17.16 함수를 이용한 교체
함수를 이용하면 아주 복잡한 정규식을 좀 더 단순한 정규식으로 분할할 수 있어서 필자가 좋아하는 기능입니다.
이번에도 HTML 요소를 수정하는 예제를 사용하겠습니다.
<a> 태그를 정확한 규격에 맞도록 바꾸는 프로그램을 만든다고 합시다.
이 규격은 class, id, href 속성은 허용하지만 나머지 속성은 모두 제거합니다.
문제는, 원래 HTML이 어떻게 만들어져 있을지 짐작도 할 수 없다는 겁니다.
허용하는 속성이 항상 있다는 보장도 없고, 모두 있더라도 순서는 뒤죽박죽일 수 있습니다.
경우의 수는 아주 많지만, 일단 테스트할 문자열을 다음과 같이 만들었습니다.
const html =
`<a class="foo" href="/foo" id="foo">Foo</a>\n` +
`<A href='/bar' Class="bar">Bar</a>\n` +
`<a href="/baz">Baz</a>\n` +
`<a onclick="javascript:alert('qux!')" href="/qux">Qux</a>`;
테스트할 문자열을 보면 정규식만으로 해결하기는 어렵다는 걸 알 수 있을 겁니다.
경우의 수가 너무 많으니까요.
하지만 <a> 태그를 인식하는 정규식, 그리고 <a> 태그의 속성 중에서 필요한 것만 남기는 정규식 두 개를 쓰면 생각외로 훨씬 간단해집니다.
두 번째 정규식을 먼저 생각해 봅시다.
<a> 태그에서 class, id, href 속성을 제외한 모든 속성을 제거하는 것만 생각하면 문제는 훨씬 쉬워집니다.
정규식만 사용하면 속성의 순서 때문에 문제가 생길 수 있다는 건 앞에서 이미 봤습니다.
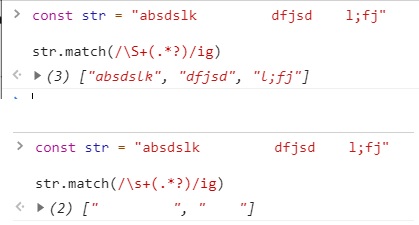
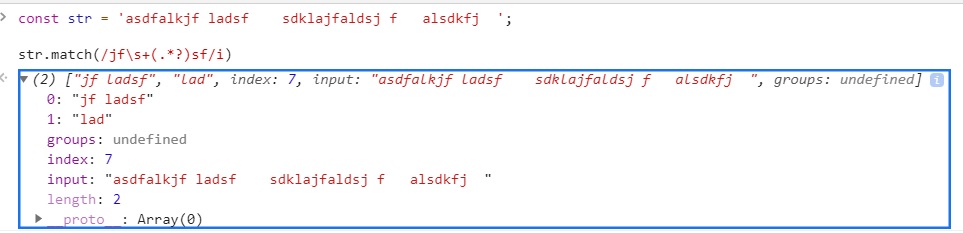
순서 문제를 해결하는 방법은 여러 가지가 있지만, 여기서는 String.prototype.split을 써서 한 번에 한 가지 속성만 체크하는 방법을 쓰겠습니다.
function sanitizeATag(aTag) {
// 태그에서 원하는 부분을 뽑아냅니다.
const parts = aTag.match(/<a\s+(.*?)>(.*?)<\/a>/i);
// parts[1]은 여는 <a> 태그에 들어있는 속성입니다.
// parts[2]는 <a>와 </a> 사이에 있는 텍스트입니다.
const attributes = parts[1]
// 속성을 분해합니다.
.split(/\s+/);
return '<a ' + attributes
// class, id, href 속성만 필요합니다.
.filter(attr => /^(?:class|id|href)[\s=]/i.test(attr))
// 스페이스 한 칸으로 구분해서 합칩니다.
.join(' ')
// 여는 <a> 태그를 완성합니다.
+ '>'
// 텍스트를 추가합니다.
+ parts[2]
// 마지막으로 태그를 닫습니다.
+ '</a>';
}
이 함수는 필요 이상으로 길긴 하지만, 명확히 이해할 수 있도록 나눠서 만들었습니다.
이 함수에도 정규식을 여러 개 썼습니다.
하나는 <a> 태그의 각 부분을 찾는데 썼고, 다른 하나는 하나 이상의 공백을 찾아 문자열을 분리하는 데 썼습니다.
마지막 하나는 우리가 원하는 속성만 남도록 필터하는 데 썼습니다.
마지막 하나는 우리가 원하는 속성만 남도록 필터하는 데 썼습니다.
정규식 하나로 이 일을 다 하려 했다면 훨씬 더 어려울 겁니다.
