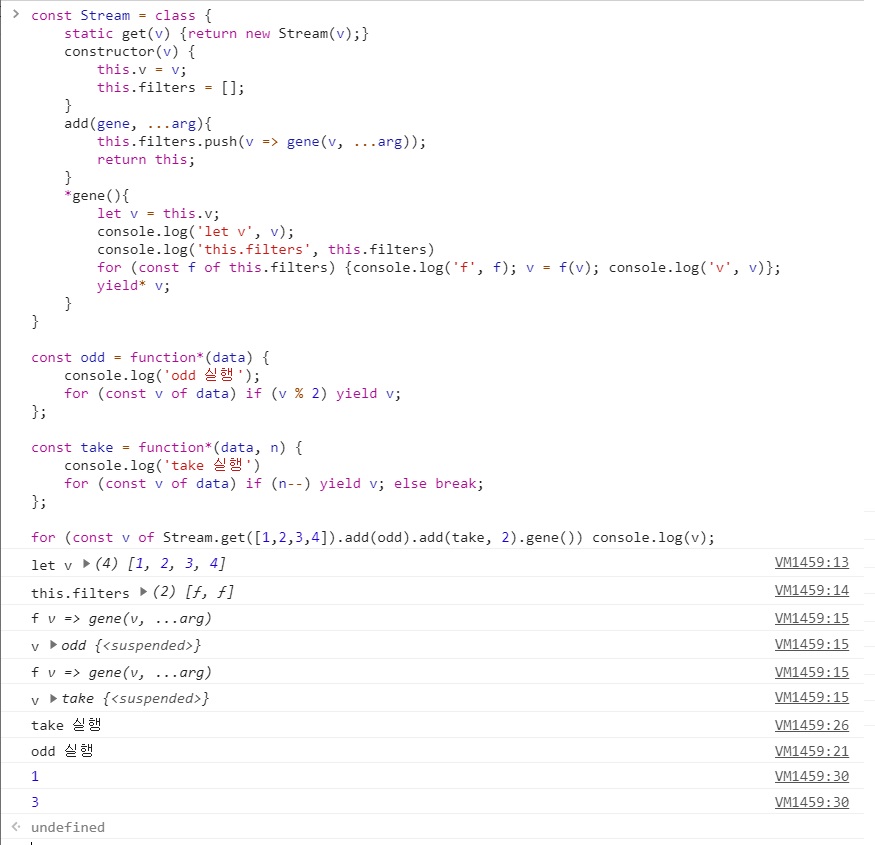
const Stream = class {
static get(v) {return new Stream(v);}
constructor(v) {
this.v = v;
this.filters = [];
}
add(gene, ...arg){
// v를 함수의 첫번째 인자값으로 전달 - 커링
// 제너레이터는 이터러블 객체를 반환할 수 있게 전달
this.filters.push(v => gene(v, ...arg));
return this;
}
*gene(){
let v = this.v;
for (const f of this.filters) v = f(v);
// v - 배열 갯수만큼 yield를 때림
yield* v;
}
}
const odd = function*(data) {
for (const v of data) if (v % 2) yield v;
};
const take = function*(data, n) {
for (const v of data) if (n--) yield v; else break;
};
// 아래 Stream.get은 별거 없다.
// 클래스 객체 생성할 때 new 때리기 싫어서 위에 보면 new Stream(v) 리턴한 것
// take 함수는 data와 n 인자값을 받는데, 아래 식에선 take 함수에 2라는 인자값 하나만 전달함.
// 그 이유는 위의 add 메소드에 v를 함수의 첫번째 인자값으로 전달하기 때문.
for (const v of Stream.get([1,2,3,4]).add(odd).add(take, 2).gene()) console.log(v);
루프 추상화 성공, for… of, rest, spread 등등 다 사용 가능
여러분들이 이제 odd나 take 같은 제너레이터 함수를 만들 수 있다.
커링
위에 식 안에 설명 참고.
지금까지 다룬 루프는 동기적 루프. 비교적 쉬운 편이다.
다음 시간에 배울 개념은, 동기적 / 비동기적, 블로킹 / 논블로킹 - 벌써 4가지 배울 것이 있다.
동기인데 블로킹 논블로킹, 비동기인데 블로킹 논블로킹..
Lazy Execution - 함수형식이 아닌, 코루틴이 있는 제너레이터니깐 이렇게 짧게 소스 작성이 가능. 함수형이면 이렇게 짧게 못짠다.