17.7 HTML 찾기
이전 예제에서는 HTML 태그를 찾았는데, 이건 정규식으로 매우 자주 하는 일 중 하나입니다.
자주 하는 일이긴 하지만 반드시 짚고 넘어가야 할 것이 있습니다.
정규식으로는 HTML을 분석(parse) 할 수 없습니다.
무언가를 분석하려면 각 부분을 구성 요소로 완전히 분해할 수 있어야 합니다.
정규식은 아주 간단한 언어만 분석할 수 있습니다.
물론 정규식을 써서 복잡한 언어를 분석하는 사례가 자주 있지만, 정규식의 한계를 이해하고 상황에 따라 더 알맞은 방법을 찾아야 합니다.
정규식을 HTML에 유용하게 쓸 수 있는 것은 사실이지만 완벽하게 분석하는 것은 불가능합니다.
정규식을 어떻게 만들든 분석할 수 없는 HTML이 항상 존재합니다.
100% 동작하는 것이 필요하다면 전용 파서를 찾아야 할 겁니다.
다음 예제를 보십시오.
const html = '<br> [!CDATA[[<br> ]]';
const matches = html.match(/<br>/ig);
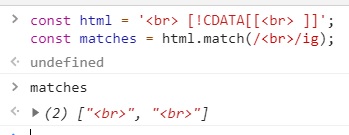
이 정규식은 두 번 일치하지만, 이 예제에서 진짜 <br> 태그는 하나뿐입니다.
다른 하나는 HTML이 아닌 글자 데이터(CDATA)입니다.
정규식은 <p> 태그 안에 <a> 태그가 존재하는 것 같은 계층적 구조에 매우 취약합니다.
이런 한계를 이론적으로 설명하는 건 이 책의 범위를 벗어납니다.
다시 말하지만, 정규식은 HTML 처럼 매우 복잡한 것을 검색하기에는 알맞지 않습니다.