17.13 소극적 일치, 적극적 일치
정규식 아마추어와 전문가를 가르는 기준은 소극적(lazy) 일치와 적극적(greedy) 일치의 차이를 이해하는가입니다.
역주_
적극적 일치와 소극적 일치를 각각 탐욕적 일치, 게으른 일치라고 번역한 책도 있습니다.
정규식은 기본적으로 적극적입니다.
검색을 멈추기 전에 일치하는 것을 최대한 많이 찾으려고 한다는 뜻입니다.
고전적인 예제를 하나 봅시다.
HTML 텍스트에서 <i> 태그를 <strong> 태그로 바꿔야 한다고 합시다.
우선 이렇게 해 볼 수 있습니다.
const input = "Regex pros know the difference between\n" +
"<i>greedy</i> and <i>lazy</i> matching.";
input.replace(/<i>(.*)<\/i>/g, '<strong>$1</strong>');
교체 문자열에 있는 $1는 .* 그룹에 일치하는 문자열로 바뀝니다.
.*는 () 소괄호 안에 쓰여져야합니다. 그래야 .* 그룹에 일치하는 문자열로 바뀝니다.
여기에 대해서는 나중에 더 설명합니다.
다음과 같이 직접 해 보십시오.
우리 의도와는 다른 결과가 나옵니다.

왜 이런 결과가 나왔는지 이해하려면 정규식 엔진이 동작하는 방법을 다시 떠올려야 할 겁니다.
정규식은 일치할 가능성이 있는 동안은 문자를 소비하지 않고 계속 넘어갑니다.
그리고 그 과정을 적극적으로 진행합니다.
정규식은 <i>를 만나면 </i>를 더는 찾을 수 없을 때까지 소비하지 않고 진행합니다.
원래 문자열에는 </i>가 두 개 있으므로, 정규식은 첫 번째 것을 무시하고 두 번째 것에서 일치한다고 판단합니다.
이 예제를 의도대로 실행되게 하는 방법은 여러 가지가 있지만, 지금은 소극적 일치와 적극적 일치에 대해 설명하고 있으므로 반복 메타 문자 *를 소극적으로 바꾸는 방법을 쓰겠습니다.
*뒤에 ?를 붙이면 소극적으로 검색합니다.
const input = "Regex pros know the difference between\n" +
"<i>greedy</i> and <i>lazy</i> matching.";
input.replace(/<i>(.*?)<\/i>/ig, '<strong>$1</strong>');
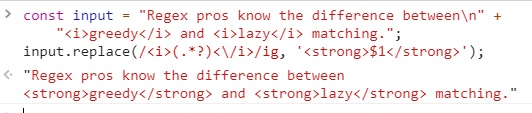
이 정규식은 * 메타 문자 다음의 물음표를 빼면 앞의 정규식과 완전히 똑같습니다.
이제 정규식 엔진은 </i>를 보는 즉시 일치하는 것을 찾았다고 판단합니다.
따라서 </i>를 발견할 때마다 그때까지 찾은 것을 소비하고, 일치하는 범위를 넓히려 하지 않습니다.
우리는 보통 소극적이라는 말을 부정적인 의미로 사용하지만 여기서는 우리가 원하는 것에 딱 맞게 동작합니다.
반복 메타 문자 *, +, ?, {n}, {n,}, {n,m} 뒤에는 모두 물음표를 붙일 수 있지만, 필자는 *와 + 외에는 물음표를 붙여서 쓴 일이 없습니다.