이제 흥미로운 부분입니다.
sanitizeATag 함수는 <a> 태그가 들어있는 HTML 블록에 사용하려고 만들었습니다.
<a> 태그를 찾은 정규식은 아주 쉽게 만들 수 있습니다.
const html =
`<a class="foo" href="/foo" id="foo">Foo</a>\n` +
`<A href='/bar' Class="bar">Bar</a>\n` +
`<a href="/baz">Baz</a>\n` +
`<a onclick="javascript:alert('qux!')" href="/qux">Qux</a>`;
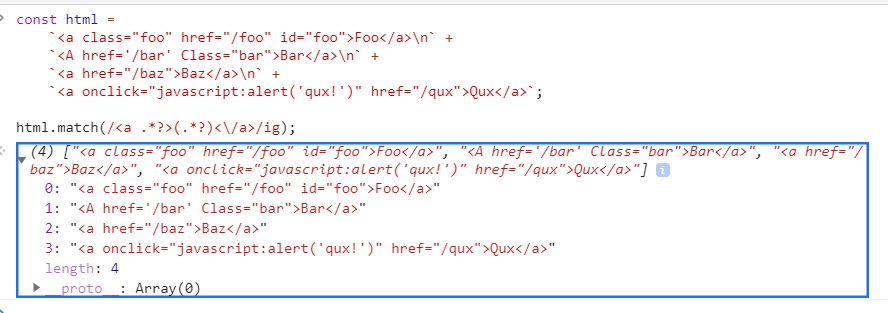
html.match(/<a .*?>(.*?)<\/a>/ig);
그런데 이걸 어떻게 써야 할까요?
String.prototype.replace에는 교체할 매개변수로 함수를 넘길 수 있습니다.
지금까지는 교체할 매개변수에 문자열만 썼지만, 함수를 사용하면 훨씬 자유롭게 바꿀 수 있습니다.
예제를 완성하기 전에 먼저 console.log()를 써서 어떻게 돌아가는지 알아보도록 합시다.
const html =
`<a class="foo" href="/foo" id="foo">Foo</a>\n` +
`<A href='/bar' Class="bar">Bar</a>\n` +
`<a href="/baz">Baz</a>\n` +
`<a onclick="javascript:alert('qux!')" href="/qux">Qux</a>`;
function sanitizeATag(aTag) {
// 태그에서 원하는 부분을 뽑아냅니다.
const parts = aTag.match(/<a\s+(.*?)>(.*?)<\/a>/i);
// parts[1]은 여는 <a> 태그에 들어있는 속성입니다.
// parts[2]는 <a>와 </a> 사이에 있는 텍스트입니다.
const attributes = parts[1]
// 속성을 분해합니다.
.split(/\s+/);
return '<a ' + attributes
// class, id, href 속성만 필요합니다.
.filter(attr => /^(?:class|id|href)[\s=]/i.test(attr))
// 스페이스 한 칸으로 구분해서 합칩니다.
.join(' ')
// 여는 <a> 태그를 완성합니다.
+ '>'
// 텍스트를 추가합니다.
+ parts[2]
// 마지막으로 태그를 닫습니다.
+ '</a>';
}
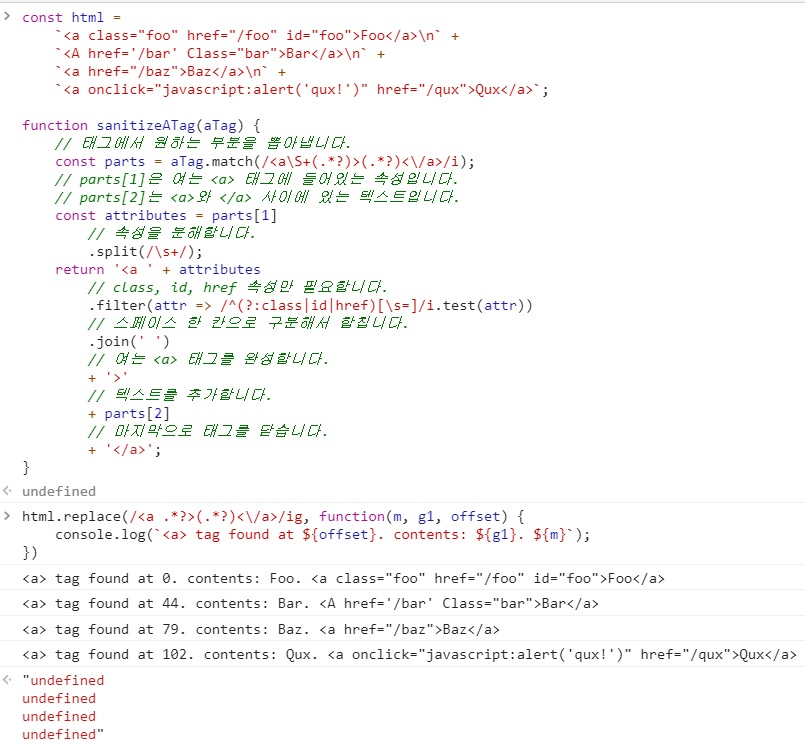
html.replace(/<a .*?>(.*?)<\/a>/ig, function(m, g1, offset) {
console.log(`<a> tag found at ${offset}. contents: ${g1}`);
})
String.prototype.replace에 넘기는 함수는 다음 순서대로 매개변수를 받습니다.
