17.18 단어 경계 일치
단어 경계 일치는 매우 유용한 기능인데도 잘 사용하는 사람이 그리 많지 않은 것 같습니다.
단어 경계 메타 문자인 \b와 \B는 앵커와 마찬가지로 입력을 소비하지 않습니다.
곧 보겠지만, 입력을 소비하지 않는 것은 매우 유용한 특징입니다.
단어 경계는 알파벳 또는 숫자(\w)로 시작하는 부분, 알파벳이나 숫자가 아닌 문자(\W)로 끝나는 부분, 또는 문자열의 시작이나 끝에 일치합니다.
영어 텍스트 안에 들어있는 이메일 주소를 찾아서 하이퍼링크로 바꾼다고 합시다(이 예제에서는 이메일 주소가 글자로 시작하고 글자로 끝난다고 가정합니다).
경우의 수는 여러 가지가 있겠지만, 일단 다음과 같은 경우를 생각해 봅시다.
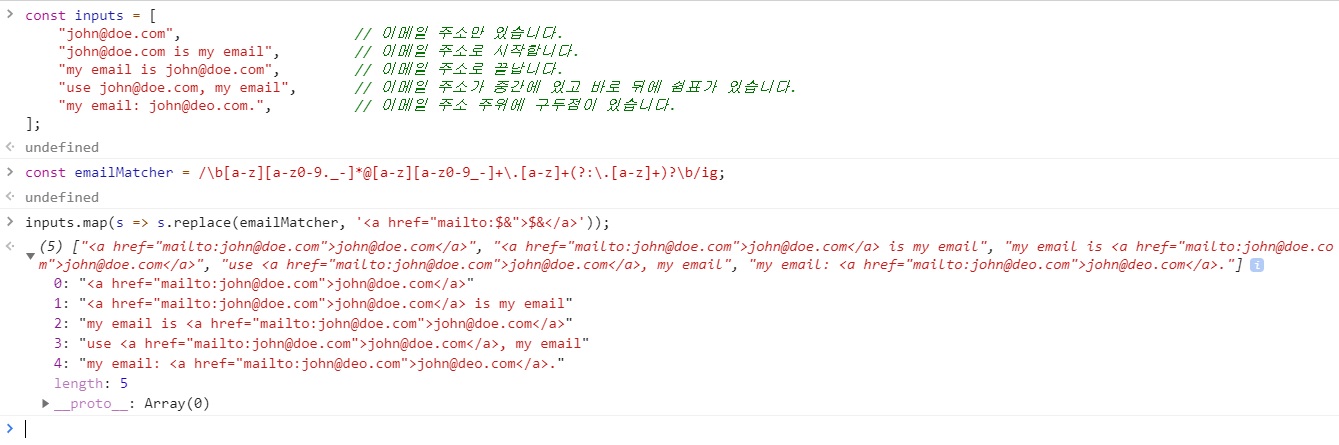
const inputs = [
"john@doe.com", // 이메일 주소만 있습니다.
"john@doe.com is my email", // 이메일 주소로 시작합니다.
"my email is john@doe.com", // 이메일 주소로 끝납니다.
"use john@doe.com, my email", // 이메일 주소가 중간에 있고 바로 뒤에 쉼표가 있습니다.
"my email: john@deo.com.", // 이메일 주소 주위에 구두점이 있습니다.
];
이들 이메일 주소의 공통점은 단어 경계 사이에 있다는 겁니다.
단어 경계는 입력을 소비하지 않으므로, 다시 말해 일치하는 이메일 주소인 john@doe.com에서
j가 보존되고 m 다음의 문자 역시 보존되므로 교체할 문자열에 ‘다시 넣는’ 방법을 생각할 필요가 없다는 장점이 있습니다.
const inputs = [
"john@doe.com", // 이메일 주소만 있습니다.
"john@doe.com is my email", // 이메일 주소로 시작합니다.
"my email is john@doe.com", // 이메일 주소로 끝납니다.
"use john@doe.com, my email", // 이메일 주소가 중간에 있고 바로 뒤에 쉼표가 있습니다.
"my email: john@deo.com.", // 이메일 주소 주위에 구두점이 있습니다.
];
const emailMatcher = /\b[a-z][a-z0-9._-]*@[a-z][a-z0-9_-]+\.[a-z]+(?:\.[a-z]+)?\b/ig;
inputs.map(s => s.replace(emailMatcher, '<a href="mailto:$&">$&</a>'));
// [
// '<a href="mailto:john@doe.com">john@doe.com</a>',
// '<a href="mailto:john@doe.com">john@doe.com</a> is my email',
// 'my email is <a href="mailto:john@doe.com">john@doe.com</a>',
// 'use <a href="mailto:john@doe.com">john@doe.com</a>, my email',
// 'my email: <a href="mailto:john@deo.com">john@deo.com</a>.'
// ]
이 정규식에는 단어 경계와 함께 이 장에서 배운 내용이 많이 들어 있습니다.
한 번에 이해되지 않을 수도 있지만, 자세히 살펴보면 정규식을 마스터하는 데 큰 도움이 될 겁니다.
특히, $& 주위의 문자가 소비되지 않았으므로 $&에 포함되지 않는다는 점을 잘 음미해 보십시오.
단어 경계는 특정 단어로 시작하거나, 특정 단어로 끝나거나, 특정 단어를 포함하는 텍스트를 찾을 때도 유용합니다.
예를 들어 /\bcount/는 count와 countdown을 찾지만, discount, recount, accountable은 찾지 못합니다.
/\bcount\B/는 countdown은 찾지만 count는 찾지 못합니다.
/\Bcount\b/는 discount와 recount같은 단어만 찾을 수 있고,
/\Bcount\B/는 accountable 같은 단어만 찾을 수 있습니다.