- m : 일치하는 문자열 전체(
$&와 같습니다.) - g1 : 일치하는 그룹(일치하는 것이 있다면), 일치하는 것이 여럿이라면 매개변수도 여러 개를 받습니다.
- offset : 원래 문자열에서 일치하는 곳의 오프셋(숫자)
- 원래 문자열(거의 사용하지 않습니다.)
String.prototype.replace는 함수가 반환하는 값을 써서 원래 문자열을 교체합니다.
지금 막 해본 예제에서는 콘솔에 출력할 뿐 아무것도 반환하지 않았으므로 undefined가 반환되고, String.prototype.replace는 undefined를 문자열로 바꿔서 사용합니다.
이 예제의 목적은 동작 방식을 이해하는 것이고 실제로 문자열을 교체하는 것은 아니니 결과로 나온 문자열을 사용하지 않았습니다.
그럼 이제 원래 예제로 돌아갑시다.
각 <a> 태그를 규격화하는 함수도 만들었고 HTML 블록에서 <a> 태그를 찾는 방법도 알고 있으니, 그 둘을 합치기만 하면 됩니다.
const html =
`<a class="foo" href="/foo" id="foo">Foo</a>\n` +
`<A href='/bar' Class="bar">Bar</a>\n` +
`<a href="/baz">Baz</a>\n` +
`<a onclick="javascript:alert('qux!')" href="/qux">Qux</a>`;
function sanitizeATag(aTag) {
// 태그에서 원하는 부분을 뽑아냅니다.
const parts = aTag.match(/<a\s+(.*?)>(.*?)<\/a>/i);
// parts[1]은 여는 <a> 태그에 들어있는 속성입니다.
// parts[2]는 <a>와 </a> 사이에 있는 텍스트입니다.
const attributes = parts[1]
// 속성을 분해합니다.
.split(/\s+/);
return '<a ' + attributes
// class, id, href 속성만 필요합니다.
.filter(attr => /^(?:class|id|href)[\s=]/i.test(attr))
// 스페이스 한 칸으로 구분해서 합칩니다.
.join(' ')
// 여는 <a> 태그를 완성합니다.
+ '>'
// 텍스트를 추가합니다.
+ parts[2]
// 마지막으로 태그를 닫습니다.
+ '</a>';
}
html.replace(/<a .*?>(.*?)<\/a>/ig, function(m) {
return sanitizeATag(m);
})

더 단순하게 만들 수도 있습니다.
sanitizeATag 함수는 String.prototype.replace에서 콜백 함수에 넘기는 매개변수를 그대로 받게 만들었으므로, 익명함수를 제거하고 sanitizeATag를 직접 써도 됩니다.
const html =
`<a class="foo" href="/foo" id="foo">Foo</a>\n` +
`<A href='/bar' Class="bar">Bar</a>\n` +
`<a href="/baz">Baz</a>\n` +
`<a onclick="javascript:alert('qux!')" href="/qux">Qux</a>`;
function sanitizeATag(aTag) {
// 태그에서 원하는 부분을 뽑아냅니다.
const parts = aTag.match(/<a\s+(.*?)>(.*?)<\/a>/i);
// parts[1]은 여는 <a> 태그에 들어있는 속성입니다.
// parts[2]는 <a>와 </a> 사이에 있는 텍스트입니다.
const attributes = parts[1]
// 속성을 분해합니다.
.split(/\s+/);
return '<a ' + attributes
// class, id, href 속성만 필요합니다.
.filter(attr => /^(?:class|id|href)[\s=]/i.test(attr))
// 스페이스 한 칸으로 구분해서 합칩니다.
.join(' ')
// 여는 <a> 태그를 완성합니다.
+ '>'
// 텍스트를 추가합니다.
+ parts[2]
// 마지막으로 태그를 닫습니다.
+ '</a>';
}
html.replace(/<a .*?>(.*?)<\/a>/ig, sanitizeATag)
이 방법을 사용하면 정말 여러 가지가 가능해집니다.
큰 문자열에서 작은 문자열을 찾고, 찾은 문자열을 가지고 어떤 작업을 해야 한다면 String.prototype.replace에 콜백 함수를 넘길 수 있다는 점을 기억하십시